本文是對的補充
前文對隨機森林的概念、工作原理、使用方法做了簡單介紹,並提供了分類和回歸的實例。
本期我們重點講一下:
1、集成學習、Bagging和隨機森林概念及相互關係
2、隨機森林參數解釋及設置建議
3、隨機森林模型調參實戰
4、隨機森林模型優缺點總結
集成學習、Bagging和隨機森林
集成學習
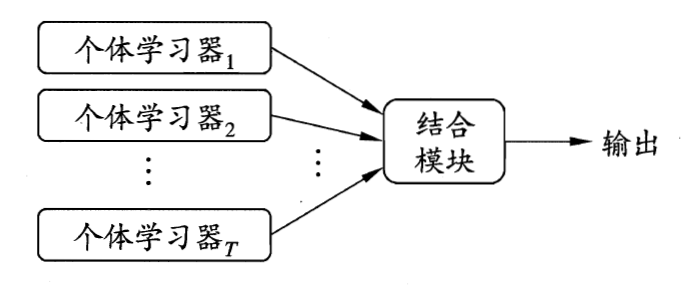
集成學習並不是一個單獨的機器學習算法,它通過將多個基學習器(弱學習器)進行結合,最終獲得一個強學習器。這裏的弱學習器應該具有一定的準確性,並且要有多樣性(學習器之間具有差異),比較常用的基學習器有決策樹和神經網絡。
集成學習的核心就是如何產生並結合好而不同的基學習器,這裡有兩種方式是,一種是Bagging,基學習器之間沒有強依賴關係,可同時生成的并行化方法。一種是Boosting,基學習器之間有強依賴關係,必須串行生成。
集成學習另一個關鍵問題是結合策略,主要有平均法、投票法和學習法,這裏不再展開。
Bagging
Bagging是Bootstrap AGGregaING的縮寫,Bootstrap即隨機採樣,比如給定含有$m$個樣本的數據集$D$,每次隨機的從中選擇一個樣本,放入新的數據集,然後將其放回初始數據集$D$,放回後有可能繼續被採集到,重複這個動作$m$次,我們就得到新的數據集$D’$。
用這種方式,我們可以採樣出TGE含m個訓練樣本的採樣集,然後基於每個採樣集訓練基學習器,再將基學習器進行結合,這便是Bagging的基本流程。
隨機森林
隨機森林是非常具有代表性的Bagging集成算法,它在Bagging基礎上進行了強化。
它的所有基學習器都是CART決策樹,傳統決策樹在選擇劃分屬性時是在當前結點的屬性集合(假定有d個屬性)中選擇最優屬性。但是隨機森林的決策樹,現在每個結點的屬性集合隨機選擇部分k個屬性的子集,然後在子集中選擇一個最優的特徵來做決策樹的左右子樹劃分,一般建議$k=log_2d$.分類決策樹組成的森林就叫做隨機森林分類器,回歸決策樹所集成的森林就叫做隨機森林回歸器。
RF的算法:
輸入為樣本集$D={(x_,y_1),(x_2,y_2), …(x_m,y_m)}$,弱分類器迭代次數T。
輸出為最終的強分類器$f(x)$
1)對於t=1,2…,T:
a)對訓練集進行第t次隨機採樣,共採集m次,得到包含m個樣本的採樣集Dt
b)用採樣集$D_t$訓練第t個決策樹模型$G_t(x)$,在訓練決策樹模型的節點的時候, 在節點上所有的樣本特徵中選擇一部分樣本特徵, 在這些隨機選擇的部分樣本特徵中選擇一個最優的特徵來做決策樹的左右子樹劃分
2)如果是分類算法預測,則T個弱學習器投出最多票數的類別或者類別之一為最終類別。如果是回歸算法,T個弱學習器得到的回歸結果進行算術平均得到的值為最終的模型輸出。
隨機森林參數解釋及設置建議
在scikit-learn中,RandomForest的分類類是RandomForestClassifier,回歸類是RandomForestRegressor,需要調參的參數包括兩部分,第一部分是Bagging框架的參數,第二部分是CART決策樹的參數。這裏我們看一下scikit-learn中隨機森林的主要參數
隨機森林模型調參實戰
這是一道kaggle上的題目,通過信用卡交易記錄數據對欺詐行為進行預測,信用卡欺詐檢測文件記錄了2013年9月歐洲信用卡持有者所發生的交易。在284807條交易記錄中共包含492條欺詐記錄。
數據集下載地址:請在公眾號後台回復[56]
需要說明的是,本文重點是RF模型調參,所以不涉及數據預處理、特徵工程和模型融合的內容,這些我會在本欄目未來的章節中再做介紹。
所以最終結果可能會不理想,這裏我們只關注通過調參給模型帶來的性能提升和加深對重要參數的理解即可。
1、導入用到的包
import numpy as np
import pandas as pd
from sklearn.model_selection import GridSearchCV,train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_auc_score2、導入數據
df = pd.read_csv("D:\WKS\PyProject\Credit_Card\creditcard.csv")
data=df.iloc[:,1:31]284807條交易記錄中只有492條欺詐記錄,樣本嚴重不平衡,這裏我們需要使用下採樣策略(減少多數類使其數量與少數類相同)
X = data.loc[:, data.columns != 'Class']
