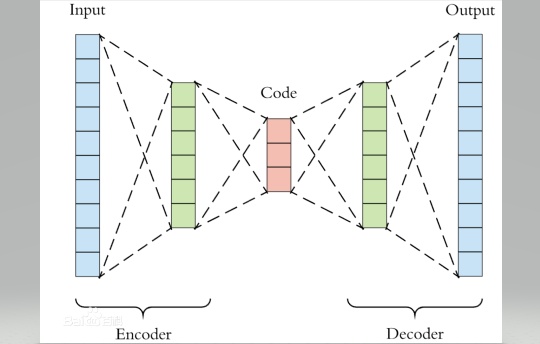
自編碼器是無監督學習領域中一個非常重要的工具。最近由於圖神經網絡的興起,圖自編碼器得到了廣泛的關注。筆者最近在做相關的工作,對科研工作中經常遇到的:自編碼器(AE),變分自編碼器(VAE),圖自編碼器(GAE)和圖變分自編碼器(VGAE)進行了總結。如有不對之處,請多多指正。
另外,我必須要強調的一點是:很多文章在比較中將自編碼器和變分自編碼器視為一類,我個人認為,這二者的思想完全不同。自編碼器的目的不是為了得到latent representation(中間層),而是為了生成新的樣本。我自己的實驗得出的結論是,變分自編碼器和變分圖自編碼器生成的中間層不能直接用來做下游任務(聚類、分類等),這是一個坑。
自編碼器(AE)
在解釋圖自編碼器之前,首先理解下什麼是自編碼器。自編碼器的思路來源於傳統的PCA,其目的可以理解為非線性降維。我們知道在傳統的PCA中,學習器學得一個子空間矩陣,將原始數據投影到一個低維子空間,從未達到數據降維的目的。自編碼器則是利用神經網絡將數據逐層降維,每層神經網絡之間的激活函數就起到了將”線性”轉化為”非線性”的作用。自編碼器的網絡結構可以是對稱的也可以是非對稱的。我們下面以一個簡單的四層對稱的自編碼器為例,全文代碼見最後。
(嚴格的自編碼器是只有一個隱藏層,但是我在這裏做了個拓展,其最大的區別就是隱藏層以及神經元數量的多少,理解一個,其它的都就理解了。)
圖自編碼器(GAE)
圖自編碼器和自編碼器最大的區別有兩點:一是圖自編碼器在encoder過程中使用了一個 \(n*n\) 的卷積核;另一個是圖自編碼器沒有數據解碼部分,轉而代之的是圖解碼(graph decoder),具體實現是前後鄰接矩陣的變化做loss。
圖自編碼器可以像自編碼器那樣用來生成隱向量,也可以用來做鏈路預測(應用於推薦任務)。
變分自編碼器(VAE)
變分自編碼是讓中間層Z服從一個分佈。這樣我們想要生成一個新的樣本的時候,就可以直接在特定分佈中隨機抽取一個樣本。另外,我初學時遇到的疑惑,就是中間層是怎麼符合分佈的。我的理解是:
輸入樣本:\(\mathbf{X \in \mathcal{R}^{n * d}}\)
中間層 :\(\mathbf{Z \in \mathcal{R}^{n * m}}\)
所謂的正態分佈是讓\(Z\)的每一行\(z_i\)符合正態分佈,這樣才能隨機從正態分佈中抽一個新的\(z_i\)出來。但是正是這個原因,我認為\(Z\)不能直接用來處理下游任務(分類、聚類),我自己的實驗確實效果不好。
變分圖自編碼器(VGAE)
如果你理解了變分比編碼器和圖自編碼器,那麼變分圖自編碼器你也就能理解了。第一個改動就是在VAE的基礎上把encoder過程換成了GCN的卷積過程,另一個改動就是把decoder過程換成了圖decoder過程。同樣生成的中間層隱向量不能直接應用下游任務。
數據集和下游任務的代碼見: https://github.com/zyx423/GAE-and-VGAE.git
全文代碼如下:
class myAE(torch.nn.Module):
def __init__(self, d_0, d_1, d_2, d_3, d_4):
super(myAE, self).__init__()
// 這裏的d0, d_1, d_2, d_3, d_4對應四層神經網絡的維度
self.conv1 = torch.nn.Sequential(
torch.nn.Linear(d_0, d_1, bias=False),
torch.nn.ReLU(inplace=True)
)
self.conv2 = torch.nn.Sequential(
torch.nn.Linear(d_1, d_2, bias=False),
torch.nn.ReLU(inplace=True)
)
self.conv3 = torch.nn.Sequential(
torch.nn.Linear(d_2, d_3, bias=False),
torch.nn.ReLU(inplace=True)
)
self.conv4 = torch.nn.Sequential(
torch.nn.Linear(d_3, d_4, bias=False),
torch.nn.Sigmoid()
)
def Encoder(self, H_0):
H_1 = self.conv1(H_0)
H_2 = self.conv2(H_1)
return H_2
def Decoder(self, H_2):
H_3 = self.conv3(H_2)
H_4 = self.conv4(H_3)
return H_4
def forward(self, H_0):
Latent_Representation = self.Encoder(H_0)
Features_Reconstrction = self.Decoder(Latent_Representation)
return Latent_Representation, Features_Reconstrction
class myGAE(torch.nn.Module):
def __init__(self, d_0, d_1, d_2):
super(myGAE, self).__init__()
self.gconv1 = torch.nn.Sequential(
torch.nn.Linear(d_0, d_1, bias=False),
torch.nn.ReLU(inplace=True)
)
self.gconv1[0].weight.data = get_weight_initial(d_1, d_0)
self.gconv2 = torch.nn.Sequential(
torch.nn.Linear(d_1, d_2, bias=False)
)
self.gconv2[0].weight.data = get_weight_initial(d_2, d_1)
def Encoder(self, Adjacency_Modified, H_0):
H_1 = self.gconv1(torch.matmul(Adjacency_Modified, H_0))
H_2 = self.gconv2(torch.matmul(Adjacency_Modified, H_1))
return H_2
def Graph_Decoder(self, H_2):
graph_re = Graph_Construction(H_2)
Graph_Reconstruction = graph_re.Middle()
return Graph_Reconstruction
def forward(self, Adjacency_Modified, H_0):
Latent_Representation = self.Encoder(Adjacency_Modified, H_0)
Graph_Reconstruction = self.Graph_Decoder(Latent_Representation)
return Graph_Reconstruction, Latent_Representation
class myVAE(torch.nn.Module):
