一、緩存總覽
Mybatis在設計上處處都有用到的緩存,而且Mybatis的緩存體系設計上遵循單一職責、開閉原則、高度解耦。及其精巧,充分的將緩存分層,其獨到之處可以套用到很多類似的業務上。這裏將主要的緩存體系做一下簡單的分析筆記。以及藉助Mybatis緩存體系的學習,進一步窺探責任鏈派發模式企業級實踐,以及對象循環依賴場景下如何避免裝載死循環的企業級解決方案。
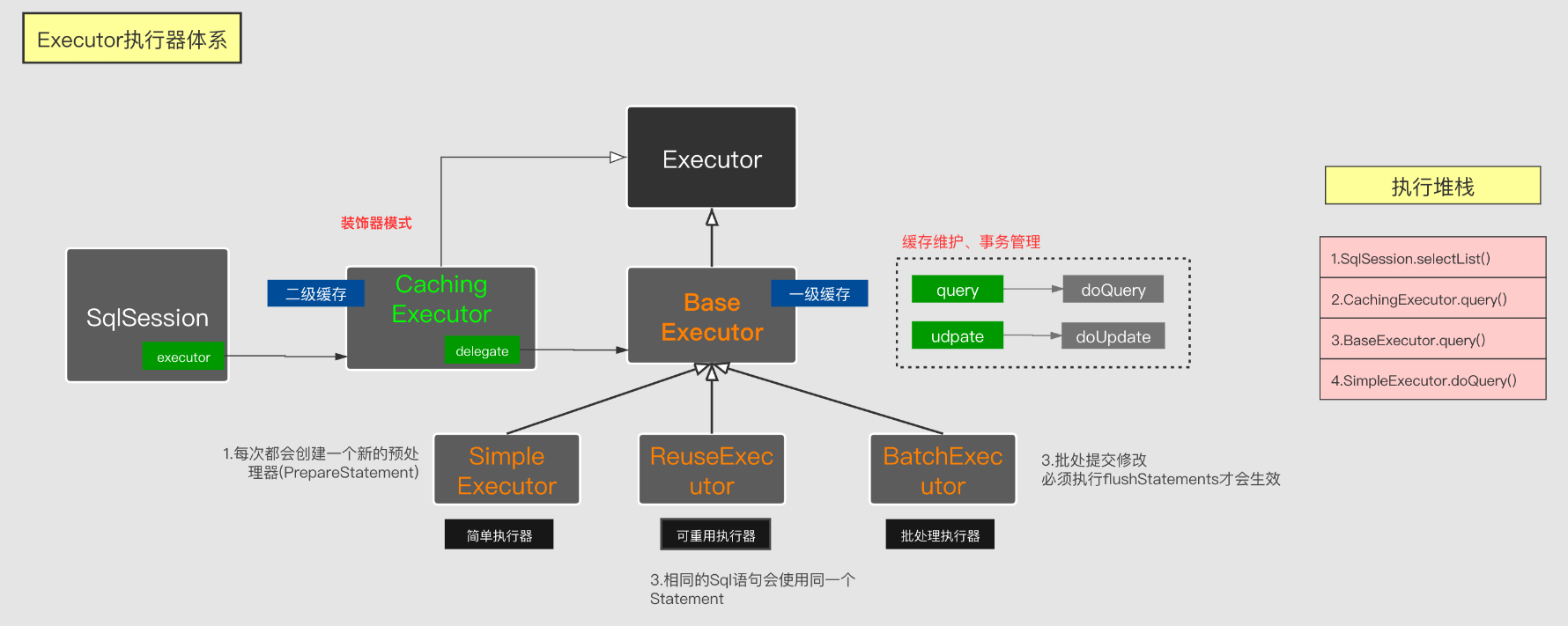
先來一張之前的執行體系圖:
對照這張執行圖,不難看出,其實對於一次Mybatis查詢調用,即SqlSession -> SimpleExecutor/ReuseExecutor/BatchExecutor -> JDBC,其實緩存就是在SqlSession到Executor*之間做一層截獲請求的邏輯。從宏觀上很好理解。CachingExecutor作為BaseExecutor的一個前置增強裝飾器,其增強的功能就是,判斷是否命中了緩存,如果命中緩存,則不進行BaseExecutor的執行派發。
1 public class CachingExecutor implements Executor {
2 // BaseExecutor
3 private final Executor delegate;
4 public CachingExecutor(Executor delegate) {
5 this.delegate = delegate;
6 delegate.setExecutorWrapper(this);
7 }
8 @Override
9 public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
10 throws SQLException {
11 Cache cache = ms.getCache();
12 if (cache != null) {
13 flushCacheIfRequired(ms);
14 if (ms.isUseCache() && resultHandler == null) {
15 ensureNoOutParams(ms, boundSql);
16 List<E> list = (List<E>) tcm.getObject(cache, key);
17 if (list == null) {
18 list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
19 tcm.putObject(cache, key, list); // issue #578 and #116
20 }
21 return list;
22 }
23 }
24 // 如果未命中緩存則向BaseExecutor派發
25 return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
26 }
27 }
所以由此來看,mybatis的緩存是先嘗試命中CachingExecutor的二級緩存,如果未命中,則派發個BaseExecutor,下來才會去嘗試命中一級緩存。由於一級緩存比較簡單,我們先來看一級緩存。
二、一級緩存概覽
之前執行器的那一節講過,Mybatis的執行器和SqlSession都是一對一的關係
1 public class DefaultSqlSession implements SqlSession {
2 // ...
