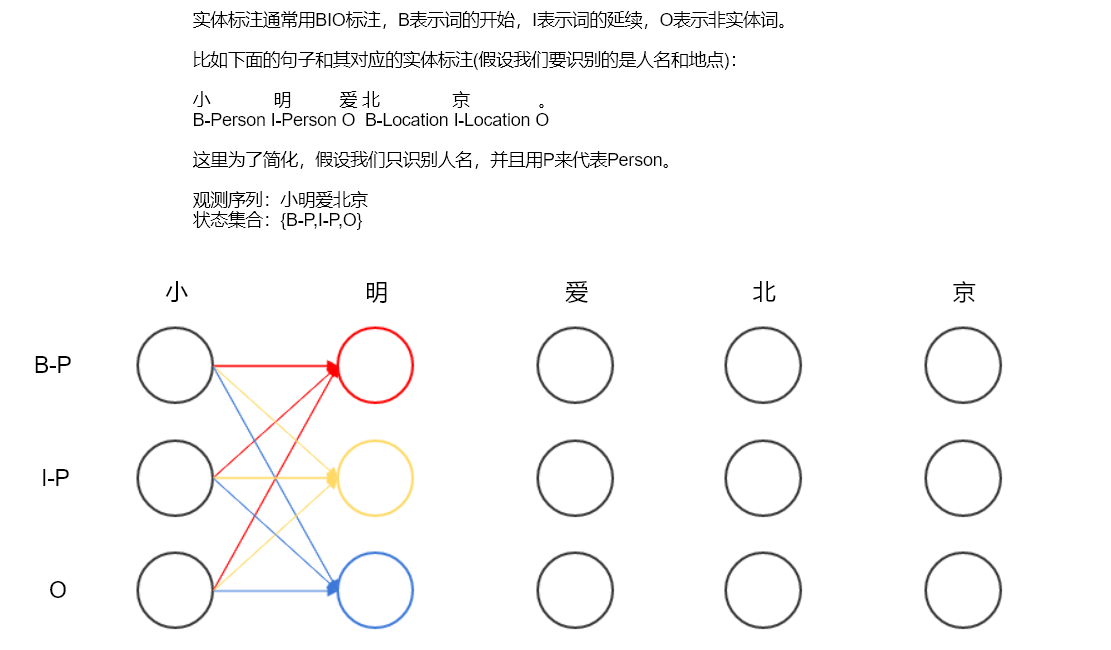
1. goroutine的使用
在Go語言中,表達式go f(x, y, z)會啟動一個新的goroutine運行函數f(x, y, z),創建一個併發任務單元。即go關鍵字可以用來開啟一個goroutine(協程))進行任務處理。
創建單個goroutine
1 package main 2 3 import ( 4 "fmt" 5 ) 6 7 func HelloWorld() { 8 fmt.Println("Hello goroutine") 9 } 10 11 func main() { 12 go HelloWorld() // 開啟一個新的併發運行
