導讀:本文主要介紹了高德在服務單元化建設方面的一些實踐經驗,服務單元化建設面臨很多共性問題,如請求路由、單元封閉、數據同步,有的有成熟方案可以借鑒和使用,但不同公司的業務不盡相同,要盡可能的結合業務特點,做相應的設計和處理。
一、為什麼要做單元化
- 單機房資源瓶頸
隨着業務體量和服務用戶群體的增長,單機房或同城雙機房無法支持服務的持續擴容。
- 服務異地容災
異地容災已經成為核心服務的標配,有的服務雖然進行了多地多機房部署,但數據還是只在中心機房,實現真正意義上的異地多活,就需要對服務進行單元化改造。
二、高德單元化的特點
在做高德單元化項目時,我們首先要考慮的是結合高德的業務特點,看高德的單元化有什麼不一樣的訴求,這樣就清楚哪些經驗和方案是可以直接拿來用的,哪些又是需要我們去解決的。
高德業務和傳統的在線交易業務還是不太一樣,高德為用戶提供以導航為代表的出行服務,很多業務場景對服務的RT要求會很高,所以在做單元化方案時,盡可能減少對整體服務RT的影響就是我們需要重點考慮的問題,盡量做到數據離用戶近一些。轉換到單元化技術層面需要解決兩個問題:
1.用戶設備的單元接入需要盡可能的做到就近接入,用戶真實地理位置接近哪個單元就接入哪個單元,如華北用戶接入到張北,華南接入到深圳。
2.用戶的單元劃分最好能與就近接入的單元保持一致,減少單元間的跨單元路由。如用戶請求從深圳進來,用戶的單元劃分最好就在深圳單元,如果劃到張北單元就會造成跨單元路由。
另外一個區別就是高德很多業務是無須登錄的,所以我們的單元化方案除了用戶ID也要支持基於設備ID。
三、高德單元化實踐
服務的單元化架構改造需要一個至上而下的系統性設計,核心要解決請求路由、單元封閉、數據同步三方面問題。
請求路由:根據高德業務的特點,我們提供了取模路由和路由表路由兩種策略,目前上線應用使用較多的是路由表路由策略。
單元封閉:得益於集團的基礎設施建設,我們使用vipserver、hsf等服務治理能力保證服務同機房調用,從而實現單元封閉(hsf unit模式也是一種可行的方案,但個人認為同機房調用的架構和模式更簡潔且易於維護)。
數據同步:數據部分使用的是集團DB產品提供的DRC數據同步。
單元路由服務採用什麼樣的部署方案是我們另一個要面臨的問題,考慮過以下三種方案:
第一種SDK的方式因為對業務的強侵入性是首先被排除的,統一接入層進行代理和去中心化插件集成兩種方案各有利弊,但當時首批要接入單元化架構的服務很多都還沒有統一接入到gateway,所以基於現狀的考慮使用了去中心化插件集成的方式,通過在應用的nginx集成UnitRouter。
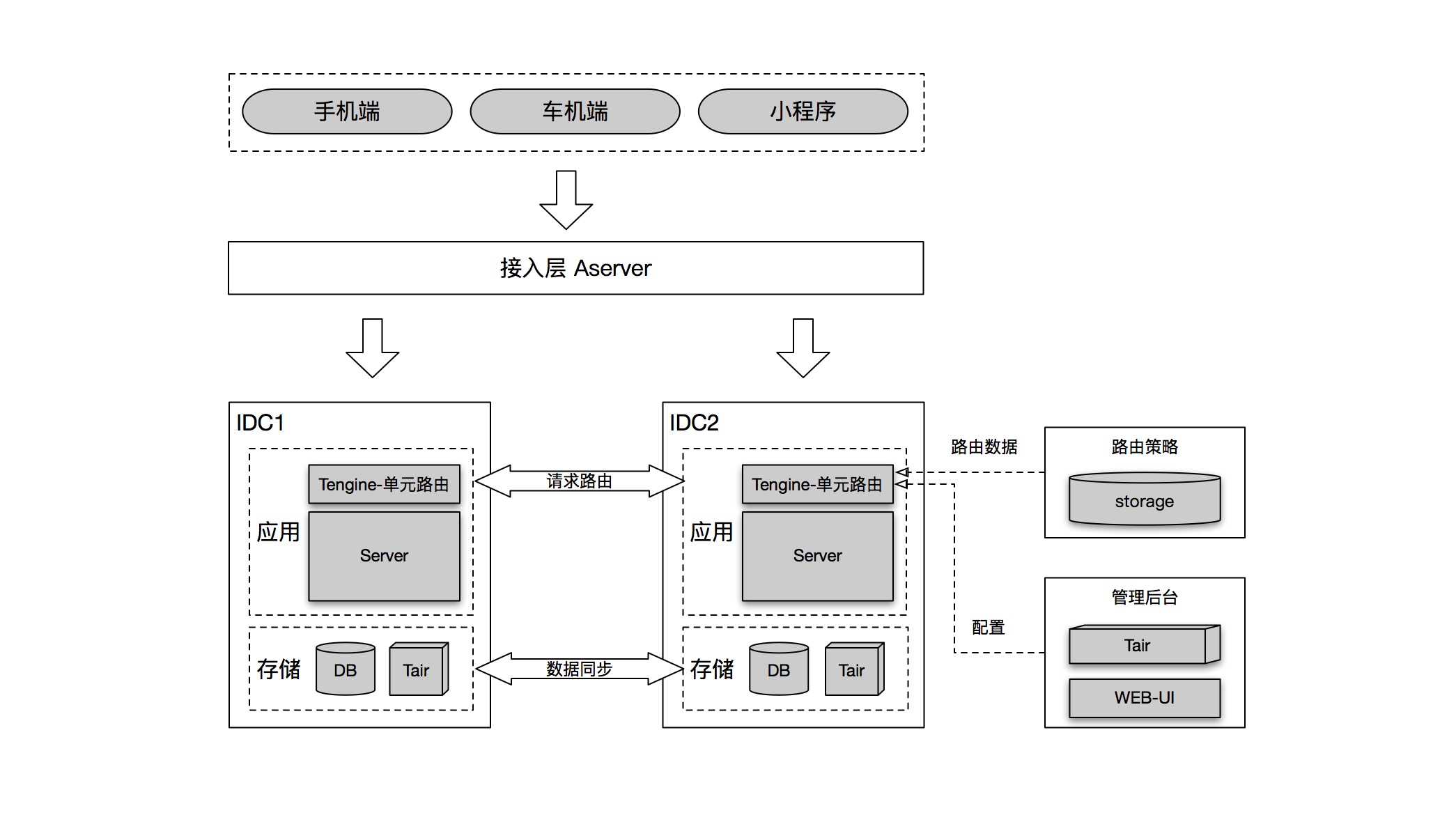
服務單元化架構
目前高德賬號,雲同步、用戶評論系統都完成了單元化改造,採用三地四機房部署,寫入量較高的雲同步服務,單元寫高峰能達到數w+QPS (存儲是mongodb集群)。
以賬號系統為例介紹下高德單元化應用的整體架構。
賬號系統服務是三地四機房部署,數據分別存儲在tair為代表的緩存和XDB里,數據存儲三地集群部署、全量同步。賬號系統服務器的Tengine上安裝UntiRouter,它請求的負責單元識別和路由,用戶單元劃分是通過記錄用戶與單元關係的路由表來控制。
PS:因歷史原因緩存使用了tair和自建的uredis(在redis基礎上添加了基於log的數據同步功能),目前已經在逐步統一到tair。數據同步依賴tair和alisql的數據同步方案,以及自建的uredis數據同步能力。