3 private final Executor executor;
4 // ...
5 }
而每個執行器裡邊用一個成員變量來做緩存容器
1 public abstract class BaseExecutor implements Executor {
2 // ...
3 protected PerpetualCache localCache;
4 // ...
5 }
那麼也就是說,一旦SqlSession關閉,即對象銷毀,必然BaseExecutor對象銷毀,所以一級緩存容器跟着銷毀。由此可以推到出:一級緩存是SqlSession級別的緩存。也就是要命中一級緩存,必須是同一個SqlSession,而且未關閉。
再來看一下一級緩存是如何設置緩存的:
1 public abstract class BaseExecutor implements Executor {
2 protected PerpetualCache localCache;
3 @Override
4 public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
5 BoundSql boundSql = ms.getBoundSql(parameter);
6 CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
7 return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
8 }
9 @Override
10 public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
11 ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
12 if (closed) {
13 throw new ExecutorException("Executor was closed.");
14 }
15 if (queryStack == 0 && ms.isFlushCacheRequired()) {
16 clearLocalCache();
17 }
18 List<E> list;
19 try {
20 queryStack++;
21 list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
22 if (list != null) {
23 handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
24 } else {
25 list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
26 }
27 } finally {
28 queryStack--;
29 }
30 if (queryStack == 0) {
31 for (DeferredLoad deferredLoad : deferredLoads) {
32 deferredLoad.load();
33 }
34 // issue #601
35 deferredLoads.clear();
36 if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
37 // issue #482
38 clearLocalCache();
39 }
40 }
41 return list;
42 }
43 }
通過這一段源碼,可以看到,是在第6行去構建緩存key,在第21行嘗試獲取緩存。構建緩存key,取決於四個維度:MappedStatement(同一個statementId)、parameter(同樣的查詢參數)、RowBounds(同樣的行數)、BoundsSql(同樣的SQL),加上上邊SqlSession的條件,一級緩存的命中條件為:相同的SqlSession、statementId、parameter、行數、Sql,才能命中一級緩存。
這裡在說一句題外話,就是當mybatis與Spring集成時,SqlSession的管理就交給Spring框架了,每次Mybatis的查詢都會由Spring框架新建一個Sqlsession供mybatis用,看起來一級緩存永遠失效。解決辦法就是給查詢加上事務,當加上事務的時候,Spring框架會保證在一個事務裡邊只提供給mybatis同一個SqlSession對象。
再看下一級緩存何時會被刷新掉,來上源碼:
1 public abstract class BaseExecutor implements Executor {
2 protected PerpetualCache localCache;
3 @Override
4 public void close(boolean forceRollback) {
5 try {
6 try {
7 rollback(forceRollback);
8 } finally {
9 if (transaction != null) {
10 transaction.close();
11 }
12 }
13 } catch (SQLException e) {
14 log.warn("Unexpected exception on closing transaction. Cause: " + e);
15 } finally {
16 transaction = null;
17 deferredLoads = null;
18 localCache = null;
19 localOutputParameterCache = null;
20 closed = true;
21 }
22 }
23 @Override
24 public int update(MappedStatement ms, Object parameter) throws SQLException {
25 ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
26 if (closed) {
27 throw new ExecutorException("Executor was closed.");
28 }
29 clearLocalCache();
30 return doUpdate(ms, parameter);
31 }
32 @Override
33 public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
34 if (queryStack == 0 && ms.isFlushCacheRequired()) {
35 clearLocalCache();
36 }
