環境資訊中心綜合外電;姜唯 編譯;林大利 審校
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!
北部有線電視-提供穩定的寬頻光纖上網、高畫質HD數位頻道、第四台電視、數位電視,現在申辦免費體驗3個月"HD99高畫質套餐"
摘錄自2020年8月4日中央社報導
美國農業部(USDA)動植物健康檢查局副局長艾爾西(Osama El-Lissy)表示,截至7月29日止,已鑑定出芥菜、高麗菜、牽牛花、薄荷、鼠尾草、迷迭香、薰衣草等植物種子,另有木棉花、玫瑰種子。目前鑑定出的品種雖屬無害,但植物專家警告,外來種子有可能損害農作物。
美國哥倫比亞廣播公司新聞網(CBS News)報導,全美50州都有民眾通報收到可疑種子包裹。美國農業部已提醒民眾收到後千萬不要栽種,應立刻向當地的農政單位通報。德州農業廳長米勒(Sid Miller)呼籲民眾保持警覺,「那可能是細菌,也可能是病毒或某個外來種植物」。
維吉尼亞州的農業官員警告:「外來物種會造成環境浩劫,取代或破壞原生植物及昆蟲,嚴重損害農作物。降低外來物種入侵並大量繁殖的風險並減少相關管控成本,最有效的方法就是採取措施、預防入侵物種的引入。」
愛荷華州農業暨土地管理廳的種子檢驗官員普魯伊斯納(Robin Pruisner)表示,有通報指出種子上可能含有殺蟲或除黴劑,對農作物危害甚大。
生物多樣性
國際新聞
美國
種子
外來物種
入侵植物
外來種植物
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
支持點光源和平行光,是一種簡單光照模型,它將光照分解成了三個部分,分別為
如圖所示,是一個簡單的幾何模型。
當光源來自一個方向時,漫反射均勻地向各個方向傳播,與視點無關,是由物體表面粗糙不平引起的,漫反射的空間分佈是均勻的,也就是說不論從哪個方向看去,同一個點的漫反射光強都是一樣的。物體上的點\(P\),法向量為\(N\),入射光強度為\(I_p\),\(L\)為\(P\)指向光源的方向。如果所有所有的向量都是單位向量,那麼有
\[I_d = I_pK_d\cdot(L\cdot N) \]
其中\(K_d=(K_{dr},K_{dg},K_{db})\)這三個分量分別是RGB三原色的漫反射係數,可以反應物體的顏色。同樣的\(I_p=(I_r,I_g,I_b)\)可以通過分量來設置光源的顏色。
對於理想鏡面,反射光集中在一個方向,並遵守反射定律。對於一般的光滑表面,反射光則集中在一個範圍內,且反射定律決定的方向光強最大。所以從不同位置觀察到的鏡面反射光強不同。鏡面反射光可表示為
\[I_s = I_pK_s(R\cdot V)^{n} \]
\(R \cdot V\)計算的是反射方向和視線方向的夾角,夾角越小,強度越大。\(n\)是反射指數,反應了物體的表面的光滑程度,一般1-2000。\(n\)越大約光滑,因為n越大,例如2000,那麼當夾角很小時,例如很接近1,如0.9,但是經過2000乘方,就變得很小了,這意味着只有無限接近反射方向,才能看到高光,其他方向不行,這就表示物體很光滑。反過來,\(n\)很小那麼移動一點角度,也能看到衰弱的高光,所以光斑會比較明顯。
在鏡面反射模型中,最終要的是計算R的方向,\(R\)可以通過入射方向和法線方向計算出來
因為這裏的向量都是單位向量,只有方向不一致
\[\begin{aligned} ||L||\cos\theta &= ||M||=\cos\theta\\ &M和N的方向一致\\ R &= -L+2M \\ &=2N\cos\theta-L\\ &=2N\cdot(N\cdot L)-L \end{aligned} \]
高光區域只反映光源的顏色,漫反射才能設定物體的顏色。
光源間接對物體施加的明暗影響,在物體和環境之間多次反射。在簡單光照模型中進行了簡化,通常用一個常數來模擬環境光
\[I = I_aK_a \]
\(I_a\)是環境光強,\(K_a\)為物體對環境光的反射係數。
\[I = I_aK_a +I_pK_d\cdot(L\cdot N)+I_pK_s(R\cdot V)^{n} \]
Phong模型是上述三種因素的疊加,其中\(R\)的計算比較費時,需要對每一點計算一次\(R\)的值。
由於Phong模型計算較為耗時,後來提出了一種對Phong模型的修改,Blinn-Phong模型。
假設:
所以Blinn-Phong模型的可以表示成:
\[I = I_aK_a +I_pK_d\cdot(L\cdot N)+I_pK_s(H\cdot N)^{n} \]
(圖片中應該採用了明暗處理,不僅是光照模型)
如今的物體大多數用多邊形表示,一個多邊形的法線方向一致,因此一個多邊形內部的像素相同,而在鄰接出可能會有突變,感覺不連續。為了讓過度平滑,基本思想是:對多邊形的頂點計算合適的光強度,在內部進行均勻插值。其中有兩種主要的做法:
基本算法
計算速度比簡單光照模型有了很大的提高,解決了顏色突變問題,但是鏡面反射效果不理想。
和Gouraud方法基本類似,只不過是對法向量插值。多邊形頂點的法向量用相鄰多邊形的法向量的平均值。而內部每個點都要計算法向量,用頂點的法向量插值得到。
這種做法效果好,可以產生正確的高光,但是計算量很大。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※想知道最厲害的網頁設計公司"嚨底家"!
