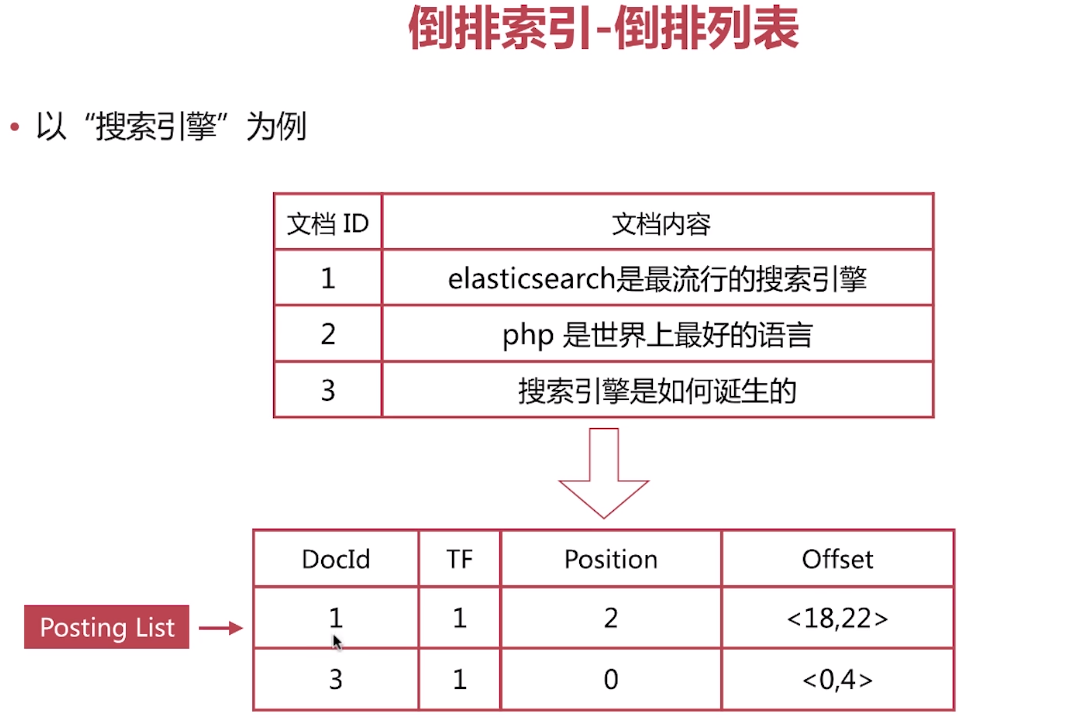
目錄
@
我不想知道各位理解java多態沒有烤山藥的存在,java香不香的問題了,我不要你們認為,我只要我覺得 (感覺要被打….)
在博主認為多態絕對是面向對象的第三大特性中讓很多小白同學以及初學者難以跨越的鴻溝,因為多態有很多細節性的知識,不花點時間,還真不好理解多態。這麼說吧,如果你覺得你已經完全理解了多態,你不妨做做下面的程序,如果你能全都答對,那沒問題了,多態對你來說真的不是問題!如果在第四個就趴下了,那可以看看這篇文章,或許對你有所幫助,可能會讓你重新見識到多態的魅力。
package Polymorphic;
//爺爺類
class Ye {
public String show(Sun obj) {
return ("Ye and Sun");
}
public String show(Ye obj) {
return ("Ye and Ye");
}
}
//爸爸類
class Fu extends Ye {
public String show(Fu obj) {
return ("Fu and Fu");
}
public String show(Ye obj) {
return ("Fu and Ye");
}
}
//兒子類
class Zi extends Fu {
}
//孫子類
class Sun extends Fu {
}
public class PolymorphicTest {
public static void main(String[] args) {
Ye y = new Ye();
Ye y2 = new Fu(); //向上
Fu f = new Fu();
Zi z = new Zi();
Sun s = new Sun();
System.out.println("第一題 " + y.show(f));
System.out.println("第二題 " + y.show(z));
System.out.println("第三題 " + y.show(s));
System.out.println("第四題 " + y2.show(f)); //到這裏掛了???
System.out.println("第五題 " + y2.show(z));
System.out.println("第六題 " + y2.show(s));
System.out.println("第七題 " + f.show(f));
System.out.println("第八題 " + f.show(z));
System.out.println("第九題 " + f.show(s));
}
}
先把答案記在小本本上吧,再對照下面結果看看
第一題 Ye and Ye
第二題 Ye and Ye
第三題 Ye and Sun
第四題 Fu and Ye
第五題 Fu and Ye
第六題 Ye and Sun
第七題 Fu and Fu
第八題 Fu and Fu
第九題 Ye and Sun
如果你對上面的結果很意外,或者不解,那麼恭喜你,你又能學到新知識了,成功的向架構師前進了一步!好了,讓我們一起重新見識見識多態的魅力吧!