37 if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
38 clearLocalCache();
39 }
40 }
41 @Override
42 public void commit(boolean required) throws SQLException {
43 clearLocalCache();
44 }
45
46 @Override
47 public void rollback(boolean required) throws SQLException {
48 if (!closed) {
49 try {
50 clearLocalCache();
51 flushStatements(true);
52 } finally {
53 if (required) {
54 transaction.rollback();
55 }
56 }
57 }
58 }
59
60 @Override
61 public void clearLocalCache() {
62 if (!closed) {
63 localCache.clear();
64 localOutputParameterCache.clear();
65 }
66 }
對於這段源碼,清除緩存的場景,着重關注一下clearLocalCache的調用的地方:
即觸發更新操作(第29行)、配置flushCache=true(第35行)、配置緩存作用於為STATEMENT(第38行)、commit時候(第42行)、rollback時候(第50行)、執行器關閉時候(第7行)都會清除一級緩存。
三、一級緩存對於嵌套子查詢循環依賴場景的解決方案
循環依賴的情況處處可見,比如:一個班主任,下邊有多個學生,每個學生又有一個對應的班主任。
對於班主任和學生這種場景,在mybatis層面屬於典型的嵌套子查詢。mybatis在處理嵌套查詢的時候,都會查詢,然後在設置屬性的時候,如果發現有子查詢,則發起子查詢。那麼,如果不加特殊干預,這種場景將會陷入設置屬性觸發查詢的死循環中。
1 <select id="selectHeadmasterById" resultMap="teacherMap">
2 select * from teacher where id = #{id}
3 </select>
4 <resultMap id="teacherMap" type="Teacher" autoMapping="true">
5 <result column="name" property="name"/>
6 <collection property="students" column="id" select="selectStudentsByTeacherId" fetchType="eager"/>
7 </resultMap>
8 <select id="selectStudentsByTeacherId" resultMap="studentMap">
9 select * from student where teacher_id = #{teacherId}
10 </select>
11 <resultMap id="studentMap" type="comment">
12 <association property="teacher" column="teacher_id" select="selectHeadmasterById" fetchType="eager"/>
13 </resultMap>
mybatis在處理這種情況的時候,巧妙的用了一個臨時一級緩存佔位符與延遲裝載(不同於懶加載),解決了查詢死循環的問題。這裏我們直接上源碼:
每次查詢,如果沒有命中有效緩存(即非佔位符緩存)mybatis都會事先給一級緩存寫入一個佔位符,待數據庫查詢完畢后,再將真正的數據覆蓋掉佔位符緩存。
1 public abstract class BaseExecutor implements Executor {
2 protected ConcurrentLinkedQueue<DeferredLoad> deferredLoads;
3 protected PerpetualCache localCache;
4 protected int queryStack;
5 @Override
6 public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
7 ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
8 if (closed) {
9 throw new ExecutorException("Executor was closed.");
10 }
11 if (queryStack == 0 && ms.isFlushCacheRequired()) {
12 clearLocalCache();
13 }
14 List<E> list;
15 try {
16 queryStack++;
17 list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
18 if (list != null) {
19 handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
20 } else {
21 // 如果未獲取到緩存則查庫
22 list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
23 }
24 } finally {
25 queryStack--;
26 }
27 if (queryStack == 0) {
28 for (DeferredLoad deferredLoad : deferredLoads) {
29 deferredLoad.load();
30 }
31 deferredLoads.clear();
32 if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
33 clearLocalCache();
34 }
35 }
36 return list;
37 }
38 }
如上Query方法的第22行進去:
1 private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
2 List<E> list;
3 // 查庫之前先設置佔位符緩存
4 localCache.putObject(key, EXECUTION_PLACEHOLDER);
5 try {
6 list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
7 } finally {
