※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
以設計的實用美學觀點,規劃出舒適、美觀的視覺畫面,有效提昇使用者的心理期待,營造出輕鬆、愉悅的網站瀏覽體驗。
前言
上一節我們整體概括通過MMU將虛擬地址翻譯為物理地址的轉換,這個過程都是按序就班的進行,一切都是基於已提前創建、分配虛擬頁、物理頁以及命中的前提,只是給和我一樣沒怎麼系統學習操作系統的童鞋首先在腦海里有個大概的印象,本節我們從源頭開始分析為程序創建進程到映射到主存上整個詳細過程,本文將通過大量圖解來分析原理,以便讓各位能夠完全理解地址翻譯原理。若有敘述不當之處,還請批評指正。
虛擬內存原理分析
如果沒有系統學習現代操作系統,理論上我們會認為用戶程序會將內存視為單個連續的內存空間,實際上可以將用戶程序在內存中分佈可以分散在頁面的整個物理內存中。分頁是一種內存管理方案,它允許進程的物理地址空間不連續。
物理內存劃分:將物理內存劃分為稱為幀的固定大小的塊(大小為2的冪,介於512字節和16 MB之間,必須跟蹤所有空閑幀)
虛擬(邏輯)內存劃分:將邏輯內存分成大小相同的塊(稱為頁,每一塊也是分為相同大小的頁面)
若要運行大小為N頁的程序,需要找到N個空閑幀並加載程序
地址翻譯方案
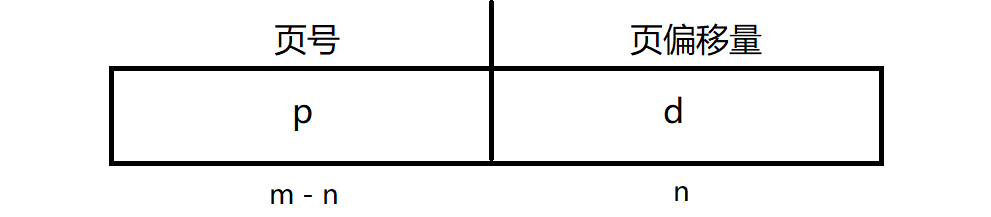
通過常駐內存中的頁表將虛擬地址翻譯為物理地址, CPU生成的虛擬地址被劃分為虛擬頁號(用作頁表索引,該頁表包含物理內存中每個頁的基地址)和虛擬頁偏移量(與基址結合找到存儲單元的物理存儲地址)。對於給定的邏輯地址空間2m和頁面大小2n,如下:
分頁內存管理方案本質就是通過MMU將CPU產生的虛擬地址通過中間媒介(頁表)進行地址翻譯,如下為簡單翻譯版本,一目瞭然。
上述我們學習了將邏輯地址(虛擬地址)劃分為頁號(注意:頁號並不屬於頁表的一部分,頁號不儲存在主存)和頁偏移量,到底是怎樣藉助頁號和頁偏移量進行翻譯的呢?我們舉個例子:假設如下一個32字節的物理內存,邏輯地址空間為16字節,說明邏輯地址有4位,而頁幀偏移量為4個字節,因頁幀偏移量和虛擬頁偏移量相等,所以虛擬頁偏移量也為4個字節即2位,所以頁號為(4-2)= 2位即邏輯地址共有4頁,如此假設和實際理論計算對等。地址翻譯如下:
若CPU要找出邏輯地址為4的物理地址,通過上述我們知道邏輯地址為4在第1頁且偏移量為0,然後去查找頁表索引等於1的頁幀號為6,因為物理地址 = (frame * pageSize)+ offset,所以邏輯地址4的物理地址=(6 * 4 bytes)+ 0 byte offset = 24。同理,比如如上邏輯地址為7在第1頁,偏移量為3對應頁表上的幀6,所以其物理地址為:(6 * 4 bytes)+ 3 byte offset = 27,這裏需要注意的是物理地址的偏移量是相對這頁的起始位置偏移。通過上述圖解,我們反推根據邏輯地址和每頁字節大小計算出其所在頁和偏移量(下面根據虛擬地址計算虛擬頁號和偏移量會用到),比如邏輯地址為7,因每頁大小為4個字節,則所在頁為(7 / 4) = 1,偏移量(7 mod / 4) = 3。
擴展頁表條目(PTE)信息
現代計算機頁表上的條目除了包含將虛擬地址翻譯為虛擬地址的主要信息(有效位、頁號)外,其中還包含如下其他信息(下面講解頁面置換算法會用到):
保護位(Protection):控制對指定虛擬頁的訪問是否可讀、可寫、可執行
