ElasticSearch基礎概念
使用場景:比如分庫的情況下,你想統計所有數據的報表,就把所有數據都放在ElasticSearch上
| 關係型數據庫 | ElasticSearch |
| 數據庫Database | 索引index,支持全文檢索 |
| 表Table | 類型Type |
| 數據行Row | 文檔Document |
| 數據列Column | 字段Field |
| 模式Schema | 映射Mapping |
用關係型數據庫就會想到建立一張User表,再建字段等,
而在Elasticsearch的文件存儲,Elasticsearch是面向文檔型數據庫,一條數據在這裏就是一個文檔,用JSON作為文檔序列化的格式
在ES6.0之後,已經不允許在一個index下建不同的Type了,一個index下只有一個Type(以後版本中Type概念會去掉,可以直接把index類比成Table)
節點Node:
一個ElasticSearch運行的實列,集群構成的單元
集群Cluster:
由一個或多個節點組成,對外提供服務
Elasticsearch實現原理-倒排索引
ElasticSearch是基於倒排索引實現的
倒排索引(Inverted Index)也叫反向索引,有反向索引必有正向索引。
通俗地來講,正向索引是通過key找value,反向索引則是通過value找key。
倒排索引—單詞詞典
單詞詞典(Term Dictionary)是倒排索引的重要組成部分。
——記錄所有文檔的單詞,一般都比較大
——記錄單詞到倒排列表的關聯信息(這個單詞關聯了哪些文檔)
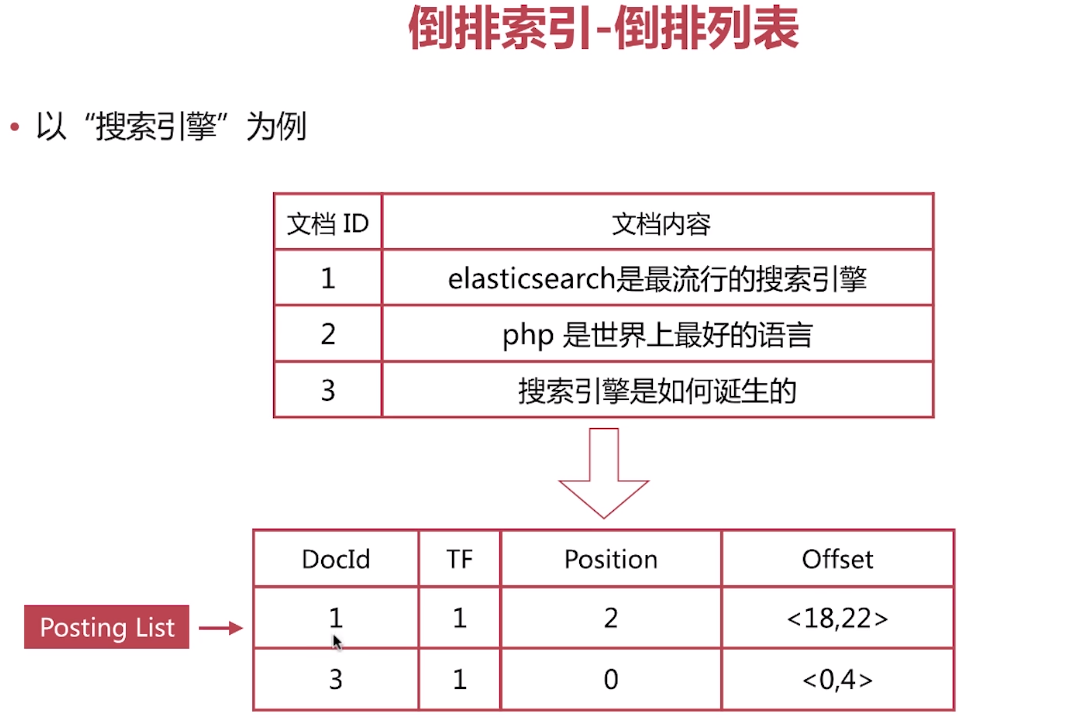
倒排索引—排序列表
倒排列表(Posting List)記錄了單詞對應文檔的集合,由倒排索引項(Posting)組成
倒排索引項(Posting)主要包含如下信息
—文檔Id,用於獲取原始信息
—單詞頻率(TF,Term Frequency),記錄該單詞在文檔中出現的次數,用於後序相關算分
—位置(Position),記錄單詞在文檔中的分詞位置,用於做詞語搜索(Phrase Query)
—偏移(Offset),記錄單詞在文檔的開始和結束位置,用於高亮显示
分詞
搜索引擎的核心是倒排索引,而倒排索引的基礎就是分詞。所謂分詞可以簡單理解為將一個完整的句子切割為一個個單詞的過程。也可以叫文本分析,在es稱為Analysis。
如文本:elasticSearch是最流行的搜索引擎
分詞結果:elasticSearch 流行 搜索引擎
分詞器是es中專門處理分詞的組件,英文為Analyzer,它的組成如下
Character Filters:針對原始文本特殊處理,比如除html特殊符
Tokenizer:將原始文本按照一定規則切分為單詞
TokenFilters:針對tokenizer處理的單詞就行在加工,比如轉小寫,刪除或新增處理(比如中文中的 這 呢 無實意的詞)
Analyze API
es提供了一個測試分詞的API接口,方便驗證分詞效果,endpoint是_analyze
—可以直接指定analyze測試
—可以直接指定索引中的字段進行測試
—可以自定義分詞器進行測試
文檔映射Mapping
Mapping類似數據庫中的表結構定義,主要作用如下:
—定義Index下的字段名(Field Name)
—定義字段的類型,比如數值型、字符串型、布爾型等
—定義倒排索引相關的配置,比如是否索引、記錄position等
Dynamic Mapping
es可以自動識別文檔字段類型,從而降低用戶使用成本
SearchAPI介紹和相關性算分
es中存儲的數據進行查詢分析,endpoint為_search
查詢主要有兩種形式
1)URI Search
操作簡單,方便通過命令進行測試
但 僅包含部分查詢語法
GET /indexname/_search?q=user:xx
2)Request Body Search