def __init__(self, d_0, d_1, d_2, d_3, d_4, bias=False):
super(myVAE, self).__init__()
self.conv1 = torch.nn.Sequential\
(
torch.nn.Linear(d_0, d_1, bias= False),
torch.nn.ReLU(inplace=True)
)
# VAE有兩個encoder,一個用來學均值,一個用來學方差
self.conv2_mean = torch.nn.Sequential(
torch.nn.Linear(d_1, d_2, bias=False)
)
self.conv2_std = torch.nn.Sequential(
torch.nn.Linear(d_1, d_2, bias=False)
)
self.conv3 = torch.nn.Sequential(
torch.nn.Linear(d_2, d_3, bias=False),
torch.nn.ReLU(inplace=False)
)
self.conv4 = torch.nn.Sequential(
torch.nn.Linear(d_3, d_4, bias=False),
torch.nn.Sigmoid()
)
def Encoder(self, H_0):
H_1 = self.conv1(H_0)
H_2_mean = self.conv2_mean(H_1)
H_2_std = self.conv2_std(H_1)
return H_2_mean, H_2_std
def Reparametrization(self, H_2_mean, H_2_std):
# sigma = 0.5*exp(log(sigma^2))= 0.5*exp(log(var))
std = 0.5 * torch.exp(H_2_std)
# N(mu, std^2) = N(0, 1) * std + mu。
# 數理統計中的正態分佈方差,剛學過, std是方差。
# torch.randn 生成正態分佈
Latent_Representation = torch.randn(std.size()) * std + H_2_mean
return Latent_Representation
# 解碼隱變量
def Decoder(self, Latent_Representation):
H_3 = self.conv3(Latent_Representation)
Features_Reconstruction = self.conv4(H_3)
return Features_Reconstruction
# 計算重構值和隱變量z的分佈參數
def forward(self, H_0):
H_2_mean, H_2_std = self.Encoder(H_0)
Latent_Representation = self.Reparametrization(H_2_mean, H_2_std)
Features_Reconstruction = self.Decoder(Latent_Representation)
return Latent_Representation, Features_Reconstruction, H_2_mean, H_2_std
class myVGAE(torch.nn.Module):
def __init__(self, d_0, d_1, d_2):
super(myVGAE, self).__init__()
self.gconv1 = torch.nn.Sequential(
torch.nn.Linear(d_0, d_1, bias=False),
torch.nn.ReLU(inplace=True)
)
# self.gconv1[0].weight.data = get_weight_initial(d_1, d_0)
self.gconv2_mean = torch.nn.Sequential(
torch.nn.Linear(d_1, d_2, bias=False)
)
# self.gconv2_mean[0].weight.data = get_weight_initial(d_2, d_1)
self.gconv2_std = torch.nn.Sequential(
torch.nn.Linear(d_1, d_2, bias=False)
)
# self.gconv2_std[0].weight.data = get_weight_initial(d_2, d_1)
def Encoder(self, Adjacency_Modified, H_0):
H_1 = self.gconv1(torch.matmul(Adjacency_Modified, H_0))
H_2_mean = self.gconv2_mean(torch.matmul(Adjacency_Modified, H_1))
H_2_std = self.gconv2_std(torch.matmul(Adjacency_Modified, H_1))
return H_2_mean, H_2_std
def Reparametrization(self, H_2_mean, H_2_std):
# sigma = 0.5*exp(log(sigma^2))= 0.5*exp(log(var))
std = 0.5 * torch.exp(H_2_std)
# N(mu, std^2) = N(0, 1) * std + mu。
# 數理統計中的正態分佈方差,剛學過, std是方差。
# torch.randn 生成正態分佈
Latent_Representation = torch.randn(std.size()) * std + H_2_mean
return Latent_Representation
# 解碼隱變量
def Graph_Decoder(self, Latent_Representation):
graph_re = Graph_Construction(Latent_Representation)
Graph_Reconstruction = graph_re.Middle()
return Graph_Reconstruction
def forward(self, Adjacency_Modified, H_0):
H_2_mean, H_2_std = self.Encoder(Adjacency_Modified, H_0)
Latent_Representation = self.Reparametrization(H_2_mean, H_2_std)
Graph_Reconstruction = self.Graph_Decoder(Latent_Representation)
return Latent_Representation, Graph_Reconstruction, H_2_mean, H_2_std
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※教你寫出一流的銷售文案?
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!

