一、摘要
在集合系列的第一章,咱們了解到,Map 的實現類有 HashMap、LinkedHashMap、TreeMap、IdentityHashMap、WeakHashMap、Hashtable、Properties 等等。
本文主要從數據結構和算法層面,探討 WeakHashMap 的實現。
二、簡介
剛剛咱們也介紹了,在 Map 家族中,WeakHashMap 是一個很特殊的成員,它的特殊之處在於 WeakHashMap 里的元素可能會被 GC 自動刪除,即使程序員沒有显示調用 remove() 或者 clear() 方法。
換言之,當向 WeakHashMap 中添加元素的時候,再次遍歷獲取元素,可能發現它已經不見了,我們來看看下面這個例子。
public static void main(String[] args) {
Map weakHashMap = new WeakHashMap();
//向weakHashMap中添加4個元素
for (int i = 0; i < 3; i++) {
weakHashMap.put("key-"+i, "value-"+ i);
}
//輸出添加的元素
System.out.println("數組長度:"+weakHashMap.size() + ",輸出結果:" + weakHashMap);
//主動觸發一次GC
System.gc();
//再輸出添加的元素
System.out.println("數組長度:"+weakHashMap.size() + ",輸出結果:" + weakHashMap);
}
輸出結果:
數組長度:3,輸出結果:{key-2=value-2, key-1=value-1, key-0=value-0}
數組長度:3,輸出結果:{}
當主動調用 GC 回收器的時候,再次查詢 WeakHashMap 裏面的數據的時候,內容為空。
更直觀的說,當使用 WeakHashMap 時,即使沒有顯式的添加或刪除任何元素,也可能發生如下情況:
- 調用兩次 size() 方法返回不同的值;
- 兩次調用 isEmpty() 方法,第一次返回 false,第二次返回 true;
- 兩次調用 containsKey() 方法,第一次返回 true,第二次返回 false,儘管兩次使用的是同一個key;
- 兩次調用 get() 方法,第一次返回一個 value,第二次返回 null,儘管兩次使用的是同一個對象。
要明白 WeekHashMap 的工作原理,還需要引入一個概念:弱引用。
我們都知道 Java 中內存是通過 GC 自動管理的,GC 會在程序運行過程中自動判斷哪些對象是可以被回收的,並在合適的時機進行內存釋放。
GC 判斷某個對象是否可被回收的依據是,是否有有效的引用指向該對象。如果沒有有效引用指向該對象(基本意味着不存在訪問該對象的方式),那麼該對象就是可回收的。
2.1、對象引用介紹
從 JDK1.2 版本開始,把對象的引用分為四種級別,從而使程序更加靈活的控制對象的生命周期。這四種級別由高到低依次為:強引用、軟引用、弱引用和虛引用。
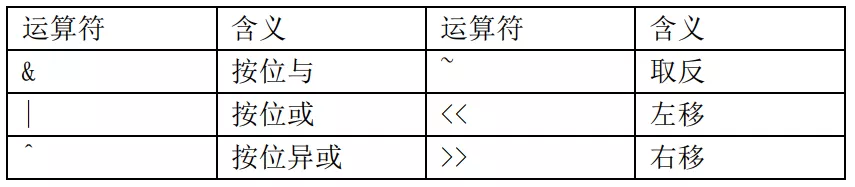
用表格整理之後,各個引用類型的區別如下:
2.1.1、強引用
強引用是使用最普遍的引用,例如,我們創建一個對象:
//強引用類型
Object object=new Object();
如果一個對象具有強引用,那垃圾回收器絕不會回收它。當內存空間不足, Java 虛擬機寧願拋出 OutOfMemoryError 錯誤,使程序異常終止,也不會靠隨意回收具有強引用的對象來解決內存不足的問題。
如果不使用時,要手動通過如下方式來弱化引用,如下:
//將對象設置為null,幫助垃圾收集器回收此對象
object=null;
這個時候,GC 認為該對象不存在引用,就可以回收這個對象,具體什麼時候收集這要取決於 GC 的算法。
2.1.2、軟引用
被SoftReference指向的對象,屬於軟引用,如下:
String str=new String("abc");
//軟引用
SoftReference<String> softRef=new SoftReference<String>(str);
如果一個對象只具有軟引用,則內存空間足夠,垃圾回收器就不會回收它;如果內存空間不足了,就會進入垃圾回收器,Java 虛擬機就會把這個軟引用加入到與之關聯的引用隊列中,GC 進行回收處理。只要垃圾回收器沒有回收它,該對象就可以被程序使用。
當內存不足時,等價於:
If(JVM.內存不足()) {
str = null; // 轉換為軟引用
System.gc(); // 垃圾回收器進行回收
}
軟引用的這種特性,比較適合內存敏感的場景,做高速緩存。在某些場景下,比如,系統內存不是很足的情況下,可以使用軟引用,GC 會自動回收,再次獲取對象的時候,可以對緩存對象進行重建,而又不影響使用。比如:
//創建一個緩存內容cache
String cache = new String("abc");
//進行軟引用處理
SoftReference<String> softRef=new SoftReference<String>(cache);
//判斷是否被垃圾回收器回收