※別再煩惱如何寫文案,掌握八大原則!
※產品缺大量曝光嗎?你需要的是一流包裝設計!
本次做後台管理系統,採用的是 AntD 框架。涉及到圖片的上傳,用的是AntD的 upload 組件。
我在上一篇文章《前端AntD框架的upload組件上傳圖片時遇到的一些坑》中講到:AntD 的 upload 組件有很多坑,引起了很多人的關注。折騰過的人,自然明白其中的苦楚。
今天這篇文章,我們繼續來研究 AntD 的 upload 組件的另一個坑。
備註:本文寫於2020-06-11,使用的 antd 版本是 3.13.6。
因為需要上傳多張圖片,所以採用的是照片牆的形式。上傳成功后的界面如下:
(1)上傳中:
(2)上傳成功:
(3)圖片預覽:
首先,你需要讓後台同學提供好圖片上傳的接口。上一篇文章中,我們是把接口調用直接寫在了 <Upload> 標籤的 action 屬性當中。但如果你在調接口的時候,動作很複雜(比如根據業務要求,需要連續調兩個接口才能上傳圖片,或者在調接口時還要做其他的事情),這個 action 方法就無法滿足需求了。那該怎麼做呢?
好在 AntD 的 upload 組件給我們提供了 customRequest這個方法:
關於customRequest 這個方法, AntD 官方並沒有給出示例,他們只是在 GitHub 上給出了這樣一個簡短的介紹:
但這個方法怎麼用呢?用的時候,會遇到什麼問題呢?AntD 官方沒有說。我在網上搜了半天,也沒看到比較完整的、切實可行的 Demo。我天朝地大物博,網絡資料浩如煙海,AntD 可是口口聲聲被人們號稱是天朝最好用的管理後台的樣式框架。可如今,卻面臨這樣的局面。我看着你們,滿懷羡慕。
既然如此,那我就自己研究吧。折騰了一天,總算是把 customRequest 的坑踩得差不多了。
啥也不說了,直接上代碼。
採用 AntD框架的 upload 組件的 customRequest 方法,自定義上傳行為。核心代碼如下:
import React, { PureComponent } from 'react';
import { Button, Card, Form, message, Upload, Icon, Modal, Row, Col } from 'antd';
import { connect } from 'dva';
import { queryMyData, submitData } from '../api';
import { uploadImage } from '../../utils/wq.img.upload';
import styles from '../../utils/form.less';
const FormItem = Form.Item;
@Form.create()
export default class PicturesWall extends PureComponent {
constructor(props) {
super(props);
const { id } = this.props.match.params;
this.state = {
id,
img: undefined, // 從接口拿到的圖片字段
imgList: [], // 展示在 antd圖片組件上的數據
previewVisible: false,
previewImage: '',
};
}
componentDidMount() {
const { id } = this.state;
id && this.queryData();
}
// 調接口,查詢已有的數據
queryData() {
const { id } = this.state;
queryMyData({
id,
})
.then(({ ret, data }) => {
if (ret == 0 && data && data.list && data.list.length) {
const item = data.list[0];
const img = data.img;
const imgList = item.img
? [
{
uid: '1', // 注意,這個uid一定不能少,否則展示失敗
name: 'hehe.png',
status: 'done',
url: img,
},
]
: [];
this.setState({
img,
imgList,
});
} else {
return Promise.reject();
}
})
.catch(() => {
message.error('查詢出錯,請重試');
});
}
handleCancel = () => this.setState({ previewVisible: false });
// 方法:圖片預覽
handlePreview = (file) => {
console.log('smyhvae handlePreview:' + JSON.stringify(file));
this.setState({
previewImage: file.url || file.thumbUrl,
previewVisible: true,
});
};
// 參考鏈接:https://www.jianshu.com/p/f356f050b3c9
handleBeforeUpload = (file) => {
console.log('smyhvae handleBeforeUpload file:' + JSON.stringify(file));
console.log('smyhvae handleBeforeUpload file.file:' + JSON.stringify(file.file));
console.log('smyhvae handleBeforeUpload file type:' + JSON.stringify(file.type));
//限製圖片 格式、size、分辨率
const isJPG = file.type === 'image/jpeg';
const isJPEG = file.type === 'image/jpeg';
const isGIF = file.type === 'image/gif';
const isPNG = file.type === 'image/png';