time.Sleep(1*time.Second) 13 fmt.Println("后輸出消息!") 14 }
輸出
1 Hello goroutine 2 后輸出消息!
這裏的sleep是必須的,否則你可能看不到goroutine裡頭的輸出,或者裏面的消息后輸出。因為當main函數返回時,所有的gourutine都是暴力終結的,然後程序退出。
創建多個goroutine時
1 package main 2 3 import ( 4 "fmt" 5 "time" 6 ) 7 8 func DelayPrint() { 9 for i := 1; i <= 3; i++ { 10 time.Sleep(500 * time.Millisecond) 11 fmt.Println(i) 12 } 13 } 14 15 func HelloWorld() { 16 fmt.Println("Hello goroutine") 17 } 18 19 func main() { 20 go DelayPrint() // 第一個goroutine 21 go HelloWorld() // 第二個goroutine 22 time.Sleep(10*time.Second) 23 fmt.Println("main func") 24 }
輸出
1 Hello goroutine 2 1 3 2 4 3 5 4 6 7 main func
當去掉 DelayPrint() 函數里的sleep之後,輸出為:
1 1 2 2 3 3 4 4 5 Hello goroutine 6 main function
說明第二個goroutine不會因為第一個而堵塞或者等待。事實是當程序執行go FUNC()的時候,只是簡單的調用然後就立即返回了,並不關心函數裡頭發生的故事情節,所以不同的goroutine直接不影響,main會繼續按順序執行語句。
goroutine阻塞
場景一:
1 package main 2 3 func main() { 4 ch := make(chan int) 5 <- ch // 阻塞main goroutine, 通道被鎖 6 }
運行程序會報錯:
1 fatal error: all goroutines are asleep - deadlock! 2 3 goroutine 1 [chan receive]: 4 main.main()
場景二
1 package main 2 3 func main() { 4 ch1, ch2 := make(chan int), make(chan int) 5 6 go func() { 7 ch1 <- 1 // ch1通道的數據沒有被其他goroutine讀取走,堵塞當前goroutine 8 ch2 <- 0 9 }() 10 11 <- ch2 // ch2 等待數據的寫 12 }
非緩衝通道上如果只有數據流入,而沒有流出,或者只流出無流入,都會引起阻塞。 goroutine的非緩衝通道裡頭一定要一進一出,成對出現。 上面例子,一:流出無流入;二:流入無流出。
處理方式:
1. 讀取通道數據
1 package main 2 3 func main() { 4 ch1, ch2 := make(chan int), make(chan int) 5 6 go func() { 7 ch1 <- 1 // ch1通道的數據沒有被其他goroutine讀取走,堵塞當前goroutine 8 ch2 <- 0 9 }() 10 11 <- ch1 // 取走便是 12 <- ch2 // chb 等待數據的寫 13 }
2. 創建緩衝通道
1 package main 2 3 func main() { 4 ch1, ch2 := make(chan int, 3), make(chan int) 5 6 go func() { 7 ch1 <- 1 // cha通道的數據沒有被其他goroutine讀取走,堵塞當前goroutine 8 ch2 <- 0 9 }() 10 11 <- ch2 // ch2 等待數據的寫 12 }
2. goroutine調度器相關結構
goroutine的調度涉及到幾個重要的數據結構,我們先逐一介紹和分析這幾個數據結構。這些數據結構分別是結構體G,結構體M,結構體P,以及Sched結構體。前三個的定義在文件runtime/runtime.h中,而Sched的定義在runtime/proc.c中。Go語言的調度相關實現也是在文件proc.c中。
2.1 結構體G
g是goroutine的縮寫,是goroutine的控制結構,是對goroutine的抽象。看下它內部主要的一些結構:
1 type g struct { 2 //堆棧參數。 3 //堆棧描述了實際的堆棧內存:[stack.lo,stack.hi)。 4 // stackguard0是在Go堆棧增長序言中比較的堆棧指針。 5 //通常是stack.lo + StackGuard,但是可以通過StackPreempt觸發搶佔。 6 // stackguard1是在C堆棧增長序言中比較的堆棧指針。 7 //它是g0和gsignal堆棧上的stack.lo + StackGuard。 8 //在其他goroutine堆棧上為〜0,以觸發對morestackc的調用(並崩潰)。