引用位(Refrence):為了近似實現LRU算法,幫助操作系統估算最近最少使用的頁,當一頁被訪問時該位將被置位,操作系統定期將引用位清零,然後重新記錄,這樣就可以判定在這段特定時間內哪些頁被訪問過,通過檢查引用位是否關閉,操作系統就可以從那些最近最少訪問的頁中選擇一頁
臟位(Modify):當某一頁被替換時,操作系統需要知道該頁是否需要被複制寫回,為了追蹤讀入主存中的頁是否被寫過,增加一個臟位,當頁中任何字被寫時就將這一位置位。如果操作系統選擇替換某一頁,臟位指明了把該頁所佔用的主存讓給另一頁之前,是否需要將該頁寫回磁盤,因此,一個被修改的頁通常被稱為臟頁。
TLB緩存頁表
上一節我們講過CPU產生邏輯地址后通過MMU轉換為物理地址時,每次都要訪問頁表,訪問緩存和主存的時間相差上百個時鐘周期,所以為了提高查找性能則使用TLB,我們可認為TLB是實現頁表最好的方式,本質上是緩存頁表。在沒有TLB作為緩存時,我們使用頁號(VPN)作為索引去頁表上查找物理頁號,引入TLB后,將頁號劃分為TLBT(TLB標記)和TLBI(TLB索引)只是做了一下轉換而已,TLBI佔2位,剩餘的位就是TLBT。下面會通過一個實際例子來講解如何結合TLBT和TLBI在TLB上查找。
TLB作為頁表的緩存,用於存放映射到頁幀中的那些項,TLB包含了頁表中虛擬頁到頁幀映射的一個子集,因為將其作為緩存,所以額外還存在如上一個標記區域(TLBT),換句話說頁表不同於TLB並不是作為緩存,所以並不需要標記區域,再加上如上額外的PTE擴展信息,所以TLB的存儲結構如下:
TLB缺失
接下來我們開始進入TLB缺失環節,我們假設虛擬地址有14位,物理地址有16位,每頁大小有64個字節,那麼虛擬地址空間和物理地址空間如下圖所示
因為每頁大小為64字節即(26),同時虛擬頁偏移量和頁幀偏移量相等,所以虛擬頁偏移量和頁幀偏移量都為6位,那麼將虛擬地址空間和物理地址空間劃分為對應的頁號和頁偏移量則如下圖所示:
接下來則是將虛擬頁號劃分為TLBT和TLBI,因為TLB包含16個條目且4路關聯,那麼說明有S =(16 / 4)= 4組,那麼TLBI佔位 = log2S = 2,剩餘的則是TLBT = (8 – 2) = 6位,如下圖所示
現在我們對虛擬地址和物理地址都有了完整的劃分,現在假設TLB和頁表狀態存儲結構分別如下圖
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
台中景泰電動車行只是一個單純的理由,將來台灣的環境,出門可以自由放心的深呼吸,讓空氣回歸自然的乾淨,減少污染,留給我們下一代有好品質無空污的優質環境
假設現在CPU產生一個虛擬地址(0x0334),首先我們需要將其轉換為虛擬頁號(VPN),因每個頁面大小為64字節,所以計算方式如下代碼
var xvpn = Convert.ToInt32("0x334", 16); var vpn = xvpn / 64; //vpn = 12 var vpo = xvpn % 64; //vpo = 52
上述計算出VPN等於12,然後將其對應虛擬地址上的VPN和VPO用二進製表示,分別如下圖所示
而存儲在TLB和頁表上的狀態都是16進制,所以上述VPN = 1210 = 0x0C16和VPO = 5210 = 0x3416,到此已經劃分完VPN和VPO,接下來則是將VPN劃分為TLBT和TLBI,由上述我們已經知道TLBT和TLBI在VPN中所佔位數,所以如下圖所示