const isLt2M = file.size / 1024 / 1024 < 1;
if (!(isJPG || isJPEG || isPNG)) {
Modal.error({
title: '只能上傳JPG、JPEG、PNG格式的圖片~',
});
} else if (!isLt2M) {
Modal.error({
title: '圖片超過1M限制,不允許上傳~',
});
}
return (isJPG || isJPEG || isPNG) && isLt2M;
};
// checkImageWH 返回一個promise 檢測通過返回resolve 失敗返回reject阻止圖片上傳
checkImageWH(file) {
return new Promise(function (resolve, reject) {
let filereader = new FileReader();
filereader.onload = (e) => {
let src = e.target.result;
const image = new Image();
image.onload = function () {
// 獲取圖片的寬高
file.width = this.width;
file.height = this.height;
resolve();
};
image.onerror = reject;
image.src = src;
};
filereader.readAsDataURL(file);
});
}
// 圖片上傳
doImgUpload = (options) => {
const { onSuccess, onError, file, onProgress } = options;
// start:進度條相關
// 偽裝成 handleChange裏面的圖片上傳狀態
const imgItem = {
uid: '1', // 注意,這個uid一定不能少,否則上傳失敗
name: 'hehe.png',
status: 'uploading',
url: '',
percent: 99, // 注意不要寫100。100表示上傳完成
};
this.setState({
imgList: [imgItem],
}); // 更新 imgList
// end:進度條相關
const reader = new FileReader();
reader.readAsDataURL(file); // 讀取圖片文件
reader.onload = (file) => {
const params = {
myBase64: file.target.result, // 把 本地圖片的base64編碼傳給後台,調接口,生成圖片的url
};
// 上傳圖片的base64編碼,調接口后,返回 imageId
uploadImage(params)
.then((res) => {
console.log('smyhvae doImgUpload:' + JSON.stringify(res));
console.log('smyhvae 圖片上傳成功:' + res.imageUrl);
const imgItem = {
uid: '1', // 注意,這個uid一定不能少,否則上傳失敗
name: 'hehe.png',
status: 'done',
url: res.imageUrl, // url 是展示在頁面上的絕對鏈接
imgUrl: res.imageUrl, // imgUrl 是存到 db 里的相對鏈接
// response: '{"status": "success"}',
};
this.setState({
imgList: [imgItem],
}); // 更新 imgList
})
.catch((e) => {
console.log('smyhvae 圖片上傳失敗:' + JSON.stringify(e || ''));
message.error('圖片上傳失敗,請重試');
});
};
};
handleChange = ({ file, fileList }) => {
console.log('smyhvae handleChange file:' + JSON.stringify(file));
console.log('smyhvae handleChange fileList:' + JSON.stringify(fileList));
if (file.status == 'removed') {
this.setState({
imgList: [],
});
}
};
submit = (e) => {
e.preventDefault();
this.props.form.validateFields((err, fieldsValue) => {
if (err) {
return;
}
const { id, imgList } = this.state;
const tempImgList = imgList.filter((item) => item.status == 'done'); // 篩選出 status = done 的圖片
const imgArr = [];
tempImgList.forEach((item) => {
imgArr.push(item.imgUrl);
// imgArr.push(item.url);
});
submitData({
id,
img: imgArr[0] || '', // 1、暫時只傳一張圖片給後台。如果傳多張圖片,那麼,upload組件需要進一步完善,比較麻煩,以後有需求再優化。2、如果圖片字段是選填,那就用空字符串兜底
})
.then((res) => {
if (res.ret == 0) {
message.success(`${id ? '修改' : '新增'}成功,自動跳轉中...`);
} else if (res.ret == 201 || res.ret == 202 || res.ret == 203 || res.ret == 6) {
return Promise.reject(res.msg);
} else {
return Promise.reject();
}
})
.catch((e) => {