8 localCache.removeObject(key);
9 }
10 localCache.putObject(key, list);
11 if (ms.getStatementType() == StatementType.CALLABLE) {
12 localOutputParameterCache.putObject(key, parameter);
13 }
14 return list;
15 }
BaseExecutor.queryFromDataBase方法的第6行,會觸發數據庫查詢,緊接着會進入結果值設定的邏輯。那麼首先會探測有無嵌套的子查詢,如果有,則前一步主查詢暫時等待,立即發起子查詢。
1 private Object getNestedQueryMappingValue(ResultSet rs, MetaObject metaResultObject, ResultMapping propertyMapping, ResultLoaderMap lazyLoader, String columnPrefix)
2 throws SQLException {
3 final String nestedQueryId = propertyMapping.getNestedQueryId();
4 final String property = propertyMapping.getProperty();
5 final MappedStatement nestedQuery = configuration.getMappedStatement(nestedQueryId);
6 final Class<?> nestedQueryParameterType = nestedQuery.getParameterMap().getType();
7 final Object nestedQueryParameterObject = prepareParameterForNestedQuery(rs, propertyMapping, nestedQueryParameterType, columnPrefix);
8 Object value = null;
9 if (nestedQueryParameterObject != null) {
10 final BoundSql nestedBoundSql = nestedQuery.getBoundSql(nestedQueryParameterObject);
11 final CacheKey key = executor.createCacheKey(nestedQuery, nestedQueryParameterObject, RowBounds.DEFAULT, nestedBoundSql);
12 final Class<?> targetType = propertyMapping.getJavaType();
13 // 判斷當前的子查詢是否和之前的某一步主查詢相同
14 if (executor.isCached(nestedQuery, key)) {
15 executor.deferLoad(nestedQuery, metaResultObject, property, key, targetType);
16 value = DEFERRED;
17 } else {
18 final ResultLoader resultLoader = new ResultLoader(configuration, executor, nestedQuery, nestedQueryParameterObject, targetType, key, nestedBoundSql);
19 if (propertyMapping.isLazy()) {
20 lazyLoader.addLoader(property, metaResultObject, resultLoader);
21 value = DEFERRED;
22 } else {
23 // 立即發起子查詢
24 value = resultLoader.loadResult();
25 }
26 }
27 }
28 return value;
29 }
這塊重點關注第13行和第23行。其中第23行又會遞歸到上邊BaseExecutor.query代碼片段的第22行。如果getNestedQueryMappingValue代碼段走的是滴15行邏輯,那麼,會對應BaseExecutor.query代碼片段的第28行。這塊遞歸比較繞。下來做下通俗的解釋:
首先查詢班主任的主查詢給一級緩存寫入一個佔位符緩存,然後去查庫,然後設定屬性,如果沒有嵌套子查詢,那麼到這裏就把設置好屬性的值寫入覆蓋剛才一級佔位符緩存。流暢完畢。
但是恰好有嵌套子查詢,所以查詢班主任的主查詢就停在設置屬性這一步,然後又發起一次查詢,查詢學生,然後又進入查詢學生設定屬性的方法。
設定學生屬性方法又發現又有嵌套子查詢,所以有發起一次學生查詢班主任的查詢操作,又進入到設定屬性這塊,但是發現一級緩存裡邊有前邊住查詢的站位緩存。所以沒有在查庫,而是將本次子查詢放入延遲裝載的容器裡邊。本次子查詢結束。緊接着前一步子查詢(老師查學生)結束。
緊接着查詢老師的住查詢設定屬性完畢,並將自己的結果覆蓋之前寫入的站位緩存。同時啟動了延時裝載的邏輯,延時裝載就是從一級緩存取出剛才查詢老師的一級緩存數據(老師),給第二步子查詢(學生)做一下MetaObject屬性設置。
說的通俗一點:主查詢(查班主任)執行時先寫入站位緩存,緊接着掛起,發起第一個嵌套子查詢(用老師查學生),緊接着該子查詢再掛起,發起學生查老師,但是發現第一步主查詢有一級緩存(站位緩存),那麼本次子查詢自動加入延遲裝載隊列,然後終結改子查詢,等待主查詢真正查完,然後延遲裝載器再從緩存取出數據給第一個子查詢(老師查學生)進行屬性設定。
說了這麼多,肯定暈車了,這裏給出一個時序圖:
總結一下:
1、佔位符緩存作用在於標識與當前查詢相同的前邊的嵌套查詢。比如:查詢學生所屬班主任,發現前邊的主查詢就是查詢班主任,所以就不在執行班主任查詢。等待真正的班主任查詢完畢,我們只需去緩存裡邊取即可。所以我們不執行查詢,只是將本次屬性設置放入延遲裝載隊列即可。
2、queryStack用來記錄當前查詢處於嵌套的第幾層。當queryStack == 0時,證明整個查詢已經回歸到最初的主查詢上,此時,所有過程中需要延遲裝載的對象,都能啟動真實裝載了。
3、一級緩存在解決嵌套子查詢屬性設置循環依賴上啟至關作用。所以以及緩存是不能完全關閉的。但是我們可以設置:LocalCacheScope.STATEMENT,來讓一級緩存及時清空。參見源碼
1 public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
2 // ...
