環境資訊中心綜合外電;鄒敏惠編譯、許芷榕審校
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
※評比南投搬家公司費用收費行情懶人包大公開
北部有線電視-提供穩定的寬頻光纖上網、高畫質HD數位頻道、第四台電視、數位電視,現在申辦免費體驗3個月"HD99高畫質套餐"
環境資訊中心綜合外電;鄒敏惠編譯、許芷榕審校
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
※評比南投搬家公司費用收費行情懶人包大公開
摘錄自2020年2月6日星島日報報導
印度孟買警方提出一項具有創意的計畫,藉以減少該市的噪音污染。如果駕駛人士響按造成大量噪音,交通燈會自動作出調整,延遲由紅燈轉成綠燈,令司機等得更久才可開車。
孟買警方於去年11月和12月推行這項試驗計畫,在交通燈燈柱上安裝量度聲音分貝的儀器。如果儀器錄得汽車響按製造出來的噪音達85分貝或以上,交通燈會延遲由紅燈轉成綠燈。
警方發言人說,在市內幾個繁忙的道路交匯處安裝這套裝置,每天試驗15分鐘。當局會於下月起擴大這項計畫,在市內10處地點進行試驗。如果試驗成功,會在整個交通管理系統內實行。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家費用,距離,噸數怎麼算?達人教你簡易估價知識!
摘錄自2020年2月5日民視報導
日本農林水產省表示,要避免非洲豬瘟入境,危害日本養豬和肉品產業,便考慮大幅提高非法攜帶肉品入境的罰則,個人違規將從原本的100萬日圓,提高到300萬日圓,相當於台幣84萬。
而公司法人還一口氣提高50倍,將罰5000萬日圓,約台幣1400萬,相關法案預計在這次會期,提交國會審議。日本海關光是去年10~12月,沒收的違規肉品當中,就有86件驗出非洲豬瘟,當中甚至有部分病毒,仍具有傳染力。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※南投搬家前需注意的眉眉角角,別等搬了再說!
摘錄自2020年2月6日星島日報報導
土耳其東部連續第二日發生雪崩,導致最少38人死亡,多人被活埋。
事發在當地周二(4日)晚,鄰近伊朗邊境的東部邊境凡省的山區發生雪崩,當時一架剷雪車及一架小巴被埋,造成至少五人死亡,兩人失蹤。當局派出300名救援人員周三中午到場尋找失蹤者,卻遭遇第二次雪崩。
當局指事件合共有38人喪生,多人被活埋。當中包括軍人、警察、消防員和志願者。另外有53人受傷,仍有多人被埋在雪下。當地政府指已救出25個被埋的救援人員,但無交代他們的情況。目前仍有超過50人可能被困,警告死傷人數可能增加。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
CSS有三模塊:盒子模型、浮動 、定位。上篇博客有講到 盒子模型地址:
概念 浮動可以理解為讓某個div元素脫離標準流,漂浮在標準流之上,和標準流不是一個層次。
如果是第一次聽說肯定還是還是一臉懵,下面我一步一步通過例子來解釋這句話。
舉例說明
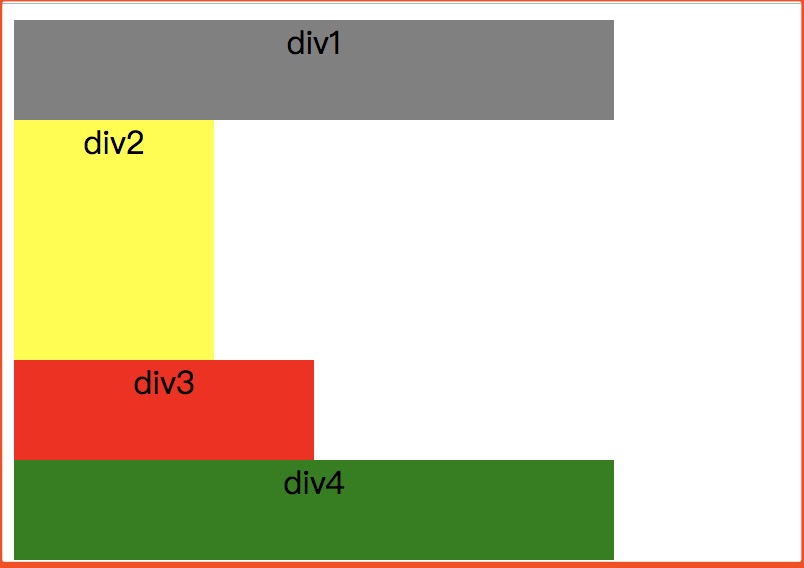
我們知道div是塊級元素,在頁面中獨佔一行,自上而下排列,也就是傳說中的標準流。
如下圖
可以看出,因為div是塊級元素,所以即使div2的寬度很小,頁面中一行可以容下div2和div3,div3也不會排在div2後邊,因為div元素是獨佔一行的。
那麼我們再看下浮動的作用,這裏我將div2浮動(對div2添加float:left;左浮動屬性)
刷新頁面
通過上下兩張圖片對比,我們可以直觀感覺到,div2有種浮起來的感覺,從之前的平面到立體的感覺。也因為div2浮起來了,那麼它之前所佔的位置也就空出來了,
那麼div3和div4就可以佔據之前div2的位置,所以它們都往上移動了。這樣我們最終看到的效果就是div2和div3,div4有重疊,而且div2是在最上層。
那如果這是我在把div3也設置左浮動呢 (對div3添加float:left;左浮動屬性)
再次刷新頁面
同樣我們可以很直觀的看到,因為div2和div3目前都是左浮動,所以它們的位置都空出來了,這個時候div4就可以往上移動,所以div2和div3都把div4部分給覆蓋了。
通過上面示例,我們應該可以理解什麼是浮動。這裏附上上面示例的代碼,可以自行再研究下
<!DOCTYPE html>
<html>
<head>
<title>css浮動</title>
<style type="text/css">
div {
text-align: center;
}
.one {
background-color: gray;
width: 300px;
height: 50px;
}
.two {
background-color: yellow;
width: 100px;
height: 120px;
/*float:left;*/
}
.three {
background-color: red;
width: 150px;
height: 50px;
/*float:left;*/
}
.four {
background-color: green;
width: 300px;
height: 50px;
}
</style>
</head>
<body>
<div class="one"> div1</div>
<div class="two"> div2</div>
<div class="three">div3 </div>