1、 從吃烤山藥重新認識多態
最近不是正火着吃烤山藥么,學習就要走有趣化路線,畢竟興趣永遠最好的老師,咋們放開點,怎麼有趣怎麼來。
小明媽媽的情緒非常不穩定,心情好的時候巴不得給小明花一個億,,心情不好的時候巴不得把小明打成麻瓜,可是小明永遠不知道媽媽的情緒變化。這不,今天一位老大爺在賣烤山藥,邊烤還邊跳激光雨,嗨得不行,小明特別喜歡激光雨,馬上就忍不住了,心裏默默想着,剛烤的山藥它不香嘛,激光雨烤的山藥它不香嘛。於是忍不住對媽媽說:“媽媽,我想吃烤山藥”,這個時候,來了,來了,他來了,它真的來了….你激動個鎚子啊……是代碼來了:
package Polymorphic;
class Matcher{
public void matcherSpeak(){
System.out.println("想吃烤山藥?");
}
}
class HappyMother extends Matcher {
public void matcherSpeak(){
System.out.println("開心的媽媽說:吃,吃大塊的,一火車夠嗎");
}
}
class SadMother extends Matcher {
public void matcherSpeak(){
System.out.println("不開心的媽媽說:吃你個憨皮,看我回家扎不扎你就完事了");
}
}
class VeryHappyMother extends Matcher {
public void matcherSpeak(){
System.out.println("異常開心的媽媽說:買買買,烤山藥咱全買了,順便把大爺也買回家,天天給你表演激光雨(大爺懵逼中)");
}
}
public class UnderstandPolymorphic{
public static void main(String[] args) {
Matcher m = new HappyMother();
m.matcherSpeak();
m = new SadMother();
m.matcherSpeak();
m = new VeryHappyMother();
m.matcherSpeak();
}
}
運行結果:
開心的媽媽說:吃,吃大塊的,一火車夠嗎
不開心的媽媽說:吃你個憨皮,看我回家扎不扎你就完事了
異常開心的媽媽說:買買買,烤山藥咱全買了,順便把大爺也買回家,天天給你表演激光雨(大爺懵逼中)
媽媽聽到小明想吃烤山藥這同一行為,表現出不同的表現形式,這就是多態。多態專業定義則是:程序中定義的引用變量所指向的具體類型和通過該引用變量發出的方法調用在編程時並不確定,而是在程序運行期間才確定,這種情況叫做多態沒錯是沒錯就是腦殼有點大,所以我選擇簡單點定義多態: 多態指同一行為,具有多個不同表現形式。為何會有如此微妙的變化呢,那我們就必須了解進行多態的前提了。
2、 多態前提條件【重點】
如果多態不能滿足以下三個前提條件,那還玩犢子的多態【構不成多態,缺一不可】
- 繼承或者實現【二選一】
- 方法的重寫【意義體現:不重寫,無意義】
子類對父類中某些方法進行重新定義,在調用這些方法時就會調用子類的方法。
- 父類引用指向子類對象(也可以說向上轉型)【體現在格式上】
回過頭來看烤山藥例子,確實都有繼承,同樣都重寫了motherSpeak()方法,最關鍵的代碼則是
Matcher m = new HappyMother();
也就是所謂的 父類引用指向子類對象,這其實就是向上轉型!對向上轉型概念不清晰沒事,下面會詳細講解。
3、 多態的體現