message.error(e || '提交失敗,請重試');
});
});
};
render() {
const { id, imgList } = this.state;
console.log('smyhvae render imgList:' + JSON.stringify(imgList));
const { getFieldDecorator } = this.props.form;
const formItemLayout = {
labelCol: { span: 3 },
wrapperCol: { span: 10 },
};
const buttonItemLayout = {
wrapperCol: { span: 10, offset: 3 },
};
const uploadButton = (
<div>
<Icon type="plus" />
<div className="ant-upload-text">Upload</div>
</div>
);
return (
<Card title={id ? '修改信息' : '新增信息'}>
<Form onSubmit={this.submit} layout="horizontal">
{/* 新建圖片、編輯圖片 */}
<FormItem label="圖片" {...formItemLayout}>
{getFieldDecorator('img', {
rules: [{ required: false, message: '請上傳圖片' }],
})(
<Upload
action="2"
customRequest={this.doImgUpload}
listType="picture-card"
fileList={imgList}
onPreview={this.handlePreview}
beforeUpload={this.handleBeforeUpload}
onChange={this.handleChange}
>
{imgList.length >= 1 ? null : uploadButton}
</Upload>
)}
</FormItem>
<Row>
<Col span={3} />
<Col span={18} className={styles.graytext}>
注:圖片支持JPG、JPEG、PNG格式,小於1M,最多上傳1張
</Col>
</Row>
<FormItem {...buttonItemLayout}>
<Button type="primary" htmlType="submit">
提交
</Button>
</FormItem>
</Form>
{/* 圖片點開預覽 */}
<Modal visible={this.state.previewVisible} footer={null} onCancel={this.handleCancel}>
<img alt="example" style={{ width: '100%' }} src={this.state.previewImage} />
</Modal>
</Card>
);
}
}
注意file的格式:https://www.lmonkey.com/t/oREQA5XE1
Demo在線演示:
https://stackoverflow.com/questions/58128062/using-customrequest-in-ant-design-file-upload
fileList 格式在線演示:
https://stackoverflow.com/questions/51514757/action-function-is-required-with-antd-upload-control-but-i-dont-need-it
ant design Upload組件的使用總結:https://www.jianshu.com/p/0aa4612af987
antd上傳功能的CustomRequest:https://mlog.club/article/3832743
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※教你寫出一流的銷售文案?
※超省錢租車方案
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※產品缺大量曝光嗎?你需要的是一流包裝設計!
如果你對性能測試感興趣,但是又不熟悉理論知識,可以看下面的系列文章
https://www.cnblogs.com/poloyy/category/1620792.html
我們在學習性能測試之前,需要有個新的認識:性能測試,不再是像功能測試一樣單純的找 Bug,而是去找性能指標
簡單理解:一個接口返回的數據比較多(假設:不使用分頁,把所有數據同時返回)
大數據測試的功能屬於功能測試哦
在性能測試過程中發現一些問題,假設定位到某一段代碼有問題,可以截圖提交 Bug 給開發,但這並不是我們性能測試的最終目的,最終目的是找出性能指標
跑步100米,用時多少?運動員的心跳、步伐頻率是多少?
性能指標值和響應時間是否滿足當前業務場景的最低要求(合格線)
電商系統,下單業務,目前還不知道系統支持多少人同時下單,那麼我們需要找到服務器能正常支持多少人同時下單
以下含義來源高老的解釋,比較“官方”的術語
其實也算是一個簡潔描述的性測試流程了
目前博主是正在學習性能測試的小白一枚,希望通過通俗簡單的術語來學懂性能測試,打造屬於自己的知識體系,歡迎大家進群與我溝通(870155189)
通過增加“用戶數”,就是常說的併發數
天平秤,稱東西的時候,需要逐步加砝碼,最終達到砝碼和物品重量的平衡點,因為它不可能一下子就達到平衡點【好比不可能一下子找到系統能承受的最大負載量】
問:大家什麼時候會覺得工作壓力大?
答:996、007;因為你不會覺得955壓力山大吧
結論:所以在我們日常工作中,長時間工作強度高,才會覺得壓力大;如果你一周就加班一天也說壓力大…(那就別干這一行了)
測試系統的穩定性
工作壓力大,你還能堅持下去(那穩定性肯定好吧),那如果你很快就離職了(那穩定性肯定差,都宕機罷工了)
隔三差五的出現下面的情況
負載測試一般時間比較短,壓力測試時間比較長,持續運行時間短就能正常使用,但持續運行時間長就可能崩掉了,這是什麼原因呢?