<div class="four"> div4</div>
</body>
</html>通過上面也可以得出一些結論:
1、假如某個div元素A是浮動的,如果A元素上一個元素也是浮動的,那麼A元素會跟隨在上一個元素的後邊(如果一行放不下這兩個元素,那麼A元素會被擠到下一行);
2、如果A元素上一個元素是標準流中的元素,那麼A的相對垂直位置不會改變,也就是說A的頂部總是和上一個元素的底部對齊。
浮動它主要有兩個作用:1、實現文本圍繞效果。2、實現塊級元素在一行显示布局。
1)實現文本圍繞效果
示例
<!DOCTYPE html>
<html>
<head>
<title>css浮動</title>
<style type="text/css">
.father {
border: 3px solid #005588;
padding: 1px;
width: 300px;
}
img {
width: 150px;
height: 150px;
float:left;
}
</style>
</head>
<body>
<div class = "father">
<img src="1.jpeg"/>
這件衣服價值百萬,奢侈品牌是指服務於奢侈品的品牌。它是品牌等級分類中的最高等級品牌。在生活當中,奢侈品牌享有很特殊的市場和很高的社會地位。在商品分類里,與奢侈品相對應的是大眾商品。奢侈品不僅是提供使用價值的商品,更是提供高附加值的商品。
</div>
</body>
</html>運行結果
2)實現塊級元素在一行显示布局
現在很多時候會通過浮動,讓多個div實現一行显示。當然當我們沒有了解浮動之前我們可以通過將塊級元素轉換為行內塊級元素來實現(display: inline-block)。
如圖
這樣確實可以將多個div實現在同一行显示。但這裡會有兩個小問題
1、我們可以看到div之前會有小縫隙,很難去除。
2、如果我想讓其中一個div显示在最右邊,實現起來會比較麻煩。而上面兩個問題可以通過浮動很輕易的解決。
示例
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>cssdiv元素局一行</title>
<style>
div {
display: inline-block;
width: 120px;
height: 80px;
/*float: left;*/
}
.one {
background-color: pink;
}
.two {
background-color: purple;
}
.three {
background-color: red;
/*float: right;*/
}
</style>
</head>
<body>
<div class="one">div1</div>
<div class="two">div2</div>
<div class="three">div3</div>
</body>
</html>運行結果
很明顯已經解決。
在 CSS 中,我們通過 float 屬性實現元素的浮動。float 屬性定義元素在哪個方向浮動。
基本語法格式
選擇器 {float:屬性值;}屬性值
浮動脫離標準流,不佔位置,會影響標準流。浮動只有左右浮動。
注意 浮動的元素總是找理它最近的父級元素對齊。但是不會超出內邊距的範圍。
如圖
浮動特性
1、浮動脫離標準流,不佔位置,會影響標準流。浮動只有左右浮動。
2、加了浮動的元素盒子是浮起來的,漂浮在其他的標準流盒子上面。
3、加了浮動的盒子,不佔位置的,它浮起來了,它原來的位置會給後面標準流的盒子。
4、一個父盒子裏面的子盒子,如果其中一個子級有浮動的,則其他子級都需要浮動。這樣才能一行對齊显示。
5、元素添加浮動后,元素會具有行內塊元素的特性。元素的大小完全取決於定義的大小或者默認的內容多少浮動根據元素書寫的位置來显示相應的浮動。
6、假如在一行之上只有極少的空間可供浮動元素,那麼這個元素會跳至下一行,這個過程會持續到某一行擁有足夠的空間為止。總結 浮動的目更多的是為了讓多個塊級元素同一行上显示。
1、
2、
3、
4、
你如果願意有所作為,就必須有始有終。(8)本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
以前學Java的時候,和Spring全家桶打好關係就行了,從Spring、Spring MVC到SpringBoot,一脈相承。
對於一個Web項目,使用Spring MVC,就可以基於MVC的思想開發項目了,不管是應對前後端分離還是不分離的場景,你都可以輕鬆駕馭。因為你只要知道,你用的是一個Web開發框架就行了。
相比於Spring在Java一家獨大的局面,Go生態中的Web框架還在百家爭鳴的階段。從今天開始學習一款基於Go語言開發的Web開發框架Gin。
Github:https://github.com/gin-gonic/gin
語言:Go語言
官網:https://gin-gonic.com/
Go版本:1.12.4
系統:macOS
依賴管理工具:go mod
IDE:Goland
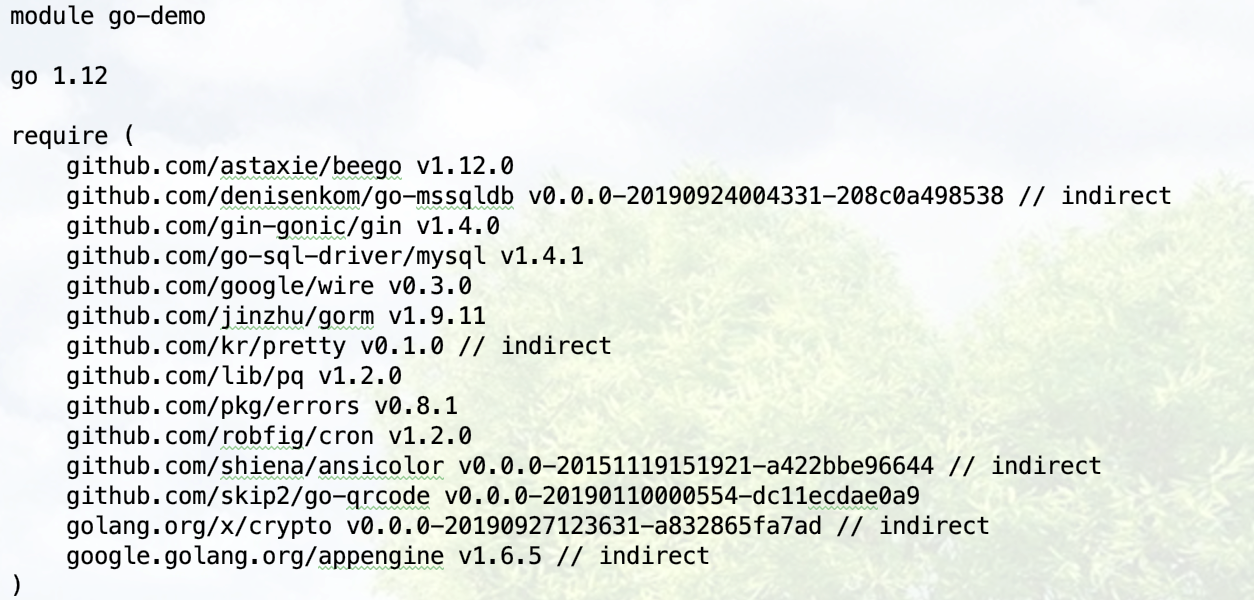
因為我使用了go mod,所以引用gin的依賴算是很方便了。
如何創建一個go mod管理的新項目以及如何將老項目改造為go mod,可以參見這篇文章:https://juejin.im/post/5c8e503a6fb9a070d878184a,寫的很詳細了。
這就是我的go-demo:https://github.com/DMinerJackie/go-demo項目的所有第三方依賴了。
那麼如何添加gin的依賴呢?有以下三種方式
直接新建一個基於gin的example程序文件,然後執行 go build xxx.go或者 go run xxx.go命令,go mod就會自動幫你下載gin依賴並更新go.mod文件。
同上,還是新建一個example程序文件,然後在項目根目錄下執行 go mod tidy命令,go mod會幫你安排上。這個命令可以幫助你移除不需要的依賴,並拉取引用你需要的依賴。
在go.mod文件中手動添加依賴類似 github.com/gin-gonic/gin v1.4.0這種。
幾乎不用什麼繁瑣的步驟,就完成了環境搭建。下面開始寫第一個基於Gin的demo
1、新建文件helloworld.go
package main
import "github.com/gin-gonic/gin"
func main() {
r := gin.Default()
r.GET("/ping", func(c *gin.Context) {
c.JSON(200, gin.H{
"message": "pong",
})
})
r.Run() // 監聽並在 0.0.0.0:8080 上啟動服務
}
2、點擊執行該程序
從控制台程序可以看出服務已經啟動,並且開始監聽8080端口
3、訪問接口
接下來我們在瀏覽器輸入localhost:8080/ping即可看到程序返回的結果
一個極簡的Web服務器就這樣搭建完成並對外訪問了。
上面的代碼中
通過 r:=gin.Default()聲明一個gin的引擎,後續的操作都是基於這個引擎的。
通過 r.GET申明一個可以訪問的路由,定義的HTTP請求方式為GET請求。同時定義了請求后對應的處理方式,即一個閉包函數聲明以JSON格式返回的鍵值對。
通過 r.Run()監聽指定端口並啟動服務
1、渲染HTML
雖然現在很多都倡導並實行前後端分離了,即後端只提供HTTP接口,前端負責調用HTTP接口以及頁面渲染。
但還是有前後端揉在一起的使用場景,gin就提供了這種能力。
具體的做法是提供一個HTML模板,服務端將得到的數據填充到模板中實現頁面的渲染。
import (
"github.com/gin-gonic/gin"
"net/http"
)
func main() {
router := gin.Default()
router.LoadHTMLGlob("main/src/gin-example/examples/templates/**/*")
router.GET("/posts/index", func(c *gin.Context) {
c.HTML(http.StatusOK, "posts/index.tmpl", gin.H{
"title": "Posts",
})
})
router.GET("/users/index", func(c *gin.Context) {
c.HTML(http.StatusOK, "users/index.tmpl", gin.H{
"title": "Users",
})
})
router.Run(":8080")
}
index.tmpl
{{ define "posts/index.tmpl" }}
<html><h1>
{{ .title }}
</h1>
<p>Using posts/index.tmpl</p>
</html>
{{ end }}
user.tmpl
{{ define "users/index.tmpl" }}
<html><h1>
{{ .title }}
</h1>
<p>Using users/index.tmpl</p>
</html>
{{ end }}
對應的HTML模板文件目錄結構如下
代碼部分
router.LoadHTMLGlob用於指明HTML模板文件的路徑
router.GET同上,定義訪問路由和返回結果,不同於第一個Demo的是,這裡有賦值填充的過程,比如
c.HTML(http.StatusOK, "posts/index.tmpl", gin.H{
"title": "Posts",
})
將index.tmpl中定義的 .title替換為”Posts”
執行結果如下
2、PureJSON
func main() {
r := gin.Default()
// 提供 unicode 實體
r.GET("/json", func(c *gin.Context) {
c.JSON(200, gin.H{
"html": "<b>Hello, 世界!</b>",
})
})
// 提供字面字符
r.GET("/purejson", func(c *gin.Context) {
c.PureJSON(200, gin.H{
"html": "<b>Hello, 世界!</b>",
})
})
// 監聽並在 0.0.0.0:8080 上啟動服務
r.Run(":8080")
}
這裏兩個GET方法唯一不同的就是要渲染的內容一個使用JSON()方法一個使用PureJSON()方法。
啟動程序后,我們看下訪問結果有什麼不同
可以看出JSON()渲染的會有中文以及標籤轉為unicode編碼,但是使用PureJSON()渲染就是原樣輸出(我的瀏覽器裝了插件,會自動解碼,所以不點擊右邊的”RAW“兩個接口返回的結果是一樣的)。
這個問題,本周我們服務端在和客戶端對接的時候還遇到了,因為框架返回的JSON串就是經過編碼的,但是單獨請求放到瀏覽器是沒有問題的,客戶端收到的卻是經過編碼的,最後排查發現是瀏覽器插件解碼了。