9 //當前g使用的棧空間,stack結構包括 [lo, hi]兩個成員 10 stack stack // offset known to runtime/cgo
11 // 用於檢測是否需要進行棧擴張,go代碼使用 12 stackguard0 uintptr // offset known to liblink
13 // 用於檢測是否需要進行棧擴展,原生代碼使用的 14 stackguard1 uintptr // offset known to liblink
15 // 當前g所綁定的m 16 m *m // current m; offset known to arm liblink
17 // 當前g的調度數據,當goroutine切換時,保存當前g的上下文,用於恢復 18 sched gobuf
19 // goroutine運行的函數 20 fnstart *FuncVal 21 // g當前的狀態 22 atomicstatus uint32 23 // 當前g的id 24 goid int64
25 // 狀態Gidle,Grunnable,Grunning,Gsyscall,Gwaiting,Gdead 26 status int16
27 // 下一個g的地址,通過guintptr結構體的ptr set函數可以設置和獲取下一個g,通過這個字段和sched.gfreeStack sched.gfreeNoStack 可以把 free g串成一個鏈表 28 schedlink guintptr
29 // 判斷g是否允許被搶佔 30 preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
31 // g是否要求要回到這個M執行, 有的時候g中斷了恢復會要求使用原來的M執行 32 lockedm muintptr
33 // 用於傳遞參數,睡眠時其它goroutine設置param,喚醒時此goroutine可以獲取
param *void
34 // 創建這個goroutine的go表達式的pc 35 uintptr gopc 36 }
其中包含了棧信息stackbase和stackguard,有運行的函數信息fnstart。這些就足夠成為一個可執行的單元了,只要得到CPU就可以運行。goroutine切換時,上下文信息保存在結構體的sched域中。goroutine切換時,上下文信息保存在結構體的sched域中。goroutine是輕量級的線程或者稱為協程,切換時並不必陷入到操作系統內核中,很輕量級。
結構體G中的Gobuf,其實只保存了當前棧指針,程序計數器,以及goroutine自身。
1 struct Gobuf 2 { 3 //這些字段的偏移是libmach已知的(硬編碼的)。 4 sp uintper; 5 pc *byte; 6 g *G; 7 ... 8 };
記錄g是為了恢復當前goroutine的結構體G指針,運行時庫中使用了一個常駐的寄存器extern register G* g,這是當前goroutine的結構體G的指針。這種結構是為了快速地訪問goroutine中的信息,比如,Go的棧的實現並沒有使用%ebp寄存器,不過這可以通過g->stackbase快速得到。”extern register”是由6c,8c等實現的一個特殊的存儲,在ARM上它是實際的寄存器。在linux系統中,對g和m使用的分別是0(GS)和4(GS)。鏈接器還會根據特定操作系統改變編譯器的輸出,每個鏈接到Go程序的C文件都必須包含runtime.h頭文件,這樣C編譯器知道避免使用專用的寄存器。
2.2 結構體P
P是Processor的縮寫。結構體P的加入是為了提高Go程序的併發度,實現更好的調度。M代表OS線程。P代表Go代碼執行時需要的資源。
1 type p struct { 2 lock mutex 3 4 id int32 5 // p的狀態,稍後介紹 6 status uint32 // one of pidle/prunning/... 7 8 // 下一個p的地址,可參考 g.schedlink 9 link puintptr 10 // p所關聯的m 11 m muintptr // back-link to associated m (nil if idle) 12 13 // 內存分配的時候用的,p所屬的m的mcache用的也是這個 14 mcache *mcache 15 16 // Cache of goroutine ids, amortizes accesses to runtime·sched.goidgen. 17 // 從sched中獲取並緩存的id,避免每次分配goid都從sched分配 18 goidcache uint64 19 goidcacheend uint64 20 21 // Queue of runnable goroutines. Accessed without lock. 22 // p 本地的runnbale的goroutine形成的隊列 23 runqhead uint32 24 runqtail uint32 25 runq [256]guintptr 26 27 // runnext,如果不是nil,則是已準備好運行的G 28 //當前的G,並且應該在下一個而不是其中運行 29 // runq,如果運行G的時間還剩時間 30 //切片。