多態體現的格式: 父類/父接口類型 變量名 = new 子類對象; 變量名.方法名();
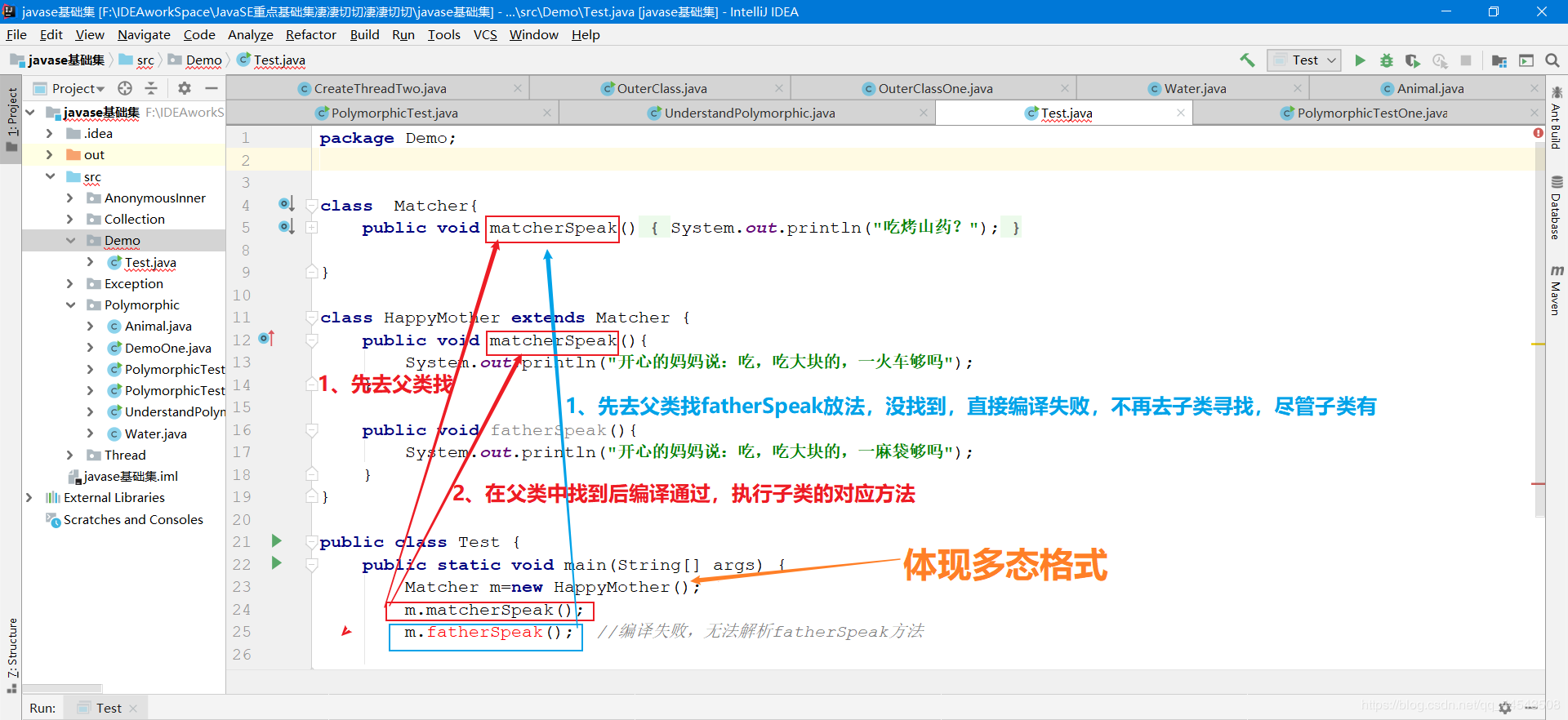
當使用多態方式調用方法時,首先檢查父類中是否有該方法,如果沒有,則編譯錯誤 ,如果有,執行的是子類重寫后的方法,也就是向上轉型時, 子類單獨定義的方法丟失問題。編譯報錯。 代碼如下:
package Demo;
class Matcher{
public void matcherSpeak(){//=========================父類matcherSpeak()方法
System.out.println("吃烤山藥?");
}
}
class HappyMother extends Matcher {
public void matcherSpeak(){//=========================子類matcherSpeak()方法
System.out.println("開心的媽媽說:吃,吃大塊的,一蛇皮袋夠嗎");
}
public void fatherSpeak(){//=========================子類獨有的fatherSpeak()方法
System.out.println("開心的媽媽說:吃,吃大塊的,一麻袋夠嗎");
}
}
public class Test {
public static void main(String[] args) {
Matcher m=new HappyMother();
m.matcherSpeak();
m.fatherSpeak(); //編譯失敗,無法解析fatherSpeak方法
}
}
分析如下:
當然這個例子只是入門級的,接下來看個有點水平的例子
package Demo;
class Matcher{
public void matcherSpeak(){
System.out.println("想吃烤山藥?");
}
}
class HappyMother extends Matcher {
public void matcherSpeak(){
System.out.println("開心的媽媽說:吃,吃大塊的,一火車夠嗎");
}
}
class SadMother extends HappyMother{
public void tt(){
System.out.println("ttttttt");
}
}
public class Test {
public static void main(String[] args) {
Matcher mm=new SadMother();
mm.matcherSpeak();
}
運行結果:開心的媽媽說:吃,吃大塊的,一火車夠嗎
}
有了第一個基礎這個相信不難理解,接着看
package Demo;
class Matcher{
public void matcherSpeak(){
System.out.println("想吃烤山藥?");
}
}
class HappyMother extends Matcher {
}
class SadMother extends HappyMother{
public void tt(){
System.out.println("ttttttt");
}
}
public class Test {
public static void main(String[] args) {
Matcher mm=new SadMother();
mm.matcherSpeak();
}
運行結果:想吃烤山藥?