if(softRef.get()!=null){
//還沒有被回收器回收,直接獲取
cache = (String) softRef.get();
}else{
//由於內存吃緊,所以對軟引用的對象回收了
//重建緩存對象
cache = new String("abc");
SoftReference<String> softRef = new SoftReference<String>(cache);
}
2.1.3、弱引用
被WeakReference指向的對象,屬於弱引用,如下:
String str=new String("abc");
//弱引用
WeakReference<String> abcWeakRef = new WeakReference<String>(str);
弱引用與軟引用的區別在於:具有弱引用的對象擁有更短暫的生命周期。
在垃圾回收器線程掃描它所管轄的內存區域的過程中,一旦發現了只具有弱引用的對象,不管當前內存空間足夠與否,都會回收它的內存。不過,由於垃圾回收器是一個優先級很低的線程,因此不一定會很快發現那些只具有弱引用的對象。
當垃圾回收器進行掃描回收時,等價於:
str = null;
System.gc();
如果這個對象是偶爾的使用,並且希望在使用時隨時就能獲取到,但又不想影響此對象的垃圾收集,那麼你應該用 WeakReference 來記住此對象。
同樣的,弱引用對象進入垃圾回收器,Java虛擬機就會把這個弱引用加入到與之關聯的引用隊列中,GC 進行回收處理。
2.1.4、虛引用
被PhantomReference指向的對象,屬於虛引用。
虛引用與軟引用和弱引用的一個區別在於:虛引用必須和引用隊列聯合使用,如下:
String str=new String("abc");
//創建引用隊列
ReferenceQueue<String> queue = new ReferenceQueue<String>();
//創建虛引用
PhantomReference<String> phantomReference = new PhantomReference<String>(str, queue);
虛引用,顧名思義,就是形同虛設,與其他幾種引用都不同,虛引用並不會決定對象的生命周期。如果一個對象僅持有虛引用,那麼它就和沒有任何引用一樣,在任何時候都可能被垃圾回收器回收。
當垃圾回收器準備回收一個對象時,如果發現它是虛引用,就會在回收對象的內存之前,把這個虛引用加入到與之關聯的引用隊列中,GC 進行回收處理。
2.1.5、總結
Java 4中引用的級別由高到低依次為:強引用 > 軟引用 > 弱引用 > 虛引用。
用一張圖來看一下他們之間在垃圾回收時的區別:
再次回到本文要講的 WeakHashMap!
WeakHashMap 內部是通過弱引用來管理 entry 的,弱引用的特性對應到 WeakHashMap 上意味着什麼呢?將一對 key, value 放入到 WeakHashMap 里,隨時都有可能被 GC 回收。
下面,咱們一起來看看 WeakHashMap 的具體實現。
三、常用方法介紹
3.1、put方法
put 方法是將指定的 key, value 對添加到 map 里,存儲結構類似於 HashMap;
不同的是,WeakHashMap 中存儲的 Entry 繼承自 WeakReference,實現了弱引用。
打開源碼如下:
public V put(K key, V value) {
Object k = maskNull(key);
int h = hash(k);
Entry<K,V>[] tab = getTable();
int i = indexFor(h, tab.length);
for (Entry<K,V> e = tab[i]; e != null; e = e.next) {
if (h == e.hash && eq(k, e.get())) {
V oldValue = e.value;
if (value != oldValue)
e.value = value;
return oldValue;
}
}
modCount++;
Entry<K,V> e = tab[i];
tab[i] = new Entry<>(k, value, queue, h, e);
if (++size >= threshold)
resize(tab.length * 2);
return null;
}
WeakHashMap 中存儲的 Entry,源碼如下:
private static class Entry<K,V> extends WeakReference<Object> implements Map.Entry<K,V> {
V value;
final int hash;
Entry<K,V> next;
Entry(Object key, V value,
ReferenceQueue<Object> queue,
int hash, Entry<K,V> next) {
//將key進行弱引用處理
super(key, queue);
this.value = value;
this.hash = hash;
this.next = next;
}
......