3 try {
4 queryStack++;
5 list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
6 if (list != null) {
7 handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
8 } else {
9 list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
10 }
11 } finally {
12 queryStack--;
13 }
14 if (queryStack == 0) {
15 for (DeferredLoad deferredLoad : deferredLoads) {
16 deferredLoad.load();
17 }
18 deferredLoads.clear();
19 // 設置LocalCacheScope.STATEMENT來及時清空緩存
20 if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
21 clearLocalCache();
22 }
23 }
24 return list;
25 }
四、二級緩存
來先上一個二級緩存的執行流程:
二級緩存是BaseExecutor的前置增強包裝類CachingExecutor裡邊實現的,即如果從CachingExecutor裡邊命中緩存,則不進行BaseExecutor的派發(如下第14行)。
1 public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
2 throws SQLException {
3 Cache cache = ms.getCache();
4 if (cache != null) {
5 flushCacheIfRequired(ms);
6 if (ms.isUseCache() && resultHandler == null) {
7 ensureNoOutParams(ms, parameterObject, boundSql);
8 @SuppressWarnings("unchecked")
9 List<E> list = (List<E>) tcm.getObject(cache, key);
10 if (list == null) {
11 list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
12 tcm.putObject(cache, key, list); // issue #578 and #116
13 }
14 return list;
15 }
16 }
17 return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
18 }
11行與17行的區別在於,是否啟動二級緩存,如果啟動了,則將派發給BaseExecutor的查詢結果寫入暫存區(第12行,TransactionCacheManager),等事務提交在真正刷入二級緩存。下來我們重點來關注一下緩存的讀寫(第9行、第12行),這裏邊真正的執行對象是一系列Cache接口的實現,按職責有:線程安全、日誌記錄、過期清理、溢出淘汰、序列化、執行存儲等等環節。而二級緩存的設計精巧之處就在於此處,完美的按職責進行責任派發,完全解耦。
接下來我們來看下,默認情況下,緩存責任鏈的初始化過程:
1 public Cache useNewCache(Class<? extends Cache> typeClass,
2 Class<? extends Cache> evictionClass,
3 Long flushInterval,
4 Integer size,
5 boolean readWrite,
6 boolean blocking,
7 Properties props) {
8 Cache cache = new CacheBuilder(currentNamespace)
9 // 這裏設置默認的存儲為內存
10 .implementation(valueOrDefault(typeClass, PerpetualCache.class))
11 // 這裏設置默認的溢出淘汰為LRU
12 .addDecorator(valueOrDefault(evictionClass, LruCache.class))
13 .clearInterval(flushInterval)
14 .size(size)
15 .readWrite(readWrite)
16 .blocking(blocking)
17 .properties(props)
18 .build();
19 configuration.addCache(cache);
20 currentCache = cache;
21 return cache;
22 }
然後是初始化過程:
1 public Cache build() {
2 setDefaultImplementations();
3 Cache cache = newBaseCacheInstance(implementation, id);
4 setCacheProperties(cache);
5 // issue #352, do not apply decorators to custom caches
6 if (PerpetualCache.class.equals(cache.getClass())) {
7 for (Class<? extends Cache> decorator : decorators) {
8 cache = newCacheDecoratorInstance(decorator, cache);
9 setCacheProperties(cache);
10 }
11 cache = setStandardDecorators(cache);
12 } else if (!LoggingCache.class.isAssignableFrom(cache.getClass())) {
13 cache = new LoggingCache(cache);
14 }
15 return cache;
16 }
17 private Cache setStandardDecorators(Cache cache) {
18 try {
19 MetaObject metaCache = SystemMetaObject.forObject(cache);
20 if (size != null && metaCache.hasSetter("size")) {
21 metaCache.setValue("size", size);