它將繼承當前時間剩餘的時間 31 //切片。如果一組goroutine鎖定在 32 //交流等待模式,該計劃將其設置為 33 //單位並消除(可能很大)調度 34 //否則會由於添加就緒商品而引起的延遲 35 // goroutines到運行隊列的末尾。 36 37 // 下一個執行的g,如果是nil,則從隊列中獲取下一個執行的g 38 runnext guintptr 39 40 // Available G's (status == Gdead) 41 // 狀態為 Gdead的g的列表,可以進行復用 42 gfree *g 43 gfreecnt int32 44 }
跟G不同的是,P不存在waiting狀態。MCache被移到了P中,但是在結構體M中也還保留着。在P中有一個Grunnable的goroutine隊列,這是一個P的局部隊列。當P執行Go代碼時,它會優先從自己的這個局部隊列中取,這時可以不用加鎖,提高了併發度。如果發現這個隊列空了,則去其它P的隊列中拿一半過來,這樣實現工作流竊取的調度。這種情況下是需要給調用器加鎖的。
2.3 結構體M
M是machine的縮寫,是對機器的抽象,每個m都是對應到一條操作系統的物理線程。
1 type m struct { 2 // g0是用於調度和執行系統調用的特殊g 3 g0 *g // goroutine with scheduling stack 4 // m當前運行的g 5 curg *g // current running goroutine 6 // 當前擁有的p 7 p puintptr // attached p for executing go code (nil if not executing go code)
8 // 線程的 local storage 9 tls [6]uintptr // thread-local storage 10 // 喚醒m時,m會擁有這個p 11 nextp puintptr 12 id int64 13 // 如果 !="", 繼續運行curg 14 preemptoff string // if != "", keep curg running on this m
15 // 自旋狀態,用於判斷m是否工作已結束,並尋找g進行工作 16 spinning bool // m is out of work and is actively looking for work
17 // 用於判斷m是否進行休眠狀態 18 blocked bool // m is blocked on a note 19 // m休眠和喚醒通過這個,note裏面有一個成員key,對這個key所指向的地址進行值的修改,進而達到喚醒和休眠的目的 20 park note
21 // 所有m組成的一個鏈表 22 alllink *m // on allm 23 // 下一個m,通過這個字段和sched.midle 可以串成一個m的空閑鏈表 24 schedlink muintptr 25 // mcache,m擁有p的時候,會把自己的mcache給p 26 mcache *mcache 27 // lockedm的對應值 28 lockedg guintptr 29 // 待釋放的m的list,通過sched.freem 串成一個鏈表 30 freelink *m // on sched.freem 31 }
和G類似,M中也有alllink域將所有的M放在allm鏈表中。lockedg是某些情況下,G鎖定在這個M中運行而不會切換到其它M中去。M中還有一個MCache,是當前M的內存的緩存。M也和G一樣有一個常駐寄存器變量,代表當前的M。同時存在多個M,表示同時存在多個物理線程。
2.4 Sched結構體
Sched是調度實現中使用的數據結構,該結構體的定義在文件proc.c中。
1 type schedt struct { 2 // 全局的go id分配 3 goidgen uint64 4 // 記錄的最後一次從i/o中查詢g的時間 5 lastpoll uint64 6 7 lock mutex 8 9 //當增加nmidle,nmidlelocked,nmsys或nmfreed時,應 10 //確保調用checkdead()。 