}
到這裏,再來回味下這句話:
當使用多態方式調用方法時,首先檢查父類中是否有該方法,如果沒有,則編譯錯誤 ,如果有,執行的是子類重寫后的方法
你可能會說子類中都沒有這些個方法啊,何來執行子類重寫后的方法一說?它好像是去父類中找該方法了。事實上,子類中是有這些方法的,這個方法繼承自父類,只不過沒有覆蓋該方法,所以沒有在子類中明確寫出來而已,看起來像是調用了父類中的方法,實際上調用的還是子類中的。同學繼承方面的知識該補補了,可以參考下面這篇
4、 多態動態綁定與靜態綁定
講之前博主先來談談“綁定”的概念:
綁定指的是一個方法的調用與方法所在的類(方法主體)關聯起來,大致可以理解為一個方法調用另一個方法。對java來說,綁定分為靜態綁定和動態綁定;或者分別叫做前期綁定和後期綁定。
4、1.靜態綁定(前期綁定)
在程序執行前方法已經被綁定,==針對java靜態綁定簡單的可以理解為程序編譯期的綁定==;java當中的方法只有final,static,private(不會被繼承) 和構造方法是前期綁定【當然可能不止】
4、2.動態綁定(後期綁定)
後期綁定:在運行時根據具體對象的類型進行綁定。
若一種語言實現了後期綁定,同時必須提供一些機制,可在運行期間判斷對象的類型,並分別調用適當的方法。也就是說,編譯器此時依然不知道對象的類型,但方法調用機制能自己去調查,找到正確的方法主體。不同的語言對後期綁定的實現方法是有所區別的。但我們至少可以這樣認為:它們都要在對象中安插某些特殊類型的信息。==簡明的說動態綁定就是指編譯器在編譯階段不知道要調用哪個方法,運行期才能確定==
4、3.靜態、動態綁定本質區別
1、靜態綁定是發生在編譯階段;而動態綁定是在運行階段;
2、靜態綁定使用的是類信息,而動態綁定使用的是對象信息
3、重載方法(overloaded methods)使用的是靜態綁定,而重寫方法(overridden methods)使用的是動態綁定
4、4.靜態、動態綁定在程序中運行區別
這個靜態綁定例子以static方法為例,代碼程序如下:
package demoee;
class Father5{
public void StaticMethod(){
System.out.println("粑粑:我是父類粑粑靜態方法");
}
}
class Son5 extends Father5{
public void StaticMethod(){
System.out.println("熊孩子:我是子類熊孩砸靜態方法");
}
}
public class demooo {
public static void main(String[] args) {
Father5 fat=new Father5();
Father5 son=new Son5(); //特別注意這裡是向上轉型 也就是多態!
fat.StaticMethod();//同時調用StaticMethod方法!
son.StaticMethod();
}
}
運行結果
粑粑:我是父類粑粑靜態方法
熊孩子:我是子類熊孩砸靜態方法
根據上面的運行結果,我們也很好理解!子類重寫了父類的一個叫做StaticMethod()的方法,由於是動態綁定,因此最後執行的是子類重寫后的StaticMethod()方法。
嗯哼?為了更好的理解靜態、動態綁定在程序中運行區別,我們還是得看看下面這個程序:
class Father5{
public static void StaticMethod(){
System.out.println("粑粑:我是父類粑粑靜態方法");
}
}
class Son5 extends Father5{
public static void StaticMethod(){
System.out.println("熊孩子:我是子類熊孩砸靜態方法");
}
}
public class demooo {
public static void main(String[] args) {
Father5 fat=new Father5();
Father5 son=new Son5(); //特別注意這裡是向上轉型 也就是多態!
fat.StaticMethod();//同時調用StaticMethod方法!
son.StaticMethod();
}
}
千萬注意哦,這個程序與第一個程序唯一不同之處就在於這個程序父類和子類的方法都是static的!
運行結果:
粑粑:我是父類粑粑靜態方法
粑粑:我是父類粑粑靜態方法
從運行結果來看,我們可以很清楚的知道,子類靜態方法語法上是做到了重寫的作用,但實際上並沒有做到真正意義上重寫作用!只因為該方法是靜態綁定!
OK,get到了咩?如果get到了請點個讚唄,謝謝你~
5、 多態特性的虛方法(virtual)
虛方法出現在Java的多態特性中。
父類與子類之間的多態性,對父類的函數進行重新定義。如果在子類中定義某方法與其父類有相同的名稱和參數,我們說該方法被重寫 (Overriding)。在Java中,子類可繼承父類中的方法,而不需要重新編寫相同的方法。但有時子類並不想原封不動地繼承父類的方法,而是想作一定的修改,這就需要採用方法的重寫。方法重寫又稱方法覆蓋。
當設計類時,被重寫的方法的行為怎樣影響多態性。方法的重寫使得子類能夠重寫父類的方法。當子類對象調用重寫的方法時,調用的是子類的方法,而不是父類中被重寫的方法。
因此簡單明了的理解Java虛方法方式你可以理解為java里所有父類中被重寫的方法都是虛方法(virtual)差不多的意思就是該方法不會被子類使用到,使用到的都是子類中重寫父類的方法,子類中的重寫方法代替了它,因此也就有種名存實亡的感覺!
在JVM字節碼執行引擎中,方法調用會使用invokevirtual字節碼指令來調用所有的虛方法。
小白童鞋千萬需要注意虛方法和抽象方法並不是同一個概念!
# 6、 重載屬於多態嗎?
縱觀重載與重寫,重寫是多態的特徵體現無疑了!但是對於重載是不是多態的體現網上卻議論紛紛!
多態是基於對抽象方法的覆蓋來實現的,用統一的對外接口來完成不同的功能。重載也是用統一的對外接口來完成不同的功能。那麼兩者有什麼區別呢?