es提供的完備查詢語法Query DSL(Domain Specific Language)
GET /indexname/_search
{
”query”: {
”term”: {
”user”: “xx”
}
}
}
相關算分
相關算分是指文檔與查詢語句直接的相關度,英文為relevance
通過倒排索引可以獲取與查詢語句相匹配的文檔列表,那麼如何將最符合用戶查詢的文檔放到前列呢
本質是一個排序問題,排序的依據是相關算分
ES目前主要有兩個相關性算分模型
TF/IDF模型
BM25模型 5.x之後的默認模型
BM25相比TF/IDF的一大優化是降低了TF(Term Frequency單詞頻率)在過大時的權重
相關算分是shard與shard間是相互獨立的,也就意味着一個Term的IDF等值在不同shard上是不同的。文檔的相關算分和它所處的shard有關
在文檔數量不多時 會導致相關算分嚴重不準的情況發生
解決辦法
—設置分片數是一個,從根本排除問題,在文檔數據量不多時可以考慮該方法,(百萬到千萬)
—二是使用DFS Query Then Ftech查詢方式
Elasticsearch分佈式特性
es支持集群模式,是一個分佈式系統,好處是
—1)增加系統容量:內存、磁盤,使es集群可以支持PB級的數據
如何將數據分佈在所有節點上
—引入分片 Shard解決問題
分片是ES支持PB級數據的基石
—分片存儲了部分數據,可以分部在任意節點上
—分片數在索引創建時指定且後序不允許再更改(即使你後面新增了也用不到),默認5個
—分片有主分片和副本分片之分,以實現數據的高可用
es集群由多個es實列組成
—不同集群通過集群名字來區分,可通過cluster.name修改,默認為elasticSearch
—每個ES實列本質是一個JVM進程,且有自己的名字,通過node.name修改
Master Node:Master節點通過集群中所有的節點選舉產生,可以被選舉的節點稱為master-eligible節點,
相關配置如下:node.master:true
Coordinating Node:處理請求的節點為Coordinating節點,該節點為所有節點默認角色,不能取消
作用是把請求路由到正確的節點處理,比如創建索引請求到master節點
Data Node:存儲數據的節點即為data節點,默認節點都是data類型,相關配置如下:node.data.true
—2)提供系統可用性:即部分節點停止服務,整個集群依然可以正常服務
提高系統可用性
服務可用性
—兩個節點情況下,允許其中一個節點停止服務
數據可用性
—引入副本(Replication)解決
—每個節點上都有完備的數據
複製分片的意義在於容錯性,當一個節點掛了,另一個節點上的分片可以代替掛掉節點上的分片
故障轉移
一:
二:
三:
文檔到分片的映射算法
es通過如下公式計算文檔到對應的分片 -shard=hash(routing)%number_of_primary_shards
hash算法保證可以將數據均勻的分散在分片中
routing是一個關鍵參數,默認是文檔id,也可以自行指定
number_of_primary_shards是主片分數(該算法與主片分數相關,這也是分片數量一旦確定就不能修改的原因)
腦裂問題
在上述第一步的時候 node2和node3選舉node2為master節點了時候,此時會更新cluster state
此時node1節點網絡恢復了,node1自己組成集群后,也會更新cluster state
此時:同一個集群有兩個master,而且維護不同的cluster state,網絡恢復后 無法選擇正確的master
解決方案:僅在可選舉master-eligible節點數大於等於quorum時才可以進行master選舉
即使node1節點恢復了 ,可選節點數未達到quorum,不選舉
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選
※評比南投搬家公司費用收費行情懶人包大公開