※台北網頁設計公司這麼多該如何選擇?
網動是一群專業、熱情、向前行的工作團隊,我們擁有靈活的組織與溝通的能力,能傾聽客戶聲音,激發創意的火花,呈現完美的作品
在我們開發BS頁面的時候,往往需要了解常規界面組件的使用,小到最普通的單文本輸入框、多文本框、下拉列表,以及按鈕、圖片展示、彈出對話框、表單處理、條碼二維碼等等,本篇隨筆基於普通表格業務的展示錄入的場景介紹這些常規Element組件的使用,使得我們對如何利用Element組件有一個大概的認識。
1、列表界面和其他模塊展示處理
在前面隨筆《循序漸進VUE+Element 前端應用開發(5)— 表格列表頁面的查詢,列表展示和字段轉義處理》介紹了基於列表展示了相關數據,並在列表界面整合了增刪改查等常規的業務操作處理。
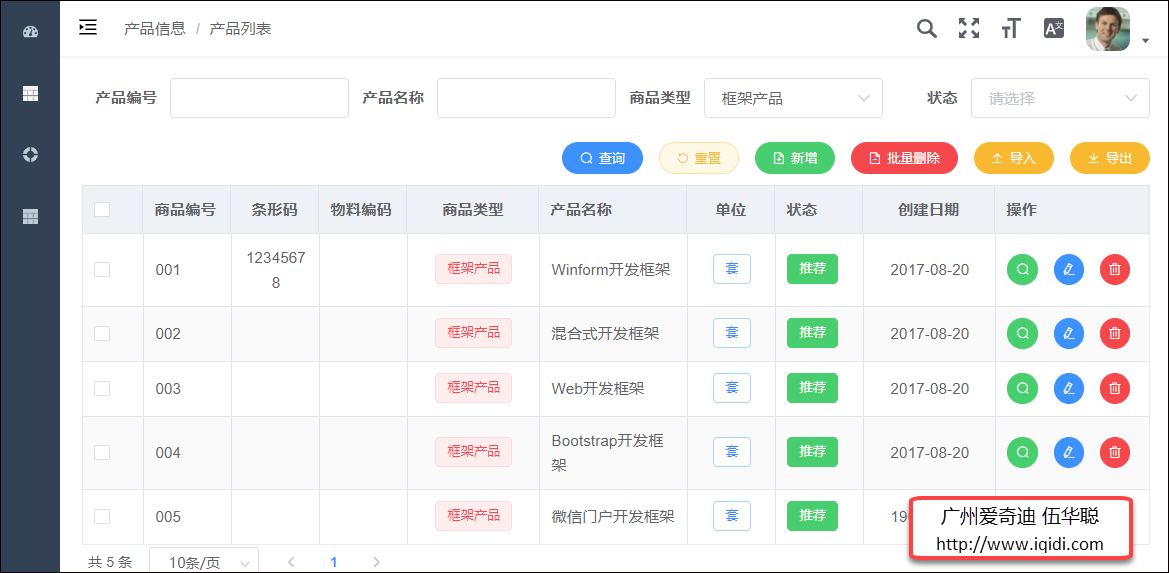
常規的列表展示界面,一般分為幾個區域,一個是查詢區域,一個是列表展示區域,一個是底部的分頁組件區域。查詢區域主要針對常規條件進行布局,以及增加一些全局或者批量的操作,如導入、導出、添加、批量添加、批量刪除等按鈕;而其中主體的列表展示區域,是相對比較複雜一點的地方,需要對各項數據進行比較友好的展示,可以結合Tag,圖標,按鈕等界面元素來展示,其中列表一般後面會包括一些對單行記錄處理的操作,如查看、編輯、刪除的操作,如果是批量刪除,可以放到頂部的按鈕區域。
對於常規按鈕、表格、分頁組件,前面已經做了相關的介紹,這裏就不再贅述。
在介紹具體界面組件的時候,我們先來了解下,整體的界面布局,我們把常規的列表界面,新增、編輯、查看、導入等界面放在一起,除了列表頁面,其他內容以彈出層對話框的方式進行處理,如下界面示意所示。
每個對話框的:visible的屬性值,則是確定哪個模態對話框的显示和隱藏。
在Vue的JS模塊裏面,我們除了定義對應的對話框显示的變量外,對每個對話框,我們定義一個表單信息用來進行數據的雙向綁定處理。
常規的新增、編輯、查看、導入等內容的定義,作為一個對話框組件定義,常規的對話框組件的使用代碼如下所示。
<el-dialog
title="提示"
:visible.sync="dialogVisible"
width="30%"
:before-close="handleClose">
<span>這是一段信息</span>
<span slot="footer" class="dialog-footer">
<el-button @click="dialogVisible = false">取 消</el-button>
<el-button type="primary" @click="dialogVisible = false">確 定</el-button>
</span>
</el-dialog>
為了控制對話框的樣式,我們這裏注意下footer的slot,這個我們一般是把處理按鈕放在這裏,如對於查看界面對話框,我們定義如下所示。
一般來說,對於表單內容比較多的場景,我們一般分開多個選項卡進行展示或者錄入,這樣方便管理,查看界面整體效果如下所示。
對於對話框的數據綁定,我們在打開對話框前,先通過API模塊請求獲得JSON數據,然後綁定在對應的對話框模型屬性上即可,如對於查看界面,我們的處理邏輯如下所示。
showView(id) {
var param = { id: id }
GetProductDetail(param).then(data => {
Object.assign(this.viewForm, data);
})
this.isView = true
},
對於表格的雙擊,我們同樣綁定它的查看明細處理操作,如下模板代碼和JS代碼所示。
模板HTML代碼如下:
<el-table
v-loading="listLoading"
:data="productlist"
border
fit
stripe
highlight-current-row
:header-cell-style="{background:'#eef1f6',color:'#606266'}"
@selection-change="selectionChange"
@row-dblclick="rowDbclick"
>
JS邏輯代碼如下
rowDbclick(row, column) {
var id = row.ID
this.showView(id);
},
2、常規界面組件的使用
一般情況下,我們使用界面組件的時候,參考下官網《Element組件使用》,尋找對應組件的代碼進行參考,就差不多了,這裏還是就各種常規的Element組件進行大概的介紹吧。
1)表單和表單項、單文本框
對於表單,我們一般定義一個對應的名稱,並設置它的data對應的模型名稱即可,如下所示。
<el-form ref="viewForm" :model="viewForm" label-width="80px">