y = data.loc[:, data.columns == 'Class']
number_records_fraud = len(data[data.Class == 1]) # class=1的樣本函數
fraud_indices = np.array(data[data.Class == 1].index) # 樣本等於1的索引值
normal_indices = data[data.Class == 0].index # 樣本等於0的索引值
random_normal_indices = np.random.choice(normal_indices,number_records_fraud,replace = False)
random_normal_indices = np.array(random_normal_indices)
under_sample_indices = np.concatenate([fraud_indices,random_normal_indices]) # Appending the 2 indices
under_sample_data = data.iloc[under_sample_indices,:] # Under sample dataset
X_undersample = under_sample_data.loc[:,under_sample_data.columns != 'Class']
y_undersample = under_sample_data.loc[:,under_sample_data.columns == 'Class']
X_train, X_test, y_train, y_test = train_test_split(X_undersample,y_undersample,test_size = 0.3, random_state = 0)先用默認參數訓練RF
rf0 = RandomForestClassifier(oob_score=True, random_state=666)
rf0.fit(X_train,y_train)
print(rf0.oob_score_)
y_predprob = rf0.predict_proba(X_test)[:,1]
print("AUC Score (Train): %f" % roc_auc_score(y_test, y_predprob))0.9244186046511628
AUC Score (Train): 0.967082
除oob_score將默認的False改為True, 我們重點優化n_estimators、max_depth、min_samples_leaf 這三個參數。為簡單起見,模型評價指標,我們選擇AUC值。
模型調優我們採用網格搜索調優參數(grid search),通過構建參數候選集合,然後網格搜索會窮舉各種參數組合,根據設定評定的評分機制找到最好的那一組設置。
先優化n_estimators
param_test1 = {'n_estimators':range(10,101,10)}
gsearch1 = GridSearchCV(estimator = RandomForestClassifier(oob_score=True, random_state=666,n_jobs=2),
param_grid = param_test1, scoring='roc_auc',cv=5)
gsearch1.fit(X_train,y_train)
gsearch1.cv_results_, gsearch1.best_params_, gsearch1.best_score_{‘n_estimators’: 50},
0.9799524239675649)
在優化后的n_estimators基礎上,優化max_features
param_test2 = {'max_depth':range(2,12,2)}
gsearch2 = GridSearchCV(estimator = RandomForestClassifier(n_estimators= 50,oob_score=True, random_state=666,n_jobs=2),
param_grid = param_test2, scoring='roc_auc',cv=5)
gsearch2.fit(X_train,y_train)
gsearch2.cv_results_, gsearch2.best_params_, gsearch2.best_score_{‘max_depth’: 6},