就近接入實現方案
為滿足高德業務低延時要求,就要想辦法做到數據(單元)離用戶更近,其中有兩個關鍵鏈路,一個是通過aserver接入的外網連接,另一個是服務內部路由(盡可能不產生跨單元路由)。
措施1:客戶端的外網接入通過aserver上的配置,將不同地理區域(七個大區)的設備劃分到對應近的單元,如華北用戶接入張北單元。
措施2:通過記錄用戶和單元關係的路由表來劃分用戶所屬單元,這個關係是通過系統日誌分析出來的,用戶經常從哪個單元入口進來,就會把用戶劃分到哪個單元,從而保證請求入口和單元劃分的相對一致,從而減少跨單元路由。
所以,在最終的單元路由實現上我們提供了傳統的取模路由,和為降延時而設計的基於路由表路由兩種策略。同時,為解無須登錄的業務場景問題,上述兩種策略除了支持用戶ID,我們同時也支持設備ID。
路由表設計
路由表分為兩部分,一個是用戶-分組的關係映射表,另一個是分組-單元的關係映射表。在使用時,通過路由表查對應的分組,再通過分組看用戶所屬單元。分組對應中國大陸的七個大區。
先看“用戶-(大區)分組”:
路由表是定期通過系統日誌分析出來的,看用戶最近IP屬於哪個大區就劃分進哪個分組,同時也對應上了具體單元。當一個北京的用戶長期去了深圳,因IP的變化路由表更新后將划進新大區分組,從而完成用戶從張北單元到深圳單元的遷移。
再看“分組-單元”:
分組與單元的映射有一個默認關係,這是按地理就近來配置的,比如華南對應深圳。除了默認的映射關係,還有幾個用於切流預案的關係映射。
老用戶可以通過路由表來查找單元,新用戶怎麼辦?對於新用戶的處理我們會降級成取模的策略進行單元路由,直至下次路由表的更新。所以整體上看新用戶跨單元路由比例肯定是比老用戶大的多,但因為新用戶是一個相對穩定的增量,所以整體比例在可接受範圍內。
路由計算
有了路由表,接下來就要解工程化應用的問題,性能、空間、靈活性和準確率,以及對服務穩定性的影響這幾個方面是要進行綜合考慮的,首先考慮外部存儲會增加服務的穩定性風險,後面我們在BloomFilter 、BitMap和MapDB多種方案中選擇BloomFilter,萬分之幾的誤命中率導致的跨單元路由在業務可接受範圍內。
通過日誌分析出用戶所屬大區后,我們將不同分組做成多個布隆過濾器,計算時逐層過濾。這個計算有兩種特殊情況:
1) 因為BloomFilter存在誤算率,有可能存在一種情況,華南分組的用戶被計算到華北了,這種情況比例在萬分之3 (生成BloomFilter時可調整),它對業務上沒有什麼影響,這類用戶相當於被劃分到一個非所在大區的分組裡,但這個關係是穩定的,不會影響到業務,只是存在跨單元路由,是可接受的。
2) 新用戶不在分組信息里,所以經過逐層的計算也沒有匹配到對應大區分組,此時會使用取模進行模除分組的計算。
如果業務使用的是取模路由而非路由表路由策略,則直接根據tid或uid計算對應的模除分組,原理簡單不詳表了。
單元切流
在發生單元故障進行切流時,主要分為四步驟
打開單元禁寫 (跨單元寫不敏感業務可以不配置)
檢查業務延時
切換預案
解除單元禁寫
PS:更新路由表時,也需要上述操作,只是第3步的切換預案變成切換新版本路由表;單元禁寫主要是了等待數據同步,避免數據不一致導致的業務問題。
核心指標
單元計算耗時1~2ms
跨單元路由比例底於5%
除了性能外,因就近接入的訴求,跨單元路由比例也是我們比較關心的重要指標。從線上觀察看,路由表策略單元計算基本上在1、2ms內完成,跨單元路由比例3%左右,整體底於5%。
四、後續優化
統一接入集成單元化能力
目前大部分服務都接入了統一接入網關服務,在網關集成單元化能力將大大減少服務單元化部署的成本,通過簡單的配置就可以實現單元路由,服務可將更多的精力放在業務的單元封閉和數據同步上。
分組機制的優化
按大區分組存在三個問題:
通過IP計算大區有一定的誤算率,會導致部分用戶劃分錯誤分組。
分組粒度太大,單元切流時流量不好分配。舉例,假如華東是我們用戶集中的大區,切流時把這個分組切到任意一個指定單元,都會造成單元服務壓力過大。
計算次數多,分多少個大區,理論最大計算次數是有多少次,最後採取取模策略。
針對上述幾個問題我們計劃對分組機製做如下改進
通過用戶進入單元的記錄來確認用戶所屬單元,而非根據用戶IP所在大區來判斷,解上述問題1。
每個單元劃分4個虛擬分組,支持更細粒度單元切流,解上述問題2。
用戶確實單元后,通過取模來劃分到不同的虛擬分組。每個單元只要一次計算就能完成,新用戶只需經過3次計算,解上述問題3。
熱更時的雙表計算
與取模路由策略不同,路由表策略為了把跨單元路由控制在一個較好的水平需要定期更新,目前更新時需要一個短暫的單元禁寫,這對於很多業務來說是不太能接受的。
為優化這個問題,系統將在路由表更新時做雙(路由)表計算,即將新老路由表同時加載進內存,更新時不再對業務做完全的禁寫,我們會分別計算當前用戶(或設備)在新老路由表的單元結果,如果單元一致,則說明路由表的更新沒有導致該用戶(或設備)變更單元,所以請求會被放行,相反如果計算結果是不同單元,說明發生了單元變更,該請求會被攔截,直至到達新路由表的一個完全起用時間。
優化前服務會完全禁寫比如10秒(時間取決於數據同步時間),優化後會變成觸髮禁寫的是這10秒內路由發生變更的用戶,這將大大減少對業務的影響。
服務端數據驅動的單元化場景
前面提到高德在路由策略上結合業務的特別設計,但整體單元劃分還是以用戶(或設備)為維度來進行的,但高德業務還有一個大的場景是我們未來要面對和解決的,就是以數據維度驅動的單元設計,基於終端的服務路由會變成基於數據域的服務路由。
高德很多服務是以服務數據為核心的,像地圖數據等它並非由用戶直接產生。業務的發展數據存儲也將不斷增加,包括5G和自動駕駛,對應數據的爆髮式增長單點全量存儲並不實現,以服務端數據驅動的服務單元化設計,是我們接下來要考慮的重要應用場景。
寫在最後
不同的業務場景對單元化會有不同的訴求,我們提供不同的策略和能力供業務進行選擇,對於多數據服務我們建議使用業務取模路由,簡單且易於維護;對於RT敏感的服務使用路由表的策略來盡可能的降低服務響應時長的影響。另外,要注意的是強依賴性的服務要採用相同的路由策略。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想要讓你的商品成為最夯、最多人討論的話題?網頁設計公司讓你強力曝光
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
![從壹開始 [ Design Pattern ] 之二 ║ 單例模式 與 Singleton](https://www.3chy5.com/wp-content/uploads/2020/02/b00a2afb89975d1f04b2475795b635d3.jpg)