在傳統桌面程序中,對圖標的使用大多是直接嵌入JPG或者PNG的圖片。在祖傳的1366×768分辨率下,並沒有什麼問題。相對於手機硬件的突飛猛進,也側面反映了PC行業的落寞和桌面程序開發的不思進取。用360衛士的群眾並不能倒推PC行業的升級。反倒是水果公司雙高的利潤和口碑讓人很是眼饞。加之某軟跳出來教豬隊友做硬件。現在倒是有些起色,1080p的屏幕已是標配,4k也算常見。那麼傳統桌面程序在升級過程中,就會遇到今天要討論的,如何解決高分辨率下圖標模糊的問題。
一種解決方案是按最高的分辨率提供圖片。這種適合較大的圖片,比如背景啥的。另一種就是今天要討論的,針對當前流行的、扁平化圖標的解決方案。
從本篇的標題可以看出,我們希望應用SVG矢量圖來適應各種分辨率的情況。以WPF程序為例,首先要面對的問題是,WPF並不支持像嵌入JPG/PNG圖標這樣,直接使用SVG圖標。大動干戈的引用第三方library通過自定義類型來支持SVG並不是本文的目的。這裏我們要介紹如何通過字體文件,進而在WPF或UWP中使用SVG圖標的方式。
雖然WPF不支持直接使用SVG文件,但是Windows是支持矢量字體的。而我們的目的就是要將圖標以字體的形式在WPF程序中显示。具體使用的字體TrueType,則是由微軟和蘋果共同開發的字體類型標準,該字體文件的擴展名是.ttf。
接下來我們依然是通過Sample工程來說明。首先給出GitHub的地址:
首先我們打開WpfAppWithPNGs工程,圖標的使用代碼如下:
