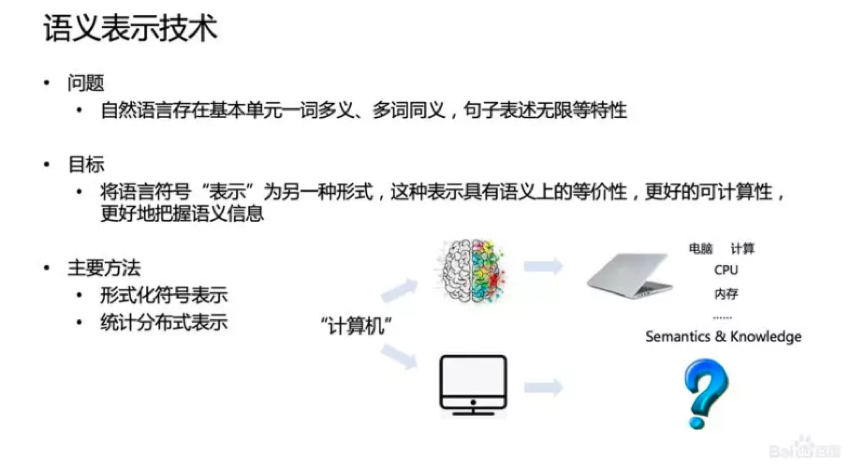
MySQL InnoDB支持三種行鎖定
-
行鎖(Record Lock):鎖直接加在索引記錄上面,鎖住的是key。
-
間隙鎖(Gap Lock):鎖定索引記錄間隙,確保索引記錄的間隙不變。間隙鎖是針對事務隔離級別為可重複讀或以上級別而設計的。
-
后碼鎖(Next-Key Lock):行鎖和間隙鎖組合起來就叫Next-Key Lock。
默認情況下,InnoDB工作在可重複讀隔離級別下,並且會以Next-Key Lock的方式對數據行進行加鎖,這樣可以有效防止幻讀的發生。Next-Key Lock是行鎖和間隙鎖的組合,當InnoDB掃描索引記錄的時候,會首先對索引記錄加上行鎖(Record Lock),再對索引記錄兩邊的間隙加上間隙鎖(Gap Lock)。加上間隙鎖之後,其他事務就不能在這個間隙修改或者插入記錄。
行鎖(Record Lock)
- 當需要對表中的某條數據進行寫操作(insert、update、delete、select for update)時,需要先獲取記錄的排他鎖(X鎖),這個就稱為行鎖。
create table x(`id` int, `num` int, index `idx_id` (`id`));
insert into x values(1, 1), (2, 2);
-- 事務A
START TRANSACTION;
update x set id = 1 where id = 1;
-- 事務B
-- 如果事務A沒有commit,id=1的記錄拿不到X鎖,將出現等待
START TRANSACTION;
update x set id = 1 where id = 1;
-- 事務C
-- id=2的記錄可以拿到X鎖,不會出現等待
START TRANSACTION;
update x set id = 2 where id = 2;- 針對InnoDB RR隔離級別,上述SQL示例展示了行鎖的特點:“鎖定特定行不允許進行修改”,但行鎖是基於表索引的,如果where條件中用的是num字段(非索引列)將產生不一樣的現象:
-- 事務A
START TRANSACTION;
update x set num = 1 where num = 1;
-- 事務B
-- 由於事務A中num字段上沒有索引將產生表鎖,導致整張表的寫操作都會出現等待
START TRANSACTION;
update x set num = 1 where num = 1;
-- 事務C
-- 同理,會出現等待
START TRANSACTION;
update x set num = 2 where num = 2;
-- 事務D
-- 等待
START TRANSACTION;
insert into x values(3, 3);Gap鎖(Gap Lock)
在MySQL中select稱為快照讀,不需要鎖,而insert、update、delete、select for update則稱為當前讀,需要給數據加鎖,幻讀中的“讀”即是針對當前讀。
RR事務隔離級別允許存在幻讀,但InnoDB RR級別卻通過Gap鎖避免了幻讀
產生間隙鎖的條件(RR事務隔離級別下)
- 使用普通索引鎖定
- 使用多列唯一索引
- 使用唯一索引鎖定多行記錄
唯一索引的間隙鎖
測試環境
MySQL,InnoDB,默認的隔離級別(RR)數據表
CREATE TABLE `test` (
`id` int(1) NOT NULL AUTO_INCREMENT,
`name` varchar(8) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;數據
INSERT INTO `test` VALUES ('1', '小羅');
INSERT INTO `test` VALUES ('5', '小黃');
INSERT INTO `test` VALUES ('7', '小明');
INSERT INTO `test` VALUES ('11', '小紅');以上數據,會生成隱藏間隙
(-infinity, 1]
(1, 5]
(5, 7]