而表單項,一般是定義好表單項的Label即可,然後在其中插入對應的錄入控件或者展示控件。如對於單文本組件使用,如下所示。
<el-form-item label="產品編號">
<el-input v-model="editForm.ProductNo" />
</el-form-item>
其中 v-model=”editForm.ProductNo” 就是對應綁定的數據。
而表單項,可以添加對字段的驗證處理,在數據提交前,可以校驗客戶的錄入是否有效等。
<el-form-item
prop="email"
label="郵箱"
:rules="[
{ required: true, message: '請輸入郵箱地址', trigger: 'blur' },
{ type: 'email', message: '請輸入正確的郵箱地址', trigger: ['blur', 'change'] }
]"
>
<el-input v-model="dynamicValidateForm.email"></el-input>
</el-form-item>
注意這裏表單項,必須添加一個prop的屬性設置,如 prop=”email” 所示。
一般為了控制布局,我們還結合el-row進行一個布局的處理,如下代碼所示(一行等於span為24,span=12也就是一行放兩個控件組)。
<el-row>
<el-col :span="12">
<el-form-item label="產品編號">
<el-input v-model="editForm.ProductNo" />
</el-form-item>
</el-col>
<el-col :span="12">
<el-form-item label="條碼">
<el-input v-model="editForm.BarCode" />
</el-form-item>
</el-col>
</el-row>
2)、下拉列表控件的綁定
下拉列表的綁定處理,也是通過 v-model 進行值的綁定,而選項則可以通過數據列表進行綁定。
<el-form-item label="商品類型">
<el-select v-model="editForm.ProductType" filterable="" placeholder="請選擇">
<el-option
v-for="(item, key) in typeList"
:key="key"
:label="item.value"
:value="item.key"
/>
</el-select>
</el-form-item>
而選項中的 typeList,我們可以在頁面初始化的時候獲取出來即可。
created() {
// 獲取產品類型,用於綁定字典等用途
GetProductType().then(data => {
if (data) {
data.forEach(item => {
this.productTypes.set(item.id, item.name)
this.typeList.push({ key: item.id, value: item.name })
})
// 獲取列表信息
this.getlist()
}
});
},
對於textarea常規的多行文本框,其實和普通單行文本框處理差不多,指定它的type=”textarea” 和 rows的數值即可。
<el-tab-pane label="說明" name="second">
<el-form-item label="說明">
<el-input v-model="editForm.Description" type="textarea" :rows="10" />
</el-form-item>
</el-tab-pane>
而對於一些可能需要展示HTML內容的,我們可以使用DIV控件來展示,通過v-html標識來處理包含HTML代碼的內容。
<el-tab-pane label="詳細說明">
<el-form-item label="詳細說明">
<div class="border-radius" v-html="viewForm.Note" />
</el-form-item>
</el-tab-pane>
3)、圖片展示
對於一些需要展示服務器圖片,我們請求后,根據Element圖片組件的設置處理即可,如下包括單個圖片和多個圖片的展示和預覽操作。
圖片展示的代碼如下所示。
<el-tab-pane label="圖片信息">
<el-form-item label="封面圖片">
<el-image
style="width: 100px; height: 100px"
:src="viewForm.Picture"
:preview-src-list="[viewForm.Picture]"
/>
</el-form-item>
<el-form-item label="Banner圖片">
<el-image
style="width: 100px; height: 100px"
:src="viewForm.Banner"
:preview-src-list="[viewForm.Banner]"
/>
</el-form-item>
<el-form-item label="商品展示圖片">
<el-image
v-for="item in viewForm.pics"
:key="item.key"
class="border-radius"
:src="item.pic"
style="width: 100px; height: 100px;padding:10px"
:preview-src-list="getPreviewPics()"
/>
</el-form-item>
</el-tab-pane>
上圖中,如果是單個圖片,那麼預覽我們設置一個集合為一個url即可,如 [viewForm.Banner],如果是多個圖片,需要通過一個函數來獲取圖片列表,如 getPreviewPics() 函數所示。
getPreviewPics() {
// 轉換ViewForm.pics裏面的pic集合
var list = []
if (this.viewForm.pics) {
this.viewForm.pics.forEach(item => {
if (item.pic) {
list.push(item.pic)
}
})
}
return list
}
※網頁設計最專業,超強功能平台可客製化
窩窩以「數位行銷」「品牌經營」「網站與應用程式」「印刷品設計」等四大主軸,為每一位客戶客製建立行銷脈絡及洞燭市場先機。
4)、第三方擴展控件
對於一些需要使用擴展組件的,我們一般搜索下解決方案,通過npm安裝對應的組件即可解決,如對於條碼和二維碼,我使用 @chenfengyuan/vue-barcode和 @chenfengyuan/vue-qrcode,一般在Github上搜索下關鍵字,總能找到一些很受歡迎的第三方組件。
安裝這些組件都有具體的說明,如下所示(如果卸載,直接修改install為uninstall即可)。
npm install @chenfengyuan/vue-barcode vue
以及
npm install @chenfengyuan/vue-qrcode vue
條碼和二維碼的展示效果如下所示
如果全局引入barcode和qrcode 組件,我們在main.js裏面引入即可,如下代碼所示
// 引入barcode,qrcode
import VueBarcode from '@chenfengyuan/vue-barcode';
import VueQrcode from '@chenfengyuan/vue-qrcode';
Vue.component(VueBarcode.name, VueBarcode);
富文本編輯,我這裏採用了 Tinymce 第三方組件來實現編輯處理,展示效果如下所示。
代碼如下所示
<el-tab-pane label="詳細說明" name="third">
<el-form-item label="詳細說明">
<tinymce v-model="editForm.Note" :height="300" />
</el-form-item>
</el-tab-pane>
以上就是一些常規的界面組件的使用,後面在繼續介紹文件上傳和圖片結合的操作。
3、自定義組件的創建使用
使用Vue的比以往BS開發的好處,就是可以很容易實現組件化,這點很好,一旦我們定義好一個控件,就可以在多個界面裏面進行使用,非常方便,而且封裝性可以根據自己的需要進行處理。
查詢區域一般的界面效果如下所示,除了包含一些常用的查詢條件,一般會有一些下拉列表,這些可能是後台字典裏面綁定的內容,可以考慮作為一個通用的字典下拉列表組件來做。
其實界面錄入的時候,也往往需要這些條件下拉列表的。
那麼我們來定義一個自定義組件,並在界面上使用看看。
在Components目錄創建一個目錄,並創建一個組件的vue文件,命名為my-dictdata.vue,如下所示。
界面模板代碼我們就一個select組件為主即可。
<template>
<el-select v-model="svalue" filterable clearable placeholder="請選擇">
<el-option
v-for="(item, index) in dictItems"
:key="index"
:label="item.Text"
:value="item.Value"
/>
</el-select>
</template>
script腳本邏輯代碼如下所示。
<script>