11 12 // m的空閑鏈表,結合m.schedlink 就可以組成一個空閑鏈表了 13 midle muintptr // idle m's waiting for work 14 nmidle int32 // number of idle m's waiting for work 15 nmidlelocked int32 // number of locked m's waiting for work 16 // 下一個m的id,也用來記錄創建的m數量 17 mnext int64 // number of m's that have been created and next M ID 18 // 最多允許的m的數量 19 maxmcount int32 // maximum number of m's allowed (or die) 20 nmsys int32 // number of system m's not counted for deadlock 21 // free掉的m的數量,exit的m的數量 22 nmfreed int64 // cumulative number of freed m's 23 24 ngsys uint32 // 系統goroutine的數量;原子更新 25 26 pidle puintptr // 閑置的 27 npidle uint32 28 nmspinning uint32 // See "Worker thread parking/unparking" comment in proc.go. 29 30 // Global runnable queue. 31 // 這個就是全局的g的隊列了,如果p的本地隊列沒有g或者太多,會跟全局隊列進行平衡 32 // 根據runqhead可以獲取隊列頭的g,然後根據g.schedlink 獲取下一個,從而形成了一個鏈表 33 runqhead guintptr 34 runqtail guintptr 35 runqsize int32 36 37 // freem是m等待被釋放時的列表 38 //設置了m.exited。通過m.freelink鏈接。 39 40 // 等待釋放的m的列表 41 freem *m 42 }
大多數需要的信息都已放在了結構體M、G和P中,Sched結構體只是一個殼。可以看到,其中有M的idle隊列,P的idle隊列,以及一個全局的就緒的G隊列。Sched結構體中的Lock是非常必須的,如果M或P等做一些非局部的操作,它們一般需要先鎖住調度器。
3. G、P、M相關狀態
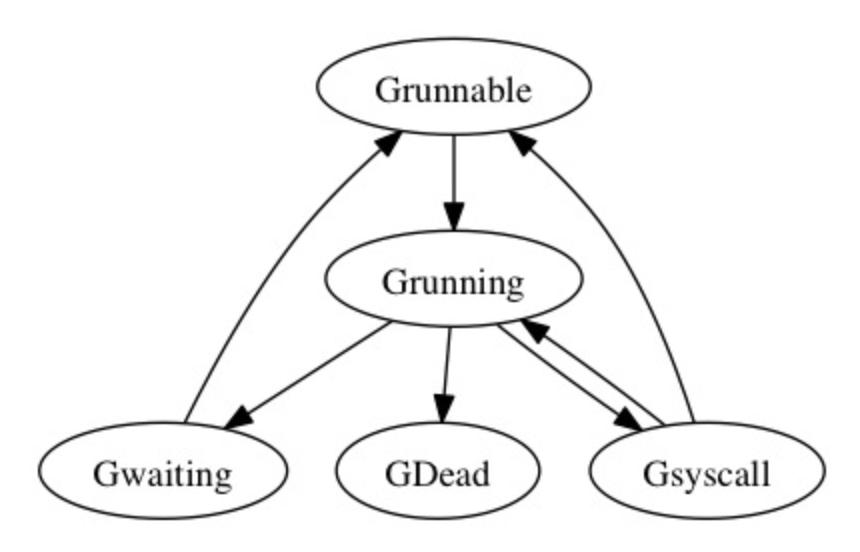
g.status
- _Gidle: goroutine剛剛創建還沒有初始化
- _Grunnable: goroutine處於運行隊列中,但是還沒有運行,沒有自己的棧
- _Grunning: 這個狀態的g可能處於運行用戶代碼的過程中,擁有自己的m和p
- _Gsyscall: 運行systemcall中
- _Gwaiting: 這個狀態的goroutine正在阻塞中,類似於等待channel
- _Gdead: 這個狀態的g沒有被使用,有可能是剛剛退出,也有可能是正在初始化中
- _Gcopystack: 表示g當前的棧正在被移除,新棧分配中
goroutine的狀態變化
在newproc1中新建的goroutine被設置為Grunnable狀態,投入運行時設置成Grunning。Grunning狀態的goroutine會在entersyscall的時候goroutine的狀態被設置為Gsyscall,到出系統調用時根據它是從阻塞系統調用中出來還是非阻塞系統調用中出來,又會被設置成Grunning或者Grunnable的狀態。在goroutine最終退出的runtime.exit函數中,goroutine被設置為Gdead狀態。還會在進行I/O時可能會進入waiting狀態,主動讓出CPU,此時會被移到所屬P中的其他G後面,等待下一次輪到執行。
p.status
- _Pidle: 空閑狀態,此時p不綁定m
- _Prunning: m獲取到p的時候,p的狀態就是這個狀態了,然後m可以使用這個p的資源運行g
- _Psyscall: 當go調用原生代碼,原生代碼又反過來調用go的時候,使用的p就會變成此態
- _Pdead: 當運行中,需要減少p的數量時,被減掉的p的狀態就是這個了
m.status
m的status沒有p、g的那麼明確,但是在運行流程的分析中,主要有以下幾個狀態
- 運行中: 拿到p,執行g的過程中
- 運行原生代碼: 正在執行原聲代碼或者阻塞的syscall
- 休眠中: m發現無待運行的g時,進入休眠,並加入到空閑列表中
- 自旋中(spining): 當前工作結束,正在尋找下一個待運行的g
4. G、P、M的調度關係
一個G就是一個gorountine,保存了協程的棧、程序計數器以及它所在M的信息。P全稱是Processor,處理器,它的主要用途就是用來執行goroutine的。M代表內核級線程,一個M就是一個線程,goroutine就是跑在M之上的。程序啟動時,會創建一個主G,而每使用一次go關鍵字也創建一個G。go func()創建一個新的G后,放到P的本地隊列里,或者平衡到全局隊列,然後檢查是否有可用的M,然後喚醒或新建一個M,M獲取待執行的G和空閑的P,將調用參數保存到g的棧,將sp,pc等上下文環境保存在g的sched域,這樣整個goroutine就準備好了,只要等分配到CPU,它就可以繼續運行,之後再清理現場,重新進入調度循環。
4.1 調度實現