(7, 11]
(11, +infinity]
只使用記錄鎖,不會產生間隙鎖
/* 開啟事務1 */
BEGIN;
/* 查詢 id = 5 的數據並加記錄鎖 */
SELECT * FROM `test` WHERE `id` = 5 FOR UPDATE;
/* 延遲30秒執行,防止鎖釋放 */
SELECT SLEEP(30);
-- 注意:以下的語句不是放在一個事務中執行,而是分開多次執行,每次事務中只有一條添加語句
/* 事務2插入一條 name = '小張' 的數據 */
INSERT INTO `test` (`id`, `name`) VALUES (4, '小張'); # 正常執行
/* 事務3插入一條 name = '小張' 的數據 */
INSERT INTO `test` (`id`, `name`) VALUES (8, '小東'); # 正常執行
/* 提交事務1,釋放事務1的鎖 */
COMMIT;以上,由於主鍵是唯一索引,而且是只使用一個索引查詢,並且只鎖定一條記錄,所以,只會對 id = 5 的數據加上記錄鎖,而不會產生間隙鎖。
產生間隙鎖
/* 開啟事務1 */
BEGIN;
/* 查詢 id 在 7 - 11 範圍的數據並加記錄鎖 */
SELECT * FROM `test` WHERE `id` BETWEEN 5 AND 7 FOR UPDATE;
/* 延遲30秒執行,防止鎖釋放 */
SELECT SLEEP(30);
-- 注意:以下的語句不是放在一個事務中執行,而是分開多次執行,每次事務中只有一條添加語句
/* 事務2插入一條 id = 3,name = '小張1' 的數據 */
INSERT INTO `test` (`id`, `name`) VALUES (3, '小張1'); # 正常執行
/* 事務3插入一條 id = 4,name = '小白' 的數據 */
INSERT INTO `test` (`id`, `name`) VALUES (4, '小白'); # 正常執行
/* 事務4插入一條 id = 6,name = '小東' 的數據 */
INSERT INTO `test` (`id`, `name`) VALUES (6, '小東'); # 阻塞
/* 事務5插入一條 id = 8, name = '大羅' 的數據 */
INSERT INTO `test` (`id`, `name`) VALUES (8, '大羅'); # 阻塞
/* 事務6插入一條 id = 9, name = '大東' 的數據 */
INSERT INTO `test` (`id`, `name`) VALUES (9, '大東'); # 阻塞
/* 事務7插入一條 id = 11, name = '李西' 的數據 */
INSERT INTO `test` (`id`, `name`) VALUES (11, '李西'); # 阻塞
/* 事務8插入一條 id = 12, name = '張三' 的數據 */
INSERT INTO `test` (`id`, `name`) VALUES (12, '張三'); # 正常執行
/* 提交事務1,釋放事務1的鎖 */
COMMIT;從上面我們可以看到,(5, 7]、(7, 11] 這兩個區間,都不可插入數據,其它區間,都可以正常插入數據。所以當我們給 (5, 7] 這個區間加鎖的時候,會鎖住 (5, 7]、(7, 11] 這兩個區間。
鎖住不存在的數據
/* 開啟事務1 */
BEGIN;
/* 查詢 id = 3 這一條不存在的數據並加記錄鎖 */
SELECT * FROM `test` WHERE `id` = 3 FOR UPDATE;
/* 延遲30秒執行,防止鎖釋放 */
SELECT SLEEP(30);
-- 注意:以下的語句不是放在一個事務中執行,而是分開多次執行,每次事務中只有一條添加語句
/* 事務2插入一條 id = 3,name = '小張1' 的數據 */
INSERT INTO `test` (`id`, `name`) VALUES (2, '小張1'); # 阻塞
/* 事務3插入一條 id = 4,name = '小白' 的數據 */