22 }
23 if (clearInterval != null) {
24 cache = new ScheduledCache(cache);
25 ((ScheduledCache) cache).setClearInterval(clearInterval);
26 }
27 if (readWrite) {
28 cache = new SerializedCache(cache);
29 }
30 cache = new LoggingCache(cache);
31 cache = new SynchronizedCache(cache);
32 if (blocking) {
33 cache = new BlockingCache(cache);
34 }
35 return cache;
36 } catch (Exception e) {
37 throw new CacheException("Error building standard cache decorators. Cause: " + e, e);
38 }
39 }
這裏從第3、8、24、28、30、31、33行分別進行了責任裝飾初始化。這種依據職責分別拆分然後嵌套的解耦方式,其實是一種很成熟的企業級責任派發設計模式。而且形如第8行的循環裝飾嵌套,在很多開源框架中都能見到,比如Dubbo的AOP機制就是這樣初始化的。
下邊直接列一下Mybatis的二級緩存在設計上所覆蓋的功能,以及各功能責任鏈派發的結構圖:
從上邊的代碼可以看出,如果設置了blocking的話,那麼最外層將會包裹BlockingCache、下來是SynchronizedCache,這兩個均是進行線程安全,防止緩存穿透的處理。
1 public class BlockingCache implements Cache {
2 private final Cache delegate;
3 private final ConcurrentHashMap<Object, ReentrantLock> locks;
4 public BlockingCache(Cache delegate) {
5 this.delegate = delegate;
6 this.locks = new ConcurrentHashMap<Object, ReentrantLock>();
7 }
8 @Override
9 public void putObject(Object key, Object value) {
10 try {
11 delegate.putObject(key, value);
12 } finally {
13 releaseLock(key);
14 }
15 }
16 @Override
17 public Object getObject(Object key) {
18 acquireLock(key);
19 Object value = delegate.getObject(key);
20 if (value != null) {
21 releaseLock(key);
22 }
23 return value;
24 }
25 }
1 public class SynchronizedCache implements Cache {
2 private Cache delegate;
3 @Override
4 public synchronized void putObject(Object key, Object object) {
5 delegate.putObject(key, object);
6 }
7 @Override
8 public synchronized Object getObject(Object key) {
9 return delegate.getObject(key);
10 }
11 }
再看一下負責溢出淘汰的LruCache:
1 public class LruCache implements Cache {
2 private final Cache delegate;
3 private Map<Object, Object> keyMap;
4 // 記錄當溢出時,需要淘汰的Key
5 private Object eldestKey;
6 public void setSize(final int size) {
7 // LinkedHashMap.accessOrder設置為true,即,每個被訪問的元素會一次放到隊列末尾。當溢出的時候就能從首部來移除了
8 keyMap = new LinkedHashMap<Object, Object>(size, .75F, true) {
9 @Override
10 protected boolean removeEldestEntry(Map.Entry<Object, Object> eldest) {
11 boolean tooBig = size() > size;
12 if (tooBig) {
13 eldestKey = eldest.getKey();
14 }
15 return tooBig;
16 }
17 };
18 }
19 @Override
20 public void putObject(Object key, Object value) {
21 delegate.putObject(key, value);
22 cycleKeyList(key);
23 }
24 private void cycleKeyList(Object key) {
25 keyMap.put(key, key);
26 if (eldestKey != null) {
27 delegate.removeObject(eldestKey);
28 eldestKey = null;
29 }
30 }
31 }
二級緩存就講到這裏,總結一下二級緩存件:
1、默認開啟,cachEnable開關。作用於提交后。
2、相同的StatementId。
3、相同的SQL、參數、行數。
4、跨Mapper調用。
五、總結
雖然在目前各種分佈式應用的場景下,一級緩存和二級緩存都有很大概率的臟讀現象,而被禁止,但是Mybatis對這種局部場景的設計是及其精巧的。比如,解決對象循環嵌套查詢的場景設計,其實這種成熟的解決方案也被Spring(也存在對象循環注入的情景)所應用。以及責任裝飾的設計,Dubbo同樣在使用。其實我們能從得到很多啟發,比如,對於既定的業務場景,要加入現成安全的考量,那在不侵入業務代碼的前提下,我們是否也能增加一層責任裝飾,進行派發來完成呢?
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?
※網頁設計最專業,超強功能平台可客製化
※產品缺大量曝光嗎?你需要的是一流包裝設計!