圖中有兩個物理線程,M0、M1每一個M都擁有一個處理器P,每一個P都有一個正在運行的G。P的數量可以通過GOMAXPROCS()來設置,它其實也代表了真正的併發度,即有多少個goroutine可以同時運行。圖中灰色goroutine都是處於ready的就緒態,正在等待被調度。由P維護這個就緒隊列(runqueue),go function每啟動一個goroutine,runqueue隊列就在其末尾加入一個goroutine,在下一個調度點,就從runqueue中取出一個goroutine執行。
當一個OS線程M0陷入阻塞時,P轉而在M1上運行G,圖中的M1可能是正被創建,或者從線程緩存中取出。當MO返回時,它嘗試取得一個P來運行goroutine,一般情況下,它會從其他的OS線程那裡拿一個P過來執行,像M1獲取P一樣;如果沒有拿到的話,它就把goroutine放在一個global runqueue(全局運行隊列)里,然後自己睡眠(放入線程緩存里)。所有的P會周期性的檢查全局隊列並運行其中的goroutine,否則其上的goroutine永遠無法執行。
另一種情況是P上的任務G很快就執行完了(分配不均),這個處理器P很忙,但是其他的P還有任務,此時如果global runqueue也沒有G了,那麼P就會從其他的P里拿一些G來執行。一般來說,如果一般就拿run queue的一半,這就確保了每個OS線程都能充分的使用。
golang採用了m:n線程模型,即m個gorountine(簡稱為G)映射到n個用戶態進程(簡稱為P)上,多個G對應一個P,一個P對應一個內核線程(簡稱為M)。
4.2 P、M的數量
P的數量:由啟動時環境變量$GOMAXPROCS或者是由runtime的方法GOMAXPROCS()決定(默認是1)。這意味着在程序執行的任意時刻都只有$GOMAXPROCS個goroutine在同時運行。在確定了P的最大數量n后,運行時系統會根據這個數量創建n個P。
M的數量:go語言本身的限制:go程序啟動時,會設置M的最大數量,默認10000.但是內核很難支持這麼多的線程數,所以這個限制可以忽略。runtime/debug中的SetMaxThreads函數,設置M的最大數量。一個M阻塞了,會創建新的M。
M與P的數量沒有絕對關係,一個M阻塞,P就會去創建或者切換另一個M,所以,即使P的默認數量是1,也有可能會創建很多個M出來。
4.2 P、G的調度細節
P上G的調度:如果一個G不主動讓出cpu或被動block,所屬P中的其他G會一直等待順序執行。
一個G執行IO時可能會進入waiting狀態,主動讓出CPU,此時會被移到所屬P中的其他G後面,等待下一次輪到執行。 一個G調用了runtime.Gosched()會進入runnable狀態,主動讓出CPU,並被放到全局等待隊列中。 一個G調用了runtime.Goexit(),該G將會被立即終止,然後把已加載的defer(有點類似析構)依次執行完。 一個G調用了允許block的syscall,此時G及其對應的P、其他G和M都會被block起來,監控線程M會定時掃描所有P,一旦發現某個P處於block syscall狀態,則通知調度器讓另一個M來帶走P(這裏的另一個M可能是新創建的,因此隨着G被不斷block,M數量會不斷增加,最終M數量可能會超過P數量),這樣P及其餘下的G就不會被block了,等被block的M返回時發現自己的P沒有了,也就不能再處理G了,於是將G放入全局等待隊列等待空閑P接管,然後M自己sleep。 通過實驗,當一個G運行了很久(比如進入死循環),會被自動切到其他CPU核,可能是因為超過時間片后G被移到全局等待隊列中,後面被其他CPU核上的M處理。
M上P和G的調度:每當一個G要開始執行時,調度器判斷當前M的數量是否可以很好處理完G:如果M少G多且有空閑P,則新建M或喚醒一個sleep M,並指定使用某個空閑P;如果M應付得來,G被負載均衡放入一個現有P+M中。
當M處理完其身上的所有G后,會再去全局等待隊列中找G,如果沒有就從其他P中分一半的G(以便保證各個M處理G的負載大致相等),如果還沒有,M就去sleep了,對應的P變為空閑P。 在M進入sleep期間,調度器可能會給其P不斷放入G,等M醒后(比如超時):如果G數量不多,則M直接處理這些G;如果M覺得G太多且有空閑P,會先主動喚醒其他sleep的M來分擔G,如果沒有其他sleep的M,調度器創建新M來分擔。
協程特點
協程擁有自己的寄存器上下文和棧。協程調度切換時,將寄存器上下文和棧保存到其他地方,在切回來的時候,恢復先前保存的寄存器上下文和棧。因此,協程能保留上一次調用時的狀態(即所有局部狀態的一個特定組合),每次過程重入時,就相當於進入上一次調用的狀態,換種說法:進入上一次離開時所處邏輯流的位置。線程和進程的操作是由程序觸發系統接口,最後的執行者是系統;協程的操作執行者則是用戶自身程序,goroutine也是協程。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※平板收購,iphone手機收購,二手筆電回收,二手iphone收購-全台皆可收購
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
![[FPGA]淺談LCD1602字符型液晶显示器(Verilog)](https://www.3chy5.com/wp-content/uploads/2020/01/ca544059b4c1d5fec589ef8c9b934738.jpg)