壓力測試長時間運行,可能會逐漸增加系統的內存佔用空間,若得不到有效的內存回收,當達到內存最大值時,系統就會崩掉
電商秒殺場景,幾十個商品幾十萬個人同時秒殺搶購
從一袋米中找一個綠豆,和一碗米中找一個綠豆,找的時間肯定是千差萬別的
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?
※網頁設計最專業,超強功能平台可客製化
※產品缺大量曝光嗎?你需要的是一流包裝設計!
獲取流數據的時候,通常需要根據所需把流拆分出其他多個流,根據不同的流再去作相應的處理。
舉個例子:創建一個商品實時流,商品有季節標籤,需要對不同標籤的商品做統計處理,這個時候就需要把商品數據流根據季節標籤分流。
先模擬一個實時的數據流
import lombok.Data;
@Data
public class Product {
public Integer id;
public String seasonType;
}
自定義Source
import common.Product;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import java.util.ArrayList;
import java.util.Random;
public class ProductStremingSource implements SourceFunction<Product> {
private boolean isRunning = true;
@Override
public void run(SourceContext<Product> ctx) throws Exception {
while (isRunning){
// 每一秒鐘產生一條數據
Product product = generateProduct();
ctx.collect(product);
Thread.sleep(1000);
}
}
private Product generateProduct(){
int i = new Random().nextInt(100);
ArrayList<String> list = new ArrayList();
list.add("spring");
list.add("summer");
list.add("autumn");
list.add("winter");
Product product = new Product();
product.setSeasonType(list.get(new Random().nextInt(4)));
product.setId(i);
return product;
}
@Override
public void cancel() {
}
}
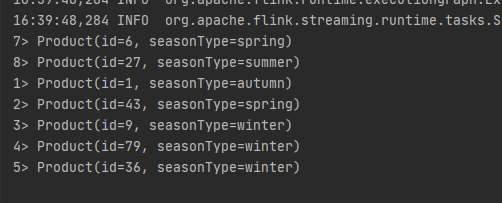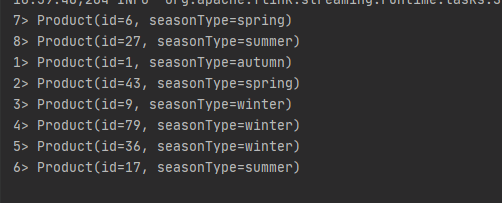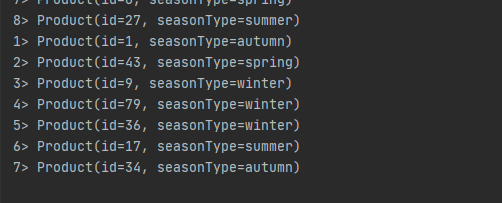
輸出:
使用 filter 算子根據數據的字段進行過濾。
import common.Product;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import source.ProductStremingSource;
public class OutputStremingDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Product> source = env.addSource(new ProductStremingSource());
// 使用Filter分流
SingleOutputStreamOperator<Product> spring = source.filter(product -> "spring".equals(product.getSeasonType()));
SingleOutputStreamOperator<Product> summer = source.filter(product -> "summer".equals(product.getSeasonType()));
SingleOutputStreamOperator<Product> autumn = source.filter(product -> "autumn".equals(product.getSeasonType()));
SingleOutputStreamOperator<Product> winter = source.filter(product -> "winter".equals(product.getSeasonType()));
source.print();
winter.printToErr();
env.execute("output");
}
}
結果輸出(紅色為季節標籤是winter的分流輸出):
重寫OutputSelector內部類的select()方法,根據數據所需要分流的類型反正不同的標籤下,返回SplitStream,通過SplitStream的select()方法去選擇相應的數據流。
只分流一次是沒有問題的,但是不能使用它來做連續的分流。
SplitStream已經標記過時了
public class OutputStremingDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Product> source = env.addSource(new ProductStremingSource());
// 使用Split分流
SplitStream<Product> dataSelect = source.split(new OutputSelector<Product>() {
@Override
public Iterable<String> select(Product product) {
List<String> seasonTypes = new ArrayList<>();
String seasonType = product.getSeasonType();
switch (seasonType){
case "spring":
seasonTypes.add(seasonType);
break;
case "summer":
seasonTypes.add(seasonType);
break;
case "autumn":
seasonTypes.add(seasonType);
break;
case "winter":
seasonTypes.add(seasonType);
break;
default:
break;
}
return seasonTypes;
}
});
DataStream<Product> spring = dataSelect.select("machine");
DataStream<Product> summer = dataSelect.select("docker");
