作者:HelloGitHub-追夢人物
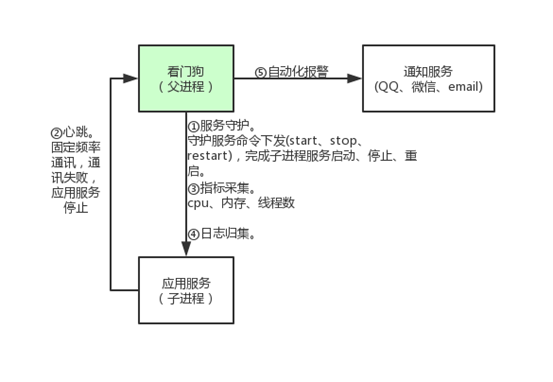
此前我們一直在操作博客文章(Post)資源,並藉此介紹了序列化器(Serializer)、視圖集(Viewset)、路由器(Router)等 django-rest-framework 提供的便利工具,藉助這些工具,就可以非常快速地完成 RESTful API 的開發。
評論(Comment)是另一種資源,我們同樣藉助以上工具來完成對評論資源的接口開發。
首先是設計評論 API 的 URL,根據 RESTful API 的設計規範,評論資源的 URL 設計為:/comments/
對評論資源的操作有獲取某篇文章下的評論列表和創建評論兩種操作,因此相應的 HTTP 請求和動作(action)對應如下:
| HTTP請求 | Action | URL |
|---|---|---|
| GET | list_comments | /posts/:id/comments/ |
| POST | create | /comments/ |
文章評論列表 API 使用自定義的 action,放在 /post/ 接口的視圖集下;發表評論接口使用標準的 create action,需要定義單獨的視圖集。
然後需要一個序列化器,用於評論資源的序列化(獲取評論時),反序列化(創建評論時)。有了編寫文章序列化器的基礎,評論序列化器就是依葫蘆畫瓢的事。
comments/serializers.py
from rest_framework import serializers
from .models import Comment
class CommentSerializer(serializers.ModelSerializer):
class Meta:
model = Comment
fields = [
"name",
"email",
"url",
"text",
"created_time",
"post",
]
read_only_fields = [
"created_time",
]
extra_kwargs = {"post": {"write_only": True}}
注意這裏我們在 Meta 中增加了 read_only_fields、extra_kwargs 的聲明。
read_only_fields 用於指定只讀字段的列表,由於 created_time 是自動生成的,用於記錄評論發布時間,因此聲明為只讀的,不允許通過接口進行修改。
extra_kwargs 指定傳入每個序列化字段的額外參數,這裏給 post 序列化字段傳入了 write_only 關鍵字參數,這樣就將 post 聲明為只寫的字段,這樣 post 字段的值僅在創建評論時需要。而在返回的資源中,post 字段就不會出現。
首先來實現創建評論的接口,先為評論創建一個視圖集:
comments/views.py
from rest_framework import mixins, viewsets
from .models import Comment
from .serializers import CommentSerializer
class CommentViewSet(mixins.CreateModelMixin, viewsets.GenericViewSet):
serializer_class = CommentSerializer
def get_queryset(self):
return Comment.objects.all()
視圖集非常的簡單,混入 CreateModelMixin 后,視圖集就實現了標準的 create action。其實 create action 方法的實現也非常簡單,我們來學習一下 CreateModelMixin 的源碼實現。
class CreateModelMixin:
"""
Create a model instance.
"""
def create(self, request, *args, **kwargs):
serializer = self.get_serializer(data=request.data)
serializer.is_valid(raise_exception=True)
self.perform_create(serializer)
headers = self.get_success_headers(serializer.data)
return Response(serializer.data, status=status.HTTP_201_CREATED, headers=headers)
def perform_create(self, serializer):
serializer.save()
def get_success_headers(self, data):
try:
return {'Location': str(data[api_settings.URL_FIELD_NAME])}
except (TypeError, KeyError):
return {}
核心邏輯在 create 方法:首先取到綁定了用戶提交數據的序列化器,用於反序列化。接着調用 is_valid 方法校驗數據合法性,如果不合法,會直接拋出異常(raise_exception=True)。否則就執行序列化的 save 邏輯將評論數據存入數據庫,最後返迴響應。
接着在 router 里註冊 CommentViewSet 視圖集:
router.register(r"comments", comments.views.CommentViewSet, basename="comment")
進入 API 交互後台,可以看到首頁列出了 comments 接口的 URL,點擊進入 /comments/ 后可以看到一個評論表單,在這裏可以提交評論數據與創建評論的接口進行交互。
接下來實現獲取評論列表的接口。通常情況下,我們都是只獲取某篇博客文章下的評論列表,因此我們的 API 設計成了 /posts/:id/comments/。這個接口具有很強的語義,非常符合 RESTful API 的設計規範。
由於接口位於 /posts/ 空間下,因此我們在 PostViewSet 添加自定義 action 來實現,先來看代碼:
blog/views.py
class PostViewSet(
mixins.ListModelMixin, mixins.RetrieveModelMixin, viewsets.GenericViewSet
):
# ...
@action(
methods=["GET"],
detail=True,
url_path="comments",
url_name="comment",
pagination_class=LimitOffsetPagination,
serializer_class=CommentSerializer,
)
def list_comments(self, request, *args, **kwargs):
# 根據 URL 傳入的參數值(文章 id)獲取到博客文章記錄
post = self.get_object()
# 獲取文章下關聯的全部評論
queryset = post.comment_set.all().order_by("-created_time")
# 對評論列表進行分頁,根據 URL 傳入的參數獲取指定頁的評論
page = self.paginate_queryset(queryset)
# 序列化評論
serializer = self.get_serializer(page, many=True)
# 返回分頁后的評論列表
return self.get_paginated_response(serializer.data)
action 裝飾器我們在上一篇教程中進行了詳細說明,這裏我們再一次接觸到 action 裝飾器更為深入的用法,可以看到我們除了設置 methods、detail、url_path 這些參數外,還通過設置 pagination_class、serializer_class 來覆蓋原本在 PostViewSet 中設置的這些類屬性的值(例如對於分頁,PostViewSet 默認為我們之前設置的 PageNumberPagination,而這裏我們替換為 LimitOffsetPagination)。
list_comments 方法邏輯非常清晰,註釋中給出了詳細的說明。另外還可以看到我們調用了一些輔助方法,例如 paginate_queryset 對查詢集進行分頁;get_paginated_response 返回分頁后的 HTTP 響應,這些方法其實都是 GenericViewSet 提供的通用輔助方法,源碼也並不複雜,如果不用這些方法,我們自己也可以輕鬆實現,但既然 django-rest-framework 已經為我們寫好了,直接復用就行,具體的實現請大家通過閱讀源碼進行學習。
現在進入 API 交互後台,進入某篇文章的詳細接口,例如訪問 /api/posts/5/,Extra Actions 下拉框中可以看到 List comments 的選項:
點擊 List comments 即可進入這篇文章下的評論列表接口,獲取這篇文章的評論列表資源了:
關注公眾號加入交流群
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※想知道最厲害的網頁設計公司“嚨底家”!
※別再煩惱如何寫文案,掌握八大原則!
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※聚甘新