3、渲染多種數據交換格式的數據
gin支持渲染XML、JSON、YAML和ProtoBuf等多種數據格式
import (
"github.com/gin-gonic/gin"
"github.com/gin-gonic/gin/testdata/protoexample"
"net/http"
)
func main() {
r := gin.Default()
// gin.H 是 map[string]interface{} 的一種快捷方式
r.GET("/someJSON", func(c *gin.Context) {
c.JSON(http.StatusOK, gin.H{"message": "hey", "status": http.StatusOK})
})
r.GET("/moreJSON", func(c *gin.Context) {
// 你也可以使用一個結構體
var msg struct {
Name string `json:"user"`
Message string
Number int
}
msg.Name = "Lena"
msg.Message = "hey"
msg.Number = 123
// 注意 msg.Name 在 JSON 中變成了 "user"
// 將輸出:{"user": "Lena", "Message": "hey", "Number": 123}
c.JSON(http.StatusOK, msg)
})
r.GET("/someXML", func(c *gin.Context) {
c.XML(http.StatusOK, gin.H{"message": "hey", "status": http.StatusOK})
})
r.GET("/someYAML", func(c *gin.Context) {
c.YAML(http.StatusOK, gin.H{"message": "hey", "status": http.StatusOK})
})
r.GET("/someProtoBuf", func(c *gin.Context) {
reps := []int64{int64(1), int64(2)}
label := "test"
// protobuf 的具體定義寫在 testdata/protoexample 文件中。
data := &protoexample.Test{
Label: &label,
Reps: reps,
}
// 請注意,數據在響應中變為二進制數據
// 將輸出被 protoexample.Test protobuf 序列化了的數據
c.ProtoBuf(http.StatusOK, data)
})
// 監聽並在 0.0.0.0:8080 上啟動服務
r.Run(":8080")
}
今天先到這,後面再看看gin的源碼。
如果您覺得閱讀本文對您有幫助,請點一下“推薦”按鈕,您的“推薦”將是我最大的寫作動力!如果您想持續關注我的文章,請掃描二維碼,關注JackieZheng的微信公眾號,我會將我的文章推送給您,並和您一起分享我日常閱讀過的優質文章。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想要讓你的商品成為最夯、最多人討論的話題?網頁設計公司讓你強力曝光
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
文章基本是官網內容的翻譯,英文不錯的同學可點擊上面的鏈接直接看英文文檔。
JWT全稱是JSON Web Token(JWT)是一個開放標準(RFC 7519),它定義了一種緊湊且自包含的方式,用於在各方之間作為JSON對象安全地傳輸信息。由於此信息是經過数字簽名的,因此可以被驗證和信任。
可以使用密鑰(HMAC算法)或使用RSA或ECDSA的公用/專用密鑰對對JWT進行簽名。
(Authorization)JWT的最常見情況。一旦用戶登錄,每個後續請求將包括JWT,從而允許用戶訪問該令牌允許的路由,服務和資源。單一登錄是當今廣泛使用JWT的一項功能,因為它的開銷很小並且可以在不同的域中輕鬆使用。(Information Exchange)JWT是在各方之間安全地傳輸信息的好方法。因為可以對JWT進行簽名(例如,使用公鑰/私鑰對),所以您可以確保發件人是他們所說的人。另外,由於簽名是使用Header和payload計算的,因此您還可以驗證內容是否未被篡改。由三部分組成,這些部分由點.分隔,分別是:
HeaderPayloadSignature因此,JWT通常如下所示。
xxxxx.yyyyy.zzzzz通常由兩部分組成:
JWT)例如:
{
"alg": "HS256",
"typ": "JWT"
}然後,將此JSON通過Base64Url編碼以形成JWT的第一部分。
令牌的第二部分是有效負載,其中包含聲明。聲明是有關實體(通常是用戶)和其他數據的聲明。共有三種類型的索賠: registered、public、private claims
Registered claimsiss(發出者),exp(到期時間),sub(主題),aud(受眾) 等。JWT是緊湊的。Public claimsJWT的人員隨意定義。但是為避免衝突,應在IANA JSON Web令牌註冊表中定義它們,或將其定義為包含抗衝突名稱空間的URI。Private claims有效負載示例:
{