}
需要注意的是,Entry 中super(key, queue),傳入的是key,因此key才是進行弱引用的,value是直接強引用關聯在this.value中,System.gc()時,對key進行了回收,而value依然保持。
那value是何時被清除的呢?
閱讀源碼,可以看到,調用getTable()函數,對調用expungeStaleEntries()函數,該方法對 jvm 要回收的的 entry(quene 中) 進行遍歷,並將 entry 的 value 設置為空,進行內存回收。
private Entry<K,V>[] getTable() {
expungeStaleEntries();
return table;
}
expungeStaleEntries()函數,源碼如下:
private void expungeStaleEntries() {
for (Object x; (x = queue.poll()) != null; ) {
synchronized (queue) {
Entry<K,V> e = (Entry<K,V>) x;
int i = indexFor(e.hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> p = prev;
while (p != null) {
Entry<K,V> next = p.next;
if (p == e) {
if (prev == e)
table[i] = next;
else
prev.next = next;
//將value設置為null,方便GC回收
e.value = null; // Help GC
size--;
break;
}
prev = p;
p = next;
}
}
}
}
所以效果是 key 在 GC 的時候被清除,value 在 key 清除后,訪問數組內容的時候進行清除!
3.2、get方法
get 方法根據指定的 key 值返回對應的 value。
源碼如下:
public V get(Object key) {
Object k = maskNull(key);
int h = hash(k);
//訪問數組內容
Entry<K,V>[] tab = getTable();
int index = indexFor(h, tab.length);
Entry<K,V> e = tab[index];
while (e != null) {
//通過key,進行hash值和equals判斷
if (e.hash == h && eq(k, e.get()))
return e.value;
e = e.next;
}
return null;
}
同樣的,get 方法在判斷對象之前,也調用了getTable()函數,同時,也調用了expungeStaleEntries()函數,所以,可能通過 key 獲取元素的時候,得到空值;如果 key 沒有被 GC 回收,那麼就返回對應的 value。
3.3、remove方法
remove 的作用是通過 key 刪除對應的元素。
源碼如下:
public V remove(Object key) {
Object k = maskNull(key);
int h = hash(k);
//訪問數組內容
Entry<K,V>[] tab = getTable();
int i = indexFor(h, tab.length);
Entry<K,V> prev = tab[i];
Entry<K,V> e = prev;
//循環鏈表,通過key,進行hash值和equals判斷
while (e != null) {
Entry<K,V> next = e.next;
if (h == e.hash && eq(k, e.get())) {
modCount++;
size--;
//找到之後,將鏈表後節點向前移動
if (prev == e)
tab[i] = next;
else
prev.next = next;
return e.value;
}
prev = e;
e = next;
}
return null;
}
同樣的,remove 方法在判斷對象之前,也調用了getTable()函數,同時,也調用了expungeStaleEntries()函數,所以,可能通過 key 獲取元素的時候,可能被垃圾回收器回收,得到空值。
四、總結
WeakHashMap 跟普通的 HashMap 不同,在存儲數據時,key被設置為弱引用類型,而弱引用類型在 java 中,可能隨時被 jvm 的 gc 回收,所以再次通過獲取對象時,可能得到空值,而value是在訪問數組內容的時候,進行清除。
可能很多人覺得這樣做很奇葩,其實不然,WeekHashMap 的這個特點特別適用於需要緩存的場景。
在緩存場景下,由於系統內存是有限的,不能緩存所有對象,可以使用 WeekHashMap 進行緩存對象,即使緩存丟失,也可以通過重新計算得到,不會造成系統錯誤。
五、參考
1、JDK1.7&JDK1.8 源碼
2、
3、
4、
作者:炸雞可樂
出處:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※高價收購3C產品,價格不怕你比較
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※3c收購,鏡頭 收購有可能以全新價回收嗎?
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!