重載
重載是指允許存在多個同名方法,而這些方法的參數不同。重載的實現是:編譯器根據方法不同的參數表,對同名方法的名稱做修飾。對於編譯器而言,這些同名方法就成了不同的方法。它們的調用地址在編譯期就綁定了。
多態
多態是指子類重新定義父類的虛方法(virtual,abstract)。當子類重新定義了父類的虛方法后,父類根據賦給它的不同的子類,動態調用屬於子類的該方法,這樣的方法調用在編譯期間是無法確定的。
不難看出,兩者的區別在於編譯器何時去尋找所要調用的具體方法,對於重載而言,在方法調用之前,編譯器就已經確定了所要調用的方法,這稱為“早綁定”或“靜態綁定”;而對於多態,只有等到方法調用的那一刻,編譯器才會確定所要調用的具體方法,這稱為“晚綁定”或“動態綁定”。
所以,你可以大可認為重載不屬於多態,多態是對父類虛函數的重定義,不改變原虛函數的參數列表。重載是函數名相同,但參數列表不同。
實際上這種問題沒有嚴格的答案,就連教材書上都沒提及。嚴格來說或狹義來講,重載算多態還是有點牽強,傳統的多態就是指父類和子類關係,但實際開發中都是理解重載是多態。這就是一個概念 你子類擁有你很多隱式父類的功能 那麼你當然能扮演它們之中的某一個角色。
總的來說,在博主認為,重載是不是多態這個問題以及不重要了,首當其沖的重要任務我覺得還是好好保護頭髮,然後就是養生了….
7、 向上轉型
向上轉型:多態本身是子類類型向父類類型向上轉換的過程,其中,這個過程是默認的。你可以把這個過程理解為基本類型的小類型轉大類型自動轉換,不需要強制轉換。 當父類引用指向一個子類對象時,便是向上轉型。 向上轉型格式:
父類類型 變量名 = new 子類類型(); 如:Father f= new Son();
例子的話,烤山藥的例子就是一個典型的向上轉型例子
8、 向下轉型
向下轉型:父類類型向子類類型向下轉換的過程,這個過程是強制的。同樣可以把這個過程理解為基本類型的自動轉換,大類型轉小類型需要強制轉換。一個已經向上轉型的子類對象,將父類引用轉為子類引用,可以使用強制類型轉換的格式,向下轉使用格式:
Father father = new Son();
子類類型 變量名 = (子類類型) 父類變量名; 如:Son s =(Son) father;
不知道你們有沒有發現,向下轉型的前提是父類對象指向的是子類對象(也就是說,在向下轉型之前,它得先向上轉型),當然,向下轉型還是有它的意義所在,下面就講解向下轉型的意義。
到這裏,我們講解一下為什麼要向下轉型?上面已經講到過當使用多態方式調用方法時,首先檢查父類中是否有該方法,如果沒有,則編譯錯誤。也就是說,不能調用子類擁有,而父類沒有的方法。編譯都錯誤,更別說運行了。這也是多態給我們帶來的一點”小麻煩”。所以,想要調用子類特有的方法,必須做向下轉型。
package Demo;
class Matcher{
public void eat(){
System.out.println("想吃烤山藥?");
}
}
class XiongHaiZi extends Matcher {
public void eat(){
System.out.println("媽媽,我想吃烤山藥");
}
public void eatSuLi(){//============================子類特有的eatSuLi方法
System.out.println("麻麻,我想吃酥梨,要吃麻瓜那麼大的酥梨");
}
}
public class Test {
public static void main(String[] args) {
Matcher m = new XiongHaiZi();//向上轉型
XiongHaiZi x = (XiongHaiZi)m;//向下轉型
x.eatSuLi();//執行子類特有方法
}
運行結果:麻麻,我想吃酥梨,要吃麻瓜那麼大的酥梨
}
好了向下轉型就講到這裏…等等,你真的以為就講完了?肯定不行嘍,向下轉型還有一個要說的知識,講之前先來看個程序先
package Demo;
class Matcher{
public void eat(){
System.out.println("想吃烤山豬?");
}
}
class Boy extends Matcher {
public void eatKaoYang(){
System.out.println("媽媽,我想吃烤山豬");
}
}
class Girl extends Matcher {
public void eatKaoYang(){
System.out.println("媽媽,我想吃烤山豬2333");
}
}
public class Test {
public static void main(String[] args) {
Matcher g = new Girl();//向上轉型編譯通過
Boy x = (Boy)g;//向下轉型
x.eatKaoYang();//編譯通過,但運行報ClassCastException
}
運行結果: 運行報ClassCastException
}
這段代碼可以通過編譯,但是運行時,卻報出了 ClassCastException ,類型轉換異常!這是因為,明明創建了Girl類型對象,運行時,當然不能轉換成Boy對象的。這兩個類型並沒有任何繼承關係,不符合類型轉換的定義。 為了避免ClassCastException的發生,Java提供了 instanceof 關鍵字,給引用變量做類型的校驗。
8、1. instanceof的使用
instanceof 的格式:
變量名 instanceof 數據類型
instanceof 的使用
如果變量屬於該數據類型,返回true。
如果變量不屬於該數據類型,返回false。
所以,轉換前,我們最好使用instanceof 先做一個判斷,代碼如下:
package Demo;
class Matcher{
public void eat(){
System.out.println("想吃烤山藥?");
}
}
class Boy extends Matcher {
public void eatKaoYang(){
System.out.println("Boy:媽媽,我想吃烤羊");
}
}
class Girl extends Matcher {
public void eatKaoYang(){
System.out.println("Girl:媽媽,我想吃烤全羊2333");
}
}
public class Test {
public static void main(String[] args) {
Matcher g = new Girl();//向上轉型
if(g instanceof Girl){
Girl x = (Girl)g;//向下轉型
x.eatKaoYang(); //=====================調用Girl的eatKaoYang()方法
}else if(g instanceof Boy){ //不執行
Boy x = (Boy)g;//向下轉型
x.eatKaoYang(); //=====================調用Boy的eatKaoYang()方法
}
}
}
運行結果: Girl:媽媽,我想吃烤全羊2333
好了到這裏,你get到了咩?