"sub": "1234567890",
"name": "John Doe",
"admin": true
}同樣需要Base64Url編碼,以形成JWT的第二部分。
簽名(Signature)用於驗證消息在整個過程中沒有更改,並且對於使用私鑰進行簽名的令牌,它還可以驗證JWT的發送者是它所說的真實身份。
例如,如果要使用HMAC SHA256算法,則將通過以下方式創建簽名:
HMACSHA256(
base64UrlEncode(header) + "." +
base64UrlEncode(payload),
secret)輸出是三個由.分隔的Base64-URL字符串,可以在HTML和HTTP環境中輕鬆傳遞這些字符串,與基於XML的標準(例如SAML)相比,它更緊湊。
下圖显示了一個JWT,它已對先前的Header和Payload進行了編碼,並用一個Signature。
可以在這個網頁 驗證和生成JWT
在身份驗證中,當用戶使用其憑據成功登錄時,將返回令牌。由於令牌是憑據,因此必須格外小心以防止安全問題。通常,令牌的有效時間不宜設置過長。
Tip: 由於缺乏安全性,您也不應該將敏感的會話數據存儲在瀏覽器存儲中。
每當用戶想要訪問受保護的路由或資源時,用戶代理通常應在Bearer模式中使用授權頭髮送JWT。Header的內容應如下所示:
Authorization: Bearer <token>在某些情況下,接口訪問並不需要身份授權。服務器的受保護路由將在Authorization Header中檢查JWT令牌是否有效,如果存在且有效,則將允許用戶訪問受保護的資源。
如果JWT包含必要的數據,則可以減少查詢數據庫中某些操作的需求。
如果令牌是在Authorization Header中發送的,則跨域資源共享 不會成為問題,因為它不使用cookie。
下圖显示了如何獲取JWT並將其用於訪問API或資源:
JWT令牌。JWT令牌是否有效,返回對應結果給客戶端下圖詳細的流程:
ps:請注意,使用簽名令牌,令牌或令牌中包含的所有信息都會暴露給用戶或其他方,即使他們無法更改它。這意味着您不應將機密信息放入令牌中。
對比 Simple Web Tokens (SWT) 和Security Assertion Markup Language Tokens (SAML),看看使用JSON Web Tokens (JWT) 有什麼好處。
JSON不如XML冗長,因此在編碼時JSON的大小也較小,從而使JWT比SAML更緊湊。這使得JWT是在HTML和HTTP環境中傳遞的不錯的選擇。SWT只能使用HMAC算法進行對稱簽名。但是JWT和SAML令牌可以使用X.509證書形式的公用/專用密鑰對進行簽名。與簽名JSON的簡單性相比,使用XML Digital Signature簽名XML而不引入模糊的安全漏洞是非常困難的。JSON解析器在大多數編程語言中都很常見,因為它們直接映射到對象。相反,XML沒有自然的文檔到對象映射。與SAML斷言相比,這使使用JWT更加容易。JWT是在Internet規模上使用的。這強調了在多個平台(尤其是移動平台)上對JSON Web令牌進行客戶端處理的簡便性。如果您想了解有關JSON Web令牌的更多信息,甚至開始使用它們在自己的應用程序中執行身份驗證,請瀏覽到 頁面。
諮詢請加微信:輕撩即可。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
※評比南投搬家公司費用收費行情懶人包大公開
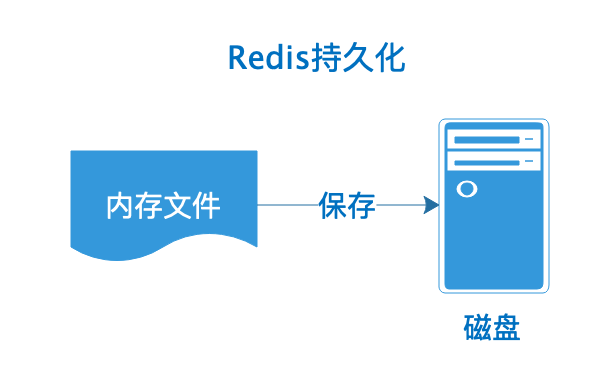
Redis 的讀寫都是在內存中,所以它的性能較高,但在內存中的數據會隨着服務器的重啟而丟失,為了保證數據不丟失,我們需要將內存中的數據存儲到磁盤,以便 Redis 重啟時能夠從磁盤中恢復原有的數據,而整個過程就叫做 Redis 持久化。
Redis 持久化也是 Redis 和 Memcached 的主要區別之一,因為 Memcached 是不具備持久化功能的。
Redis 持久化擁有以下三種方式:
因為每種持久化方案,都有特定的使用場景,讓我們先從 RDB 持久化說起吧。
RDB(Redis DataBase)是將某一個時刻的內存快照(Snapshot),以二進制的方式寫入磁盤的過程。
RDB 的持久化觸發方式有兩類:一類是手動觸發,另一類是自動觸發。
手動觸發持久化的操作有兩個: save 和 bgsave ,它們主要區別體現在:是否阻塞 Redis 主線程的執行。
在客戶端中執行 save 命令,就會觸發 Redis 的持久化,但同時也是使 Redis 處於阻塞狀態,直到 RDB 持久化完成,才會響應其他客戶端發來的命令,所以在生產環境一定要慎用。
save 命令使用如下:
從圖片可以看出,當執行完 save 命令之後,持久化文件 dump.rdb 的修改時間就變了,這就表示 save 成功的觸發了 RDB 持久化。
save 命令執行流程,如下圖所示:
bgsave(background save)既後台保存的意思, 它和 save 命令最大的區別就是 bgsave 會 fork() 一個子進程來執行持久化,整個過程中只有在 fork() 子進程時有短暫的阻塞,當子進程被創建之後,Redis 的主進程就可以響應其他客戶端的請求了,相對於整個流程都阻塞的 save 命令來說,顯然 bgsave 命令更適合我們使用。
bgsave 命令使用,如下圖所示:
bgsave 執行流程,如下圖所示:
說完了 RDB 的手動觸發方式,下面來看如何自動觸發 RDB 持久化?