INSERT INTO `test` (`id`, `name`) VALUES (4, '小白'); # 阻塞
/* 事務4插入一條 id = 6,name = '小東' 的數據 */
INSERT INTO `test` (`id`, `name`) VALUES (6, '小東'); # 正常執行
/* 事務5插入一條 id = 8, name = '大羅' 的數據 */
INSERT INTO `test` (`id`, `name`) VALUES (8, '大羅'); # 正常執行
/* 提交事務1,釋放事務1的鎖 */
COMMIT;我們可以看出,指定查詢某一條記錄時,如果這條記錄不存在,會產生間隙鎖
結論
- 對於指定查詢某一條記錄的加鎖語句,如果該記錄不存在,會產生記錄鎖和間隙鎖,如果記錄存在,則只會產生記錄鎖,如:WHERE
id= 5 FOR UPDATE; - 對於查找某一範圍內的查詢語句,會產生間隙鎖,如:WHERE
idBETWEEN 5 AND 7 FOR UPDATE;
普通索引的間隙鎖
數據準備
創建 test1 表:
- 注意:number 不是唯一值
CREATE TABLE `test1` (
`id` int(1) NOT NULL AUTO_INCREMENT,
`number` int(1) NOT NULL COMMENT '数字',
PRIMARY KEY (`id`),
KEY `number` (`number`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;id 是主鍵,number上建立了一個普通索引。先加一些數據:
INSERT INTO `test1` VALUES (1, 1);
INSERT INTO `test1` VALUES (5, 3);
INSERT INTO `test1` VALUES (7, 8);
INSERT INTO `test1` VALUES (11, 12);test1表中 number 索引存在的隱藏間隙:
(-infinity, 1]
(1, 3]
(3, 8]
(8, 12]
(12, +infinity]
執行以下的事務(事務1最後提交)
/* 開啟事務1 */
BEGIN;
/* 查詢 number = 5 的數據並加記錄鎖 */
SELECT * FROM `test1` WHERE `number` = 3 FOR UPDATE;
/* 延遲30秒執行,防止鎖釋放 */
SELECT SLEEP(30);
-- 注意:以下的語句不是放在一個事務中執行,而是分開多次執行,每次事務中只有一條添加語句
/* 事務2插入一條 number = 0 的數據 */
INSERT INTO `test1` (`number`) VALUES (0); -- 正常執行
/* 事務3插入一條 number = 1 的數據 */
INSERT INTO `test1` (`number`) VALUES (1); -- 被阻塞
/* 事務4插入一條 number = 2 的數據 */
INSERT INTO `test1` (`number`) VALUES (2); -- 被阻塞
/* 事務5插入一條 number = 4 的數據 */
INSERT INTO `test1` (`number`) VALUES (4); -- 被阻塞
/* 事務6插入一條 number = 8 的數據 */
INSERT INTO `test1` (`number`) VALUES (8); -- 正常執行
/* 事務7插入一條 number = 9 的數據 */
INSERT INTO `test1` (`number`) VALUES (9); -- 正常執行
/* 事務8插入一條 number = 10 的數據 */
INSERT INTO `test1` (`number`) VALUES (10); -- 正常執行
/* 提交事務1 */
COMMIT;這裏可以看到,number (1 – 8) 的間隙中,插入語句都被阻塞了,而不在這個範圍內的語句,正常執行,這就是因為有間隙鎖的原因。