DataStream<Product> autumn = dataSelect.select("application");
DataStream<Product> winter = dataSelect.select("middleware");
source.print();
winter.printToErr();
env.execute("output");
}
}
推薦使用這種方式
首先需要定義一個OutputTag用於標識不同流
可以使用下面的幾種函數處理流發送到分流中:
之後再用getSideOutput(OutputTag)選擇流。
public class OutputStremingDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Product> source = env.addSource(new ProductStremingSource());
// 使用Side Output分流
final OutputTag<Product> spring = new OutputTag<Product>("spring");
final OutputTag<Product> summer = new OutputTag<Product>("summer");
final OutputTag<Product> autumn = new OutputTag<Product>("autumn");
final OutputTag<Product> winter = new OutputTag<Product>("winter");
SingleOutputStreamOperator<Product> sideOutputData = source.process(new ProcessFunction<Product, Product>() {
@Override
public void processElement(Product product, Context ctx, Collector<Product> out) throws Exception {
String seasonType = product.getSeasonType();
switch (seasonType){
case "spring":
ctx.output(spring,product);
break;
case "summer":
ctx.output(summer,product);
break;
case "autumn":
ctx.output(autumn,product);
break;
case "winter":
ctx.output(winter,product);
break;
default:
out.collect(product);
}
}
});
DataStream<Product> springStream = sideOutputData.getSideOutput(spring);
DataStream<Product> summerStream = sideOutputData.getSideOutput(summer);
DataStream<Product> autumnStream = sideOutputData.getSideOutput(autumn);
DataStream<Product> winterStream = sideOutputData.getSideOutput(winter);
// 輸出標籤為:winter 的數據流
winterStream.print();
env.execute("output");
}
}
結果輸出:
更多文章:www.ipooli.com
掃碼關注公眾號《ipoo》
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!
我們福祿網絡致力於為廣大用戶提供智能化充值服務,包括各類通信充值卡(比如移動、聯通、電信的話費及流量充值)、遊戲類充值卡(比如王者榮耀、吃雞類點券、AppleStore充值、Q幣、鬥魚幣等)、生活服務類(比如肯德基、小鹿茶等),網娛類(比如QQ各類鑽等),作為一個服務提供商,商品質量的穩定、持續及充值過程的便捷一直是我們在業內的口碑。
在整個商品流通過程中,如何做好庫存的管理,以充分提高庫存運轉周期和資金使用效率,一直是個難題。基於此,我們提出了智能化的庫存管理服務,根據訂單數據及商品數據,來預測不同商品隨着時間推移的日常消耗情況。
目前成熟的時間序列預測算法很多,但商業領域性能優越的卻不多,經過多種嘗試,給大家推薦2種時間序列算法:facebook開源的Prophet算法和LSTM深度學習算法。
現將個人理解的2種算法特性予以簡要說明:
time,product,cnt
2019-10-01 00,**充值,6
2019-10-01 00,***遊戲,368
2019-10-01 00,***,1
2019-10-01 00,***,11
2019-10-01 00,***遊戲,17
2019-10-01 00
,三網***,39
2019-10-01 00,**網,6
2019-10-01 00,***,2
字段說明:
時間序列一般不進行特徵處理,當然可以根據具體情況進行歸一化處理或是取對數處理等。
目前待選的算法主要有2種:
以上是理論上的調參步驟,但我們在實際情況下在建議使用grid_search(網格尋參)方式,直接簡單效果好。當機器性能不佳時網格調參配合理論調參方法可以加快調參速度。建議初學者使用手動調參方式以理解每個參數對模型效果的影響。
holiday.csv
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from fbprophet import Prophet
data = pd.read_csv('../data/data2.csv', parse_dates=['time'], index_col='time')
def get_product_data(name, rule=None):
product = data[data['product'] == name][['cnt']]
product.plot()
if rule is not None:
product = product.resample(rule).sum()
product.reset_index(inplace=True)
product.columns = ['ds', 'y']
return product
holidays = pd.read_csv('holiday.csv', parse_dates=['ds'])
holidays['lower_window'] = -1
holidays = holidays.append(pd.DataFrame({
'holiday': '雙11',
'ds': pd.to_datetime(['2019-11-11', '2020-11-11']),
'lower_window': -1,
'upper_window': 1,