9、 向上向下轉型再次分析【加餐不加價】
看完之後是不是還是不夠清晰向上向下轉型?多態轉型問題其實並不複雜,只要記住一句話:父類引用指向子類對象。那什麼叫父類引用指向子類對象?看下面例子吧
有兩個類,Father 是父類,Son 類繼承自 Father。
第 1 個例子:
// f1 引用指向一個Son對象
Father f1 = new Son(); // 這就叫 upcasting (向上轉型)
// f1 還是指向 Son對象
Son s1 = (Son)f1; // 這就叫 downcasting (向下轉型)
第 2 個例子:
// f1現在指向father對象
Father f2 = new Father();
Son s2 = (Son)f2; // 出錯,子類引用不能指向父類對象
你或許會問,第1個例子中:Son s1 = (Son)f1; 為什麼是正確的呢。很簡單因為 f1 指向一個子類對象,Father f1 = new Son(); 子類 s1 引用當然可以指向子類對象了。
而 f2 被傳給了一個 Father 對象,Father f2 = new Father(); 子類 s2 引用不能指向父類對象。
10、 多態與構造器之間的微妙
直接上代碼:
package Polymorphic;
class EatKaoShanYao {
EatKaoShanYao () {
System.out.println("吃烤山藥之前...");
eat();
System.out.println("吃烤山藥之後(熊孩子懵逼中)....");
}
public void eat() {
System.out.println("7歲半就喜歡吃烤山藥");
}
}
public class KaoShanYao extends EatKaoShanYao {
private String Weight = "110斤";
public KaoShanYao(String Weight) {
this.Weight = Weight;
System.out.println("熊孩子的體重:" + this.Weight);
}
public void eat() { // 子類覆蓋父類方法
System.out.println("熊孩子吃烤山藥之前的體重是:" + this.Weight);
}
//Main方法
public static void main(String[] args) {
EatKaoShanYaok = new KaoShanYao("250斤");
}
}
童鞋們可以試想一下運行結果,再看下面的輸出結果
運行結果:
吃烤山藥之前...
熊孩子吃烤山藥之前的體重是:null
吃烤山藥之後(熊孩子懵逼中)....
熊孩子的體重:250斤
是不是很疑惑?結果為啥是這樣?你看,熊孩子又懵逼了,Why?
原因其實很簡單,因為在創建子類對象時,會先去調用父類的構造器,而父類構造器中又調用了被子類覆蓋的多態方法,由於父類並不清楚子類對象中的屬性值是什麼(先初始化父類的時候還沒開始初始化子類),於是把String類型的屬性暫時初始化為默認值null,然後再調用子類的構造器(這個時子類構造器已經初始Weight屬性,所以子類構造器知道熊孩子的體重Weight是250)。
如果有什麼不理解的可以及時告訴我,樓主一直都在,還有如果樓主哪裡寫錯了或者理解錯了,請及時告訴我,一定要告訴我!!!