由上我們可得出TLBT = 310 = 0x0316,而TLBI = 0,有了TLBT(0x03)和TLBI(0)再去查找TLB狀態表,如下紅色標記
由上圖我們發現此時標誌無效而且物理頁號也沒有,此時發生TLB缺失,於是通過MMU將虛擬地址得到的VPN去頁表中查找
此時我們看到在頁表中也缺失,所以這裏將發生缺頁異常。TLB缺失分為如下兩種情況
頁在主存(頁表)中,只需要創建缺失的TLB表項
頁不在主存(頁表)中,需要將控制權交給操作系統來解決缺頁
TLB缺失既可以通過軟件處理也可以通過硬件處理,比如MIPS、Alpha通過軟件處理TLB缺失,x86、ARM通過硬件處理TLB缺失,兩種處理方式在性能差別上很小,無論哪一種方式需要執行的基本操作都是一樣的。理論上來講,在進程分配頁幀時會將對應頁幀更新到頁表上,但是上述情況並未在主存頁表中說明在頁幀列表中沒有空閑的頁幀,所以這是TLB缺失中真正的缺頁情況,此時將觸發缺頁異常,控制權交給操作系統內核中的缺頁異常處理程序,操作系統知道了引起缺頁的虛擬地址,操作系統必須完成以下3個步驟:【1】使用虛擬地址查找頁表項,並在磁盤上找到被訪問的頁的位置【2】選擇替換一個物理頁,如果該選中的頁被修改過,需要在把新的虛擬頁裝入之前將這個物理頁寫回磁盤,這一過程稱為頁面置換【3】啟動讀操作,將被訪問的頁從磁盤上取回到所選擇的物理頁的位置上【4】重新執行引發缺頁的那條指令。因為第3個步驟需要耗費數百萬個時鐘周期,如果第2個步驟中被替換的物理頁已被重寫過,那麼同樣也會花費這麼長時間,因此操作系統會選擇另外一個進程在處理器上執行直到磁盤訪問結束,所以前3個步驟執行所耗費的時間比較長,最後重新執行缺頁指令。若在頁表中找到了頁幀號(即頁在主存中),那說明TLB缺失只是一次轉換缺失,在這種情況下,CPU只需要將頁表項裝載到TLB並且重新訪問來進行缺失處理。
頁面置換算法
為了解決缺頁情況,所以必須實現頁面置換作為請求調頁的基礎,這裏我們介紹常見的幾種置換算法,分別是Optional or MIN algorithm、FIFO(First-In-First-Out)、Clock、LRU(Least Recently Used),針對各個算法,現假設有(1、2、3、4、1、2、5、1、2、3、4、5)12個引用串,4個空閑頁幀。
FIFO(先進先出)
該算法記錄了每個頁面記錄調到內存的時間,當必須置換頁面時,將選擇最舊的頁面,請注意,並不需要記錄調入頁面的確切時間,可以通過創建一個隊列實現此目的。具體過程太過簡單,這裏就不再細講,此時將發生10次缺頁錯誤,我們可計算出缺頁率為(10/12)= 83%。如下:
OPT or MIN(最優)
最優置換算法找出最長時間沒有使用的頁,具有最低缺頁率,可以用作離線分析方法,但是難以實現。此時將發生6次缺頁錯誤,我們可計算出缺頁率為(6/12)= 50%。如下:
LRU(最近最少使用)
FIFO算法使用的是頁面調入內存的時間,OPT算法使用的是頁面將來使用的時間,而LRU算法採用置換最長時間沒有的頁,該算法將每個頁面與它上次使用的時間關聯起來,當需要置換頁面時,LRU選擇最長時間沒有使用的頁面,該算法很難實現。此時將發生8次缺頁錯誤,我們可計算出缺頁率為(8/12)= 67%。如下:
啟動和切換進程
上述我們只是從已經將程序加載到內存中所創建的進程角度來分析如何將虛擬地址翻譯為物理地址,由於操作系統負責管理內存,因此必須了解物理內存的分配詳細信息,分配了哪些頁幀、每個頁幀分配個哪個進程的哪個頁面,哪些頁幀可用,總共有多少幀,對此我們還一無所知。將用戶程序加載到虛擬內存中的進程後為其劃分對應的虛擬頁,假設如下劃分了4個虛擬頁,操作系統在跟蹤的頁幀列表找出空閑(操作系統分配幀算法,這裏暫不討論)的頁幀分配給虛擬頁,然後操作系統再啟動進程。如下圖:
如上節所述頁表保存在主存中,當調度進程時通過頁表基址寄存器(PTBR)指向激活的指定進程頁表, 當然也會加載另外一個寄存器(程序計數器,PC),所以每個數據或指令訪問需要進行兩次主存訪問,一次是頁表,另一次則是用於數據或指令。
當進程希望以受限的方式共享信息時,操作系統必須對其進行協助,這是因為訪問另外一個進程的信息需要改變訪問進程的頁表,寫訪問位可以用來把共享限製為只讀,並且和頁表中其他位一樣,該位只能被操作系統所修改。為了允許另一進程,設為P1,去讀屬於進程P2的一頁,P2就要請求操作系統在P1地址空間中為一個虛擬頁生成頁表項,指向P2想要共享的物理頁。如果P2要求操作系統可以使用寫保護位以防止P1對數據進行改寫,由於只有TLB缺失才會訪問頁表,任何決定頁對的訪問權限不僅要包含在頁表中,還要包含在TLB中。當操作系統決定從進程P1切換到P2時,我們稱之為上下文切換,它必須保證P2不能P1的頁表,否則不利於數據保護,若沒有TLB,只需要把頁表基址寄存器指向P2的頁表而不是P1就夠了,如果有TLB,我們必須在其中清除屬於P1的表項,不僅僅是為了保護P1的數據,而且是為了迫使TLB裝入P2的表項。如果進程切換的頻率很高,那麼這一舉措效率將會很低。例如,在操作系統切回P1之前,P2可能只裝入了很少的TLB表項,但是,P1隨後發現它所有的表項都不見了,因此不得不通過TLB缺失來重新加載這些表項,產生這個問題的原因在於進程P1和P2使用同一虛擬地址空間,並且我們必須清除TLB以防止地址混淆。另一種常見的方法則是增加進程標識符和任務標識符來擴展虛擬地址空間,比如FastMATH就有8位地址空間標識域(ASID),這個標識域標識了當前正在運行的進程,當進程切換時,它保存在由操作系統裝入的寄存器中,進程標識符與TLB的標記部分相連接,因此只有在頁號和進程標識符相匹配時,TLB才會發生命中,如此一來,除非特殊情況,我們就不需要清除TLB。 說了怎麼多除了保護機制外,當我們切換進程時主要需要做哪些工作呢(即從一個進程控制塊(Process Control Block,PCB)切換到另一個進程塊,後續會深入講解操作系統線程和進程)?
切換頁表到當前PCB
頁表基址寄存器指向當前頁表
清除TLB,並將當前頁表項裝載到TLB(按需加載,進程訪問哪些頁才將對應頁表項加載到TLB)
留個作業
若TLB中的PTE條目達到上限即滿時,不難想象理論上會替換現有條目,那麼採取替換的策略或機制是怎樣的呢?
總結
基於上一節內容我們詳細講解了將虛擬地址翻譯為物理地址的具體過程、進程頁幀分配、頁面置換算法,在講解TLB缺失時並未涉及高速緩存,TLB和高速緩存將在下一節作為詳解。關於虛擬內存內容通過一兩篇文章根本講解不清楚,比如還有減少頁表容量方式、TLB和高速緩存關係、Intel和Linux虛擬內存系統等等。我盡量通過圖解方式來帶給大家較好的理解體驗,能夠更好的消化和吸收虛擬內存。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
網站的第一印象網頁設計,決定了客戶是否繼續瀏覽的意願。台北網動廣告製作的RWD網頁設計,採用精簡與質感的CSS語法,提升企業的專業形象與簡約舒適的瀏覽體驗,讓瀏覽者第一眼就愛上它。