RDB 自動持久化主要來源於以下幾種情況。
save m n 是指在 m 秒內,如果有 n 個鍵發生改變,則自動觸發持久化。
參數 m 和 n 可以在 Redis 的配置文件中找到,例如,save 60 1 則表明在 60 秒內,至少有一個鍵發生改變,就會觸發 RDB 持久化。
自動觸發持久化,本質是 Redis 通過判斷,如果滿足設置的觸發條件,自動執行一次 bgsave 命令。
注意:當設置多個 save m n 命令時,滿足任意一個條件都會觸發持久化。
例如,我們設置了以下兩個 save m n 命令:
當 60s 內如果有 10 次 Redis 鍵值發生改變,就會觸發持久化;如果 60s 內 Redis 的鍵值改變次數少於 10 次,那麼 Redis 就會判斷 600s 內,Redis 的鍵值是否至少被修改了一次,如果滿足則會觸發持久化。
flushall 命令用於清空 Redis 數據庫,在生產環境下一定慎用,當 Redis 執行了 flushall 命令之後,則會觸發自動持久化,把 RDB 文件清空。
執行結果如下圖所示:
在 Redis 主從複製中,當從節點執行全量複製操作時,主節點會執行 bgsave 命令,並將 RDB 文件發送給從節點,該過程會自動觸發 Redis 持久化。
合理的設置 RDB 的配置,可以保障 Redis 高效且穩定的運行,下面一起來看 RDB 的配置項都有哪些?
RDB 配置參數可以在 Redis 的配置文件中找見,具體內容如下:
# RDB 保存的條件
save 900 1
save 300 10
save 60 10000
# bgsave 失敗之後,是否停止持久化數據到磁盤,yes 表示停止持久化,no 表示忽略錯誤繼續寫文件。
stop-writes-on-bgsave-error yes
# RDB 文件壓縮
rdbcompression yes
# 寫入文件和讀取文件時是否開啟 RDB 文件檢查,檢查是否有無損壞,如果在啟動是檢查發現損壞,則停止啟動。
rdbchecksum yes
# RDB 文件名
dbfilename dump.rdb
# RDB 文件目錄
dir ./其中比較重要的參數如下列表:
① save 參數
它是用來配置觸發 RDB 持久化條件的參數,滿足保存條件時將會把數據持久化到硬盤。
默認配置說明如下:
② rdbcompression 參數
它的默認值是 yes 表示開啟 RDB 文件壓縮,Redis 會採用 LZF 算法進行壓縮。如果不想消耗 CPU 性能來進行文件壓縮的話,可以設置為關閉此功能,這樣的缺點是需要更多的磁盤空間來保存文件。
③ rdbchecksum 參數
它的默認值為 yes 表示寫入文件和讀取文件時是否開啟 RDB 文件檢查,檢查是否有無損壞,如果在啟動是檢查發現損壞,則停止啟動。
Redis 中可以使用命令查詢當前配置參數。查詢命令的格式為:config get xxx ,例如,想要獲取 RDB 文件的存儲名稱設置,可以使用 config get dbfilename ,執行效果如下圖所示:
查詢 RDB 的文件目錄,可使用命令 config get dir ,執行效果如下圖所示:
設置 RDB 的配置,可以通過以下兩種方式:
config set dir "/usr/data" 就是用於修改 RDB 的存儲目錄。注意:手動修改 Redis 配置文件的方式是全局生效的,即重啟 Redis 服務器設置參數也不會丟失,而使用命令修改的方式,在 Redis 重啟之後就會丟失。但手動修改 Redis 配置文件,想要立即生效需要重啟 Redis 服務器,而命令的方式則不需要重啟 Redis 服務器。
小貼士:Redis 的配置文件位於 Redis 安裝目錄的根路徑下,默認名稱為 redis.conf。
當 Redis 服務器啟動時,如果 Redis 根目錄存在 RDB 文件 dump.rdb,Redis 就會自動加載 RDB 文件恢復持久化數據。
如果根目錄沒有 dump.rdb 文件,請先將 dump.rdb 文件移動到 Redis 的根目錄。
驗證 RDB 文件是否被加載
Redis 在啟動時有日誌信息,會显示是否加載了 RDB 文件,我們執行 Redis 啟動命令:src/redis-server redis.conf ,如下圖所示:
從日誌上可以看出, Redis 服務在啟動時已經正常加載了 RDB 文件。
小貼士:Redis 服務器在載入 RDB 文件期間,會一直處於阻塞狀態,直到載入工作完成為止。
與 AOF 格式的文件相比,RDB 文件可以更快的重啟。
RDB 需要經常 fork() 才能使用子進程將其持久化在磁盤上。如果數據集很大,fork() 可能很耗時,並且如果數據集很大且 CPU 性能不佳,則可能導致 Redis 停止為客戶端服務幾毫秒甚至一秒鐘。
禁用持久化可以提高 Redis 的執行效率,如果對數據丟失不敏感的情況下,可以在連接客戶端的情況下,執行 config set save "" 命令即可禁用 Redis 的持久化,如下圖所示:
通過本文我們可以得知,RDB 持久化分為手動觸發和自動觸發兩種方式,它的優點是存儲文件小,Redis 啟動時恢複數據比較快,缺點是有丟失數據的風險。RDB 文件的恢復也很簡單,只需要把 RDB 文件放到 Redis 的根目錄,在 Redis 啟動時就會自動加載並恢複數據。
如果 Redis 服務器 CPU 佔用過高,可能是什麼原因導致的?歡迎各位在評論區,寫下你們的答案。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家費用,距離,噸數怎麼算?達人教你簡易估價知識!
本文Python版本為3.7.X,閱讀本文之前需了解python字典的基本用法。
字典(dict)是Python中內置的一個數據結構,由多個鍵值對組成,鍵(key)和值(value)用冒號分隔,每個鍵值對之間用逗號(,)分隔,整個字典包括在大括號中({}),鍵必須是唯一的,值可以取任何類型,但是鍵必須是不可變類型,如字符串,数字或元組。
底層使用了hash表來關聯key和value,dict是無序的。特點包括:
所以,dict是一種以空間換取時間的數據結構,應用於需要快速查找的場景。
返回指定鍵的值,如果key不存在,則返回默認值(默認為None),而不會報錯,語法為dict.get(key)。
dict_1['age'] = 24
In [7]: print(dict_1.get('age'))
24
In [11]: print(dict_1.get('nama'))
None
In [12]: print(dict_1['nama'])
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-12-ef61a380920e> in <module>
----> 1 print(dict_1['nama'])
KeyError: 'nama'使用in操作符來判斷鍵是否存在於字典中,存在則返回True,否則返回False,語法為:key in dict。
In [15]: dict_1
Out[15]: {'name': None, 'age': 24, 'sex': None}
In [16]: print('name' in dict_1)
True
In [17]: print('nama' in dict_1)
False在python 2中該功能使用has_key()方法實現。
以列表形式返回可遍歷的(鍵, 值)元組數組,語法為dict.items()。
In [18]: dict_1
Out[18]: {'name': None, 'age': 24, 'sex': None}
In [19]: print(dict_1.items())
dict_items([('name', None), ('age', 24), ('sex', None)])
In [20]: for key, value in dict_1.items():
...: print(key, value)
...:
name None
age 24
sex None以列表返回一個字典的所有鍵:dict.keys()
In [21]: dict_1
Out[21]: {'name': None, 'age': 24, 'sex': None}
In [22]: print(dict_1.keys())
dict_keys(['name', 'age', 'sex'])以列表形式返回字典中的所有值:dict.values()
In [27]: dict_1
Out[27]: {'name': None, 'age': 24, 'sex': None, 'sub_name': 'Tony'}
In [28]: print(dict_1.values())
dict_values([None, 24, None, 'Tony'])和get()類似,用戶獲得與給頂尖相關聯的值,不同的是,該方法如果鍵不存在時會添加鍵並將值設為默認值,語法為:dict.setdefault(key, default=None)。
In [23]: dict_1
Out[23]: {'name': None, 'age': 24, 'sex': None}
In [24]: print(dict_1.setdefault('name'))
None
In [25]: print(dict_1.setdefault('name', 'Tony'))
None
In [26]: print(dict_1.setdefault('sub_name', 'Tony'))
Tony
In [27]: dict_1
Out[27]: {'name': None, 'age': 24, 'sex': None, 'sub_name': 'Tony'}語法為:dict_1.update(dict_2),用於把dict_2的鍵值對更新到dict_1中,如果有相同的鍵會被覆蓋。
In [31]: dict_1
Out[31]: {'name': None, 'age': 24, 'sex': None, 'sub_name': 'Tony'}
In [32]: dict_2
Out[32]: {'name': 'Mary', 'age': 18, 'sex': None, 'sub_name': ''}
In [33]: dict_1.update(dict_2)
In [34]: dict_1
Out[34]: {'name': 'Mary', 'age': 18, 'sex': None, 'sub_name': ''}刪除字典中的所有項,dict.clear(),舉個例子:
In [1]: dict_1 = dict(name="Tony", age=24)
In [2]: dict_2 = dict_1
In [3]: print(dict_2)
{'name': 'Tony', 'age': 24}
In [4]: dict_2.clear()
In [5]: dict_2
Out[5]: {}
In [6]: dict_1
Out[6]: {}淺拷貝原始字典,返回一個具有相同鍵值對的新字典,dict.copy(),舉個例子:
In [1]: dict_1 = dict(name='Tony', info=['boy', 24])
In [2]: dict_3 = dict_1.copy()
In [3]: dict_3['name'] = "Ring"
In [4]: dict_3['info'].remove('boy')
In [5]: dict_3
Out[5]: {'name': 'Ring', 'info': [24]}
In [6]: dict_1
Out[6]: {'name': 'Tony', 'info': [24]}創建一個新字典,dict.fromkeys(seq[, value]),以序列seq中的元素做字典的鍵,value為字典所有鍵對應的初始值,其中value為可選參數, 默認為None。適用於數據初始化,舉個例子:
In [1]: info = ['name', 'age', 'sex']