11、 多態的優點
講了這麼久的多態,我覺得其優點已經不明覺厲了。但是還是來聊聊多態在實際開發的過程中的優點。在實際開發中父類類型作為方法形式參數,傳遞子類對象給方法,進行方法的調用,更能體現出多態的擴展 性與便利。
為了更好的對比出多態的優點,下面程序不使用多態,代碼如下:
package Demo;
//父類:動物類
class Animal{
public void eat(){
System.out.println("eat");
}
}
//貓類
class Cat {
//方法重寫
public void eat(){
System.out.println("貓吃貓骨頭");
}
public void call(){
System.out.println("貓叫");
}
}
//狗類
class Dog {
public void eat(){
System.out.println("狗吃狗骨頭");
}
public void call(){
System.out.println("狗叫");
}
}
//針對動物操作的工具類
class AnimalTool{
private AnimalTool(){}//把工具類的構造方法私有,防止別人創建該類的對象。
//調用貓的功能
public static void catLife(Cat c){ //工具類,方法就寫成static的,然後直接在測試類:工具類名.方法 使用。
c.eat();
c.call();
}
//調用狗的功能
public static void dogLife(Dog d){
d.eat();
d.call();
}
}
public class Test{
public static void main(String[] args){
Cat c= new Cat();
AnimalTool.catLife(c);
Dog d= new Dog();
AnimalTool.dogLife(d);
}
}
運行結果:
貓吃貓骨頭
貓叫
狗吃狗骨頭
狗叫
這裏只寫了兩隻動物,如果再來一種動物豬,則需要定義個豬類,提供豬的兩個方法,再到工具類中添加對應的XXLife方法,這三步都是必須要做的,而且每多一種動物就需要在工具類中添加一種一個對應的XXLife方法,這樣維護起來就很麻煩了,畢竟動物種類成千上萬!崩潰吧,沒事多態來拯救你,如下使用多態代碼:
package Demo;
//父類:動物類
class Animal{
public void eat(){
System.out.println("eat");
}
public void call(){
System.out.println("call");
}
}
//貓類
class Cat extends Animal {
//方法重寫
public void eat(){
System.out.println("貓吃貓骨頭");
}
public void call(){
System.out.println("貓叫");
}
}
//狗類
class Dog extends Animal {
public void eat(){
System.out.println("狗吃狗骨頭");
}
public void call(){
System.out.println("狗叫");
}
}
//針對動物操作的工具類
class AnimalTool{
private AnimalTool(){}//最好把工具類的構造方法私有,防止別人創建該類的對象。該類是工具類。
//調用所以動物的功能
public static void animalLife(Animal a){ //工具類,方法就寫成static的,然後直接在測試類:工具類名.方法 使用。
a.eat();
a.call();
}
}
public class Test{
public static void main(String[] args){
Cat c= new Cat();
AnimalTool.animalLife(c);
Dog d= new Dog();
AnimalTool.animalLife(d);
運行結果:
貓吃貓骨頭
貓叫
狗吃狗骨頭
狗叫
}
}
注意: 上面動物類都繼承了animal父類
這個時候再分析,如果再來一種動物豬,則需要定義個豬類,提供豬的兩個方法,再繼承Animal父類,這個時候就不需要在工具類中添加對應的XxLife方法,只寫一個animalLife方法即可,而且每多一種動物都不需要在工具類中添加對應的XxLife方法,這樣維護起來就很樂觀了。
由於多態特性的支持,animalLife方法的Animal類型,是Cat和Dog的父類類型,父類類型接收子類對象,當 然可以把Cat對象和Dog對象傳遞給方法。 當eat和call方法執行時,多態規定,執行的是子類重寫的方法,那麼效果自然與Animal的子類中的eat、call方法一致, 所以animalLife完全可以替代以上兩方法。 不僅僅是替代,在擴展性方面,無論之後再多的子類出現,我們都不需要編寫XxLife方法了,直接使用 animalLife就可以完成。 所以,多態的好處,體現在可以使程序編寫的更簡單,並有良好的擴展。
12、 分析開篇的九個問題
看到這裏,相信童鞋們多多少少都應該對多態都一定的了解了,都應該很有信心解決開篇的難題了吧,我可以很負責的告訴你,文章看到這裏,你依舊解決不了這幾個問題,不要問我為啥知道,你可以試着再做一遍,代碼貼在下面:
package Polymorphic;
//爺爺類
class Ye {
public String show(Sun obj) {
return ("Ye and Sun");
}
public String show(Ye obj) {
return ("Ye and Ye");
}
}
//爸爸類
class Fu extends Ye {
public String show(Fu obj) {
return ("Fu and Fu");
}
public String show(Ye obj) {
return ("Fu and Ye");
}
}
//兒子類
class Zi extends Fu {
}
//孫子類
class Sun extends Fu {
}
public class PolymorphicTest {
public static void main(String[] args) {
Ye y = new Ye();
Ye y2 = new Fu(); //向上
Fu f = new Fu();
Zi z = new Zi();
Sun s = new Sun();
System.out.println("第一題 " + y.show(f));
System.out.println("第二題 " + y.show(z));
System.out.println("第三題 " + y.show(s));
System.out.println("第四題 " + y2.show(f)); //到這裏掛了???
System.out.println("第五題 " + y2.show(z));
System.out.println("第六題 " + y2.show(s));
System.out.println("第七題 " + f.show(f));
System.out.println("第八題 " + f.show(z));
System.out.println("第九題 " + f.show(s));
}
打印結果:
第一題 Ye and Ye
第二題 Ye and Ye
第三題 Ye and Sun
第四題 Fu and Ye
第五題 Fu and Ye
第六題 Ye and Sun
第七題 Fu and Fu
第八題 Fu and Fu
第九題 Ye and Sun
}
要想理解上面這個例子,童鞋們必須讀懂這句話:當父類對象引用變量引用子類對象時,被引用對象的類型決定了調用誰的成員方法,引用變量類型決定可調用的方法。首先會先去可調用的方法的父類中尋找,找到了就執行子類中覆蓋的該方法,就算子類中有現成的該方法,它同樣也會去父類中尋找,早到后未必執行子類中有現成的方法,而是執行重寫在父類中找到的方法的子類方法(這裏的子類也就是最後決定調用的類方法)。你是不是暈了?讀着都覺得拗口,要理解可就拗的不是口了而是拗頭 ~啥玩意沒聽過這個詞~ 咳咳,問題不大,樓主來通俗的給大家講解,讓大家理解。
還記不記得樓主之前定義向上轉型是怎麼定義的?