加深對間隙鎖的理解
將數據還原成初始化的那樣
/* 開啟事務1 */
BEGIN;
/* 查詢 number = 5 的數據並加記錄鎖 */
SELECT * FROM `test1` WHERE `number` = 3 FOR UPDATE;
/* 延遲30秒執行,防止鎖釋放 */
SELECT SLEEP(30);
/* 事務1插入一條 id = 2, number = 1 的數據 */
INSERT INTO `test1` (`id`, `number`) VALUES (2, 1); -- 阻塞
/* 事務2插入一條 id = 3, number = 2 的數據 */
INSERT INTO `test1` (`id`, `number`) VALUES (3, 2); -- 阻塞
/* 事務3插入一條 id = 6, number = 8 的數據 */
INSERT INTO `test1` (`id`, `number`) VALUES (6, 8); -- 阻塞
/* 事務4插入一條 id = 8, number = 8 的數據 */
INSERT INTO `test1` (`id`, `number`) VALUES (8, 8); -- 正常執行
/* 事務5插入一條 id = 9, number = 9 的數據 */
INSERT INTO `test1` (`id`, `number`) VALUES (9, 9); -- 正常執行
/* 事務6插入一條 id = 10, number = 12 的數據 */
INSERT INTO `test1` (`id`, `number`) VALUES (10, 12); -- 正常執行
/* 事務7修改 id = 11, number = 12 的數據 */
UPDATE `test1` SET `number` = 5 WHERE `id` = 11 AND `number` = 12; -- 阻塞
/* 提交事務1 */
COMMIT;這裡有一個奇怪的現象:
事務3添加 id = 6,number = 8 的數據,給阻塞了;
事務4添加 id = 8,number = 8 的數據,正常執行了。
事務7將 id = 11,number = 12 的數據修改為 id = 11, number = 5的操作,給阻塞了;
這是為什麼呢?我們來看看下邊的圖
從圖中可以看出,當 number 相同時,會根據主鍵 id 來排序,所以:
事務3添加的 id = 6,number = 8,這條數據是在 (3, 8) 的區間裡邊,所以會被阻塞;
事務4添加的 id = 8,number = 8,這條數據則是在(8, 12)區間裡邊,所以不會被阻塞;
事務7的修改語句相當於在 (3, 8) 的區間裡邊插入一條數據,所以也被阻塞了。
結論
- 在普通索引列上,不管是何種查詢,只要加鎖,都會產生間隙鎖,這跟唯一索引不一樣
- 在普通索引跟唯一索引中,數據間隙的分析,數據行是優先根據普通索引排序,再根據唯一索引排序
后碼鎖(Next-key Locks)
后碼鎖是記錄鎖與間隙鎖的組合,它的封鎖範圍,既包含索引記錄,又包含索引區間。
注:Next-key Lock的主要目的,也是為了避免幻讀(Phantom Read)。如果把事務的隔離級別降級為RC,Next-key Lock則也會失效。
總結
- 記錄鎖、間隙鎖、后碼鎖,都屬於排它鎖;
- 記錄鎖就是鎖住一行記錄;
- 間隙鎖只有在事務隔離級別 RR 中才會產生;
- 唯一索引只有鎖住多條記錄或者一條不存在的記錄的時候,才會產生間隙鎖,指定給某條存在的記錄加鎖的時候,只會加記錄鎖,不會產生間隙鎖;
- 普通索引不管是鎖住單條,還是多條記錄,都會產生間隙鎖;
- 間隙鎖會封鎖該條記錄相鄰兩個鍵之間的空白區域,防止其它事務在這個區域內插入、修改、刪除數據,這是為了防止出現 幻讀 現象;
- 普通索引的間隙,優先以普通索引排序,然後再根據主鍵索引排序;
- 事務級別是RC(讀已提交)級別的話,間隙鎖將會失效。
資料
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
※評比南投搬家公司費用收費行情懶人包大公開