})).append(pd.DataFrame({
'holiday': '雙12',
'ds': pd.to_datetime(['2019-12-12', '2020-12-12']),
'lower_window': -1,
'upper_window': 1,
})
)
def predict(name, rule='1d', freq='d', periods=1, show=False):
ds = get_product_data(name, rule=rule)
if ds.shape[0] < 7:
return None
m = Prophet(holidays=holidays)
m.fit(ds)
future = m.make_future_dataframe(freq=freq, periods=periods) # 建立數據預測框架,數據粒度為天,預測步長為一年
forecast = m.predict(future)
if show:
m.plot(forecast).show() # 繪製預測效果圖
m.plot_components(forecast).show() # 繪製成分趨勢圖
mse = forecast['yhat'].iloc[ds.shape[0]] - ds['y'].values
mse = np.abs(mse) / (ds['y'].values + 1)
return [name, mse.mean(), mse.max(), mse.min(), np.quantile(mse, 0.9), np.quantile(mse, 0.8), mse[-7:].mean(),
ds['y'].iloc[-7:].mean()]
if __name__ == '__main__':
products = set(data['product'])
p = []
for i in products:
y = predict(i)
if y is not None:
p.append(y)
df = pd.DataFrame(p, columns=['product', 'total_mean', 'total_max', 'total_min', '0.9', '0.8', '7_mean',
'7_real_value_mean'])
df.set_index('product', inplace=True)
product_sum: pd.DataFrame = data.groupby('product').sum()
df = df.join(product_sum)
df.sort_values('cnt', ascending=False, inplace=True)
df.to_csv('result.csv', index=False)
結果如下:由於行數較多這裏只展示前1行
根據結果,對比原生數據,可以得出如下結論:
就算法與產品的匹配性可分為3個類型:
A. 因素分解圖
上圖中主要分為3個部分,分別對應prophet 3大要素,趨勢、節假日或特殊日期、周期性(包括年周期、月周期、week周期、天周期以及用戶自定義的周期)
下面依照上面因素分解圖的順序依次對圖進行說明:
LSTM(長短記憶網絡)主要用於有先後順序的序列類型的數據的深度學習網絡。是RNN的優化版本。一般用於自然語言處理,也可用於時間序列的預測。
簡單來說就是,LSTM一共有三個門,輸入門,遺忘門,輸出門, i 、o、 f 分別為三個門的程度參數, g 與RNN中的概念一致。公式里可以看到LSTM的輸出有兩個,細胞狀態c 和隱狀態 h,c是經輸入、遺忘門的產物,也就是當前cell本身的內容,經過輸出門得到h,就是想輸出什麼內容給下一單元。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
from torch import nn
from sklearn.preprocessing import MinMaxScaler
ts_data = pd.read_csv('../data/data2.csv', parse_dates=['time'], index_col='time')
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
n_vars = 1 if type(data) is list else data.shape[1]
df = pd.DataFrame(data)
cols, names = list(), list()
# input sequence (t-n, ... t-1)
for i in range(n_in, 0, -1):
cols.append(df.shift(i))
names += [('var%d(t-%d)' % (j + 1, i)) for j in range(n_vars)]
# forecast sequence (t, t+1, ... t+n)
for i in range(0, n_out):
cols.append(df.shift(-i))
if i == 0:
names += [('var%d(t)' % (j + 1)) for j in range(n_vars)]
else:
names += [('var%d(t+%d)' % (j + 1, i)) for j in range(n_vars)]
# put it all together
agg = pd.concat(cols, axis=1)
agg.columns = names
# drop rows with NaN values
if dropnan:
agg.dropna(inplace=True)
return agg
def transform_data(feature_cnt=2):
yd = ts_data[ts_data['product'] == '移動話費'][['cnt']]
scaler = MinMaxScaler(feature_range=(0, 1))
yd_scaled = scaler.fit_transform(yd.values)
yd_renamed = series_to_supervised(yd_scaled
, n_in=feature_cnt).values.astype('float32')
n_row = yd_renamed.shape[0]
n_train = int(n_row * 0.7)
train_X, train_y = yd_renamed[:n_train, :-1], yd_renamed[:n_train, -1]
test_X, test_y = yd_renamed[n_train:, :-1], yd_renamed[n_train:, -1]
# 最後,我們需要將數據改變一下形狀,因為 RNN 讀入的數據維度是 (seq, batch, feature),所以要重新改變一下數據的維度,這裏只有一個序列,所以 batch 是 1,而輸入的 feature 就是我們希望依據的幾天,這裏我們定的是兩個天,所以 feature 就是 2.