【v8提示】 向上轉型:多態本身是子類類型向父類類型向上轉換的過程,其中,這個過程是默認的。你可以把這個過程理解為基本類型的小類型轉大類型自動轉換,不需要強制轉換。 當父類引用指向一個子類對象時,便是向上轉型
可是,你真的理解了咩?什麼叫做父類對象引用變量引用子類對象?其實還得從下面這句話找頭緒
向上轉型定義:多態本身是子類類型向父類類型向上轉換的過程,其中,這個過程是默認的
就好比Father f = new Son();有的童鞋就會說這個f也算是父類的對象引用?如果按字面理解是子類的引用只不過該引用的類型為Father類型?這時你就大錯特錯了。
我們把向上轉型定義簡化一下理解一下,簡化如下:
子類類型默認向父類類型向上轉換的過程
現在明白了咩?這句話可以理解為Father f = new Son()這句代碼原本是Father f = (Father )new Son()這樣子的只是這個轉換過程是默認自動轉的,總的來說也就是 new Son()其實本質就是new Father,所以f其實就是父類對象引用!這個時候再來拆開理解下面這段話
當父類對象引用變量引用子類對象時
其中父類對象引用變量指的就是f,子類對象指的就是new Son(),所以加起來就是當f引用new Son()時
被引用對象的類型決定了調用誰的成員方法,引用變量類型決定可調用的方法。
這裏的 被引用對象的類型則是指new Son()對象中的Son類型, 引用變量類型則是指f的類型Father類型
好了總結關聯起來就是當:f引用new Son()時,Son決定了調用它的成員方法,Father決定可調用Father中的方法。所以以Father f = new Son()舉例,簡單來說就是
13、 最後我們一起來正式分析那九個題
前三個並沒有涉及到多態(向上轉型),所以只會調用yeye本類的方法,這裏只要掌握繼承的知識就OK了。
講解第四題之前,你的答案是不是"Fu and Fu"?來了喔,馬上讓你巔覆對多態的人生觀!
分析第四題,首先Ye y2 = new Fu(); 向上轉型了,所以首先會去Fu類的父類Ye類中找show(f)方法,找到了show(Ye obj)方法,之後回到Fu類中看是否有show(Ye obj)重寫方法,發現Fu類有show(Ye obj)方法(重寫),所以最後執行了"Fu and Ye",你get了咩?
分析第五題,其實第五題和第四題基本差不多,第四題是y2.show(f);第五題是y2.show(z);只是show的方法參數不同,相同的是f和z在Ye類中找的都是show(Ye obj)方法,所以,最終第四題和第五題結果一致!
分析第六題,第六題其實挺有趣,首先y2.show(s),到Ye類中找到show(Sun obj),之後在子類中看有沒有重寫,發現並沒有show(Sun obj)重寫方法,確定沒有咩?別忘了這是繼承,子類Fu中默認有着父類Ye的方法,只是沒有表面表示出來,從另一角度出發,Fu類中默認重寫了一個show(Sun obj)方法,就算不寫也是存在的,所以運行結果為"Ye and Sun"
第七、八題就不分析了,畢竟也沒有涉及到向上轉型(多態)。
最後分析一下第九題,有的童鞋就要打樓主了,第九題不也是沒有涉及到向上轉型(多態)嗎,樓主你個星星(**),當然,樓主就算背着黑鍋也要分析第九題~就是這麼傲嬌~,確實沒有涉及到向上轉型(多態),我要講的原因很簡單,因為我覺得還是很有必要!首先f.show(s)不涉及多態,它只會調用自己類(Fu)的方法,但是你會發現Fu中並沒有show(s),唉唉唉,我運行你重新組織下語言,又忘了?這是繼承啊,它有默認父類Ye中的show(Sun obj)方法鴨!好了到這裏,我總結出一點,你多態以及沒得問題了,不過你繼承方面知識薄弱啊,不行不行樓主得給你補補,還在猶豫什麼鴨,快來補補繼承知識!!!
本文的最後,我只是個人對多態的理解,樓主只是個java小白,叫我老白也行,不一定全部正確,如果有什麼錯誤請一定要告訴我,感激不盡感激不盡感激不盡!!!歡迎指正~
最後的最後,如果本文對你有所幫助就點個愛心支持一下吧 ~佛系報大腿~
歡迎各位關注我的公眾號,一起探討技術,嚮往技術,追求技術…
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※想知道網站建置、網站改版該如何進行嗎?將由專業工程師為您規劃客製化網頁設計及後台網頁設計
※不管是台北網頁設計公司、台中網頁設計公司,全省皆有專員為您服務
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※帶您來看台北網站建置,台北網頁設計,各種案例分享