0.9809897227343921)
在上述兩個參數優化結果的基礎上優化max_depth
param_test2 = {'min_samples_split':range(2,8,1)}
gsearch2 = GridSearchCV(estimator = RandomForestClassifier(n_estimators= 50,max_depth=6,
oob_score=True, random_state=666,n_jobs=2),
param_grid = param_test2, scoring='roc_auc',cv=5)
gsearch2.fit(X_train,y_train)
gsearch2.cv_results_, gsearch2.best_params_, gsearch2.best_score_{‘min_samples_split’: 5},
0.9819618127837587)
最後我們綜合再次嘗試
rf1 = RandomForestClassifier(n_estimators= 50,max_depth=6,min_samples_split=5,oob_score=True, random_state=666,n_jobs=2)
rf1.fit(X_train,y_train)
print(rf1.oob_score_)
y_predprob1 = rf1.predict_proba(X_test)[:,1]
print("AUC Score (Train): %f" % roc_auc_score(y_test, y_predprob1))0.9331395348837209
AUC Score (Train): 0.977811
最終結果比調參前有所提升
隨機森林優缺點總結
RF優點
1.不容易出現過擬合,因為選擇訓練樣本的時候就不是全部樣本。
2.可以既可以處理屬性為離散值的量,比如ID3算法來構造樹,也可以處理屬性為連續值的量,比如C4.5算法來構造樹。
3.對於高維數據集的處理能力令人興奮,它可以處理成千上萬的輸入變量,並確定最重要的變量,因此被認為是一個不錯的降維方法。此外,該模型能夠輸出變量的重要性程度,這是一個非常便利的功能。
4.分類不平衡的情況時,隨機森林能夠提供平衡數據集誤差的有效方法
RF缺點
1.隨機森林在解決回歸問題時並沒有像它在分類中表現的那麼好,這是因為它並不能給出一個連續型的輸出。當進行回歸時,隨機森林不能夠作出超越訓練集數據範圍的預測,這可能導致在對某些還有特定噪聲的數據進行建模時出現過度擬合。
2.對於許多統計建模者來說,隨機森林給人的感覺像是一個黑盒子——你幾乎無法控制模型內部的運行,只能在不同的參數和隨機種子之間進行嘗試。
參考:
https://www.jianshu.com/p/708dff71df3a
https://zhuanlan.zhihu.com/p/30461746
https://www.cnblogs.com/pinard/p/6156009.html
《百面機器學習》中有一道關於隨機森林的面試題,大家可以思考一下:
可否將隨機森林中的基分類器由決策樹替換為線性分類器或K-近鄰呢?
解答:隨機森林屬於Bagging類的集成學習,Bagging的主要好處是集成后的分類器的方差比基分類器方差小。Bagging採用的分類器最好是本身對樣本分佈比較敏感(即不穩定的分類器),這樣Bagging才有價值。線性分類器或K-近鄰都是比較穩定,本身方差就很小,所以以他們作為基分類器使用Bagging並不能獲得更好地表現,甚至可能因為Bagging的採樣導致訓練中更難收斂,從而增大集成分類器的偏差。
本文由博客一文多發平台 發布!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!



 第一,產業發展進入新階段,仍需發揮財政引導作用。新能源汽車已成為全球汽車產業新一輪競爭的焦點,國際上很多國家也都把新能源汽車的發展上升到國家戰略的高度,制定了很多強力的措施。 第二,發展新階段遇到新問題,財政政策繼續調整跟進。比如,新能源汽車在安全性、一致性方面還存在一些隱患、對補貼政策的依賴、核心技術的突破、充電設施建設存在瓶頸、產業大而不強重複建設等問題,尤其是騙取財政補貼的現象,財政部同各部委展開系列調查,目前調查結果已經上報國務院,存在騙補行為的企業必將受到應有的處罰。 第三,進一步完善財政政策,保證產業健康發展。具體一些想法和思路:一、配合工信部提高技術門檻上調整財政補貼;對技術進步、規範守信的企業正向激勵,提高准入門檻,補貼技術先進、市場認可度高的企業;二、完善補貼標準,在彌補市場差價,促進技術創新上實現基本平衡;三、健全監管體系,目前有必要建立互聯網的資訊監管平臺;四、建立市場化的發展機制,確保在財政補貼退坡後對產業的支持不斷。 文章來源:第一電動網