train_X = train_X.reshape((-1, 1, feature_cnt))
test_X = test_X.reshape((-1, 1, feature_cnt))
print(train_X.shape, train_y.shape, test_X.shape, test_y.shape)
# 轉化成torch 的張量
train_x = torch.from_numpy(train_X)
train_y = torch.from_numpy(train_y)
test_x = torch.from_numpy(test_X)
test_y = torch.from_numpy(test_y)
return scaler, train_x, train_y, test_x, test_y
scaler, train_x, train_y, test_x, test_y = transform_data(24)
# lstm 網絡
class lstm_reg(nn.Module): # 括號中的是python的類繼承語法,父類是nn.Module類 不是參數的意思
def __init__(self, input_size, hidden_size, output_size=1, num_layers=2): # 構造函數
# inpu_size 是輸入的樣本的特徵維度, hidden_size 是LSTM層的神經元個數,
# output_size是輸出的特徵維度
super(lstm_reg, self).__init__() # super用於多層繼承使用,必須要有的操作
self.rnn = nn.LSTM(input_size, hidden_size, num_layers) # 兩層LSTM網絡,
self.reg = nn.Linear(hidden_size, output_size) # 把上一層總共hidden_size個的神經元的輸出向量作為輸入向量,然後回歸到output_size維度的輸出向量中
def forward(self, x): # x是輸入的數據
x, _ = self.rnn(x) # 單個下劃線表示不在意的變量,這裡是LSTM網絡輸出的兩個隱藏層狀態
s, b, h = x.shape
x = x.view(s * b, h)
x = self.reg(x)
x = x.view(s, b, -1) # 使用-1表示第三個維度自動根據原來的shape 和已經定了的s,b來確定
return x
def train(feature_cnt, hidden_size, round, save_path='model.pkl'):
# 我使用了GPU加速,如果不用的話需要把.cuda()給註釋掉
net = lstm_reg(feature_cnt, hidden_size)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(net.parameters(), lr=1e-2)
for e in range(round):
# 新版本中可以不使用Variable了
# var_x = Variable(train_x).cuda()
# var_y = Variable(train_y).cuda()
# 將tensor放在GPU上面進行運算
var_x = train_x
var_y = train_y
out = net(var_x)
loss = criterion(out, var_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (e + 1) % 100 == 0:
print('Epoch: {}, Loss:{:.5f}'.format(e + 1, loss.item()))
# 存儲訓練好的模型參數
torch.save(net.state_dict(), save_path)
return net
if __name__ == '__main__':
net = train(24, 8, 5000)
# criterion = nn.MSELoss()
# optimizer = torch.optim.Adam(net.parameters(), lr=1e-2)
pred_test = net(test_x) # 測試集的預測結果
pred_test = pred_test.view(-1).data.numpy() # 先轉移到cpu上才能轉換為numpy
# 乘以原來歸一化的刻度放縮回到原來的值域
origin_test_Y = scaler.inverse_transform(test_y.reshape((-1,1)))
origin_pred_test = scaler.inverse_transform(pred_test.reshape((-1,1)))
# 畫圖
plt.plot(origin_pred_test, 'r', label='prediction')
plt.plot(origin_test_Y, 'b', label='real')
plt.legend(loc='best')
plt.show()
# 計算MSE
# loss = criterion(out, var_y)?
true_data = origin_test_Y
true_data = np.array(true_data)
true_data = np.squeeze(true_data) # 從二維變成一維
MSE = true_data - origin_pred_test
MSE = MSE * MSE
MSE_loss = sum(MSE) / len(MSE)
print(MSE_loss)
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
摘錄自2020年8月12日中央社報導
儘管巴西政府數據顯示,亞馬遜雨林的火災件數呈現增加趨勢,但總統波索納洛(Jair Bolsonaro)卻宣稱大火肆虐亞馬遜雨林一事僅是「謊言」。
波索納洛昨天與數個南美洲國家的領袖進行視訊會議。極右派的波索納洛在會議中表示:「熱帶雨林不會著火。所以,亞馬遜雨林失火的故事是個謊言,我們應以真實數據因應。」
然而,巴西國家太空署(INPE)的衛星影像顯示,今年7月巴西亞馬遜森林的火災件數,較去年7月增加28%,達到6803起。
法新社報導,專家認為亞馬遜森林的火災並非自然生成,而是人類為了農耕及放牧,非法放火燒林開闢土地所造成。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?
※網頁設計最專業,超強功能平台可客製化
※產品缺大量曝光嗎?你需要的是一流包裝設計!
![[computer graphics]簡單光照模型(Phong和Blinn-Phong)和明暗處理](https://www.3chy5.com/wp-content/uploads/2020/12/667aeef5cf8ec27c092a3b49b9f6324d.jpg)