In [2]: dict_1 = dict.fromkeys(info)
In [3]: dict_1
Out[3]: {'name': None, 'age': None, 'sex': None}有四種方式:
In [15]: dict_1
Out[15]: {'Tony': 24}
In [16]: dict_2
Out[16]: {'ben': 18}
In [17]: dict3 = dict()
In [18]: for key, value in dict_1.items():
...: dict_3[key] = value
...:
In [19]: for key, value in dict_2.items():
...: dict_3[key] = value
...:
In [20]: dict_3
Out[20]: {'Tony': 24, 'ben': 18}In [9]: dict_1
Out[9]: {'Tony': 24}
In [10]: dict_2
Out[10]: {'ben': 18}
In [12]: dict_3 = dict_1.copy()
In [13]: dict_3.update(dict_2)
In [14]: dict_3
Out[14]: {'Tony': 24, 'ben': 18}In [33]: dict_1
Out[33]: {'Tony': 24}
In [34]: dict_2
Out[34]: {'ben': 18}
In [35]: dict_3 = dict(dict_1, **dict_2)
In [36]: dict_3
Out[36]: {'Tony': 24, 'ben': 18}和列表推導式類似,優點是底層用C實現,會快很多,推薦使用。
使用字典推導式可以輕鬆對換一個字典的鍵值:
In [42]: dict_4
Out[42]: {24: 'Tony', 18: 'ben'}
In [43]: dict_3
Out[43]: {'Tony': 24, 'ben': 18}
In [44]: dict_4 = {k:v for v, k in dict_3.items()}
In [45]: dict_4
Out[45]: {24: 'Tony', 18: 'ben'}想創建一個字典,其本身是另一個字典的子集。
舉個例子:
In [88]: a = {'Ben': 18, 'Jack': 12, 'Ring': 23, 'Tony': 24}
In [89]: b = {k:v for k, v in a.items() if v > 18}
In [90]: b
Out[90]: {'Ring': 23, 'Tony': 24}在Python3.6之前的字典是無序的,但是有時候我們需要保持字典的有序性,orderDict可以在dict的基礎上實現字典的有序性,這裏的有序指的是按照字典key插入的順序來排列,這樣就實現了一個先進先出的dict,當容量超出限制時,先刪除最早添加的key。
舉例:
In [49]: from collections import OrderedDict
In [50]: ordered_dict = OrderedDict([('a', 2), ('b', 4), ('c', 5)])
In [51]: for key, value in ordered_dict.items():
...: print(key, value)
...:
a 2
b 4
c 5可以看到OrderedDict是按照字典創建時的插入順序來排序。
原理:OrderedDict內部維護了一個雙向鏈表,它會根據元素加入的順序來排列鍵的位置,這也就導致OrderedDict的大小是普通字典的2倍多。
也就是生成所謂的一鍵多值字典,需要將對應的多個值保存在其它容器比如列表或集合,取決於多值是否需要保證唯一性。
舉個例子:
In [64]: from collections import defaultdict
In [65]: a = [{'a': 1}, {'b': 3}, {'c': 4}, {'a':5}, {'b':2}, {'b': 4}]
In [66]: b = defaultdict(list)
In [67]: [b[k].append(v) for item in a for k, v in item.items()]
Out[67]: [None, None, None, None, None, None]
In [68]: b
Out[68]: defaultdict(list, {'a': [1, 5], 'b': [3, 2, 4], 'c': [4]})
In [69]: b['a']
Out[69]: [1, 5]場景:尋找兩個字典中的異同,包括相同的鍵或者相同的值。
分析:字典是一系列鍵值之間的映射集合,有以下特點:
舉例:
In [78]: a = {'a':1, 'b':2, 'c':3}
In [79]: b = {'b':3, 'c':3, 'd':4}
In [80]: a.keys() & b.keys()
Out[80]: {'b', 'c'}
In [81]: a.keys() - b.keys()
Out[81]: {'a'}
In [82]: a.items() & b.items()
Out[82]: {('c', 3)}再舉一個例子,在創建一個字典時,期望可以去除某些鍵:
In [85]: a
Out[85]: {'a': 1, 'b': 2, 'c': 3}
In [86]: c = {k: a[key] for k in a.keys() - {'b'}}
In [87]: c
Out[87]: {'a': 3, 'c': 3}以上。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※想知道網站建置、網站改版該如何進行嗎?將由專業工程師為您規劃客製化網頁設計及後台網頁設計
※不管是台北網頁設計公司、台中網頁設計公司,全省皆有專員為您服務
※Google地圖已可更新顯示潭子電動車充電站設置地點!!