第一,產業發展進入新階段,仍需發揮財政引導作用。新能源汽車已成為全球汽車產業新一輪競爭的焦點,國際上很多國家也都把新能源汽車的發展上升到國家戰略的高度,制定了很多強力的措施。 第二,發展新階段遇到新問題,財政政策繼續調整跟進。比如,新能源汽車在安全性、一致性方面還存在一些隱患、對補貼政策的依賴、核心技術的突破、充電設施建設存在瓶頸、產業大而不強重複建設等問題,尤其是騙取財政補貼的現象,財政部同各部委展開系列調查,目前調查結果已經上報國務院,存在騙補行為的企業必將受到應有的處罰。 第三,進一步完善財政政策,保證產業健康發展。具體一些想法和思路:一、配合工信部提高技術門檻上調整財政補貼;對技術進步、規範守信的企業正向激勵,提高准入門檻,補貼技術先進、市場認可度高的企業;二、完善補貼標準,在彌補市場差價,促進技術創新上實現基本平衡;三、健全監管體系,目前有必要建立互聯網的資訊監管平臺;四、建立市場化的發展機制,確保在財政補貼退坡後對產業的支持不斷。 文章來源:第一電動網
 南都電源表示,孔輝汽車主營汽車電子控制系統研製與銷售、汽車整車及部件的試驗測試等業務。此次增資會增強公司在新能源汽車系統集成領域的能力,從而為公司向新能源汽車產業鏈的發展奠定相關的基礎。 文章來源:全景網
南都電源表示,孔輝汽車主營汽車電子控制系統研製與銷售、汽車整車及部件的試驗測試等業務。此次增資會增強公司在新能源汽車系統集成領域的能力,從而為公司向新能源汽車產業鏈的發展奠定相關的基礎。 文章來源:全景網
 今年3月底,斑馬快跑互聯網+新能源綠色通行大巴項目從武漢啟動,切入了巴士出行的蛋糕。李佳說,斑馬巴士免費運營3個月以後,斑馬紋已經給當地社會帶來了品牌效應,並且上座率也實現了98%,新的盈利點破局。據悉,本月斑馬快跑即將上線第一批七座乘用車並將在年底鋪開。 關於以後發展方向,斑馬快跑希望能做最大的新能源車輛運營商,打造車、樁、網的“斑馬雲”,做成武漢這座城市的互聯網名片。日前,定制物流車型“東風斑馬”已由工信部《道路機動車輛生產企業及產品公告》車輛新產品公示發佈,斑馬快跑迎來又一個里程碑,讓車輛從一出廠即將帶有斑馬紋。 文章來源:CNEV-H
今年3月底,斑馬快跑互聯網+新能源綠色通行大巴項目從武漢啟動,切入了巴士出行的蛋糕。李佳說,斑馬巴士免費運營3個月以後,斑馬紋已經給當地社會帶來了品牌效應,並且上座率也實現了98%,新的盈利點破局。據悉,本月斑馬快跑即將上線第一批七座乘用車並將在年底鋪開。 關於以後發展方向,斑馬快跑希望能做最大的新能源車輛運營商,打造車、樁、網的“斑馬雲”,做成武漢這座城市的互聯網名片。日前,定制物流車型“東風斑馬”已由工信部《道路機動車輛生產企業及產品公告》車輛新產品公示發佈,斑馬快跑迎來又一個里程碑,讓車輛從一出廠即將帶有斑馬紋。 文章來源:CNEV-H
 據工信部資料統計,自2009以來,中國新能源汽車安全事故共31例,其中2015年以來發生17起,在這17起事故中有4起是電池系統的事故、有6起是相關部件的事故、有2起是充電系統缺陷引起的,當然還有5起是違規改裝或者不當使用引起的。截至2015年底,事故率達到0.17‰,高出世界平均水準。 工業和資訊化部裝備工業司司長李東表示:「國家已經組織制定了電動汽車遠端監控標準,並且電動客車安全條件即將發佈實施。電池管理系統技術條件、動力電池的編碼、規格尺寸等標準正在編制、修訂,並且也要儘快出臺。與此同時,正在組織修訂新能源汽車生產企業和產品准入規則,擬大幅度提高企業的研發能力和生產條件要求,提高性能和安全的要求。」 文章來源:證券時報
據工信部資料統計,自2009以來,中國新能源汽車安全事故共31例,其中2015年以來發生17起,在這17起事故中有4起是電池系統的事故、有6起是相關部件的事故、有2起是充電系統缺陷引起的,當然還有5起是違規改裝或者不當使用引起的。截至2015年底,事故率達到0.17‰,高出世界平均水準。 工業和資訊化部裝備工業司司長李東表示:「國家已經組織制定了電動汽車遠端監控標準,並且電動客車安全條件即將發佈實施。電池管理系統技術條件、動力電池的編碼、規格尺寸等標準正在編制、修訂,並且也要儘快出臺。與此同時,正在組織修訂新能源汽車生產企業和產品准入規則,擬大幅度提高企業的研發能力和生產條件要求,提高性能和安全的要求。」 文章來源:證券時報