// 引入API模塊類方法
import { GetDictData } from '@/api/dictdata'
export default {
name: 'MyDictdata', // 組件的名稱
props: {
typeName: { // 字典類型方式,從後端字典接口獲取數據
type: String,
default: ''
},
options: {// 固定列表方式,直接綁定
type: Array,
default: () => { return [] }
}
},
data() {
return {
dictItems: [], // 設置的字典列表
svalue: '' // 選中的值
}
},
watch: {
// 判斷下拉框的值是否有改變
svalue(val, oldVal) {
if (val !== oldVal) {
this.$emit('input', this.svalue);
}
}
},
mounted() {
var that = this;
if (this.typeName && this.typeName !== '') {
// 使用字典類型,從服務器請求數據
GetDictData(this.typeName).then(data => {
if (data) {
data.forEach(item => {
if (item && typeof (item.Value) !== 'undefined' && item.Value !== '') {
that.dictItems.push(item)
}
});
}
})
} else if (this.options && this.options.length > 0) {
// 使用固定字典列表
this.options.forEach(item => {
if (item && typeof (item.Value) !== 'undefined' && item.Value !== '') {
that.dictItems.push(item)
}
});
}
// 設置默認值
this.svalue = this.value;
},
methods: {
}
}
</script>
主要就是處理字典數據的獲取,並綁定到模型對象上即可。
在頁面上使用前,需要引入我們定義的組件
import myDictdata from '@/components/Common/my-dictdata'
然後包含進去components裏面即可
export default {
components: { myDictdata },
那麼原來需要直接使用select組件的代碼
<el-select v-model="searchForm.ProductType" filterable clearable placeholder="請選擇">
<el-option
v-for="(item, key) in typeList"
:key="key"
:label="item.value"
:value="item.key"
/>
</el-select>
則可以精簡為一行代碼
<my-dictdata v-model="searchForm.ProductType" type-name="商品類型" />
而對於固定列表的,我們也可以通用的處理代碼
<my-dictdata v-model="searchForm.Status" :options="Status" />
其中Status是定義的一個對象集合
Status: [
{ Text: '正常', Value: 0 },
{ Text: '推薦', Value: 1 },
{ Text: '停用', Value: 2 }
]
是不是非常方便,而得到的效果則不變。
以上就是多個頁面內容,通過對話框層模式整合在一起,並介紹如何使用,以及對界面中常見的Element組件進行介紹如何使用,以及定義一個字典列表的主定義組件,用於簡化界面代碼使用,
列出以下前面幾篇隨筆的連接,供參考:
循序漸進VUE+Element 前端應用開發(1)— 開發環境的準備工作
循序漸進VUE+Element 前端應用開發(2)— Vuex中的API、Store和View的使用
循序漸進VUE+Element 前端應用開發(3)— 動態菜單和路由的關聯處理
循序漸進VUE+Element 前端應用開發(4)— 獲取後端數據及產品信息頁面的處理
循序漸進VUE+Element 前端應用開發(5)— 表格列表頁面的查詢,列表展示和字段轉義處理
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
※推薦評價好的iphone維修中心
擁有專業的維修技術團隊,同時聘請資深iphone手機維修專家,現場說明手機問題,快速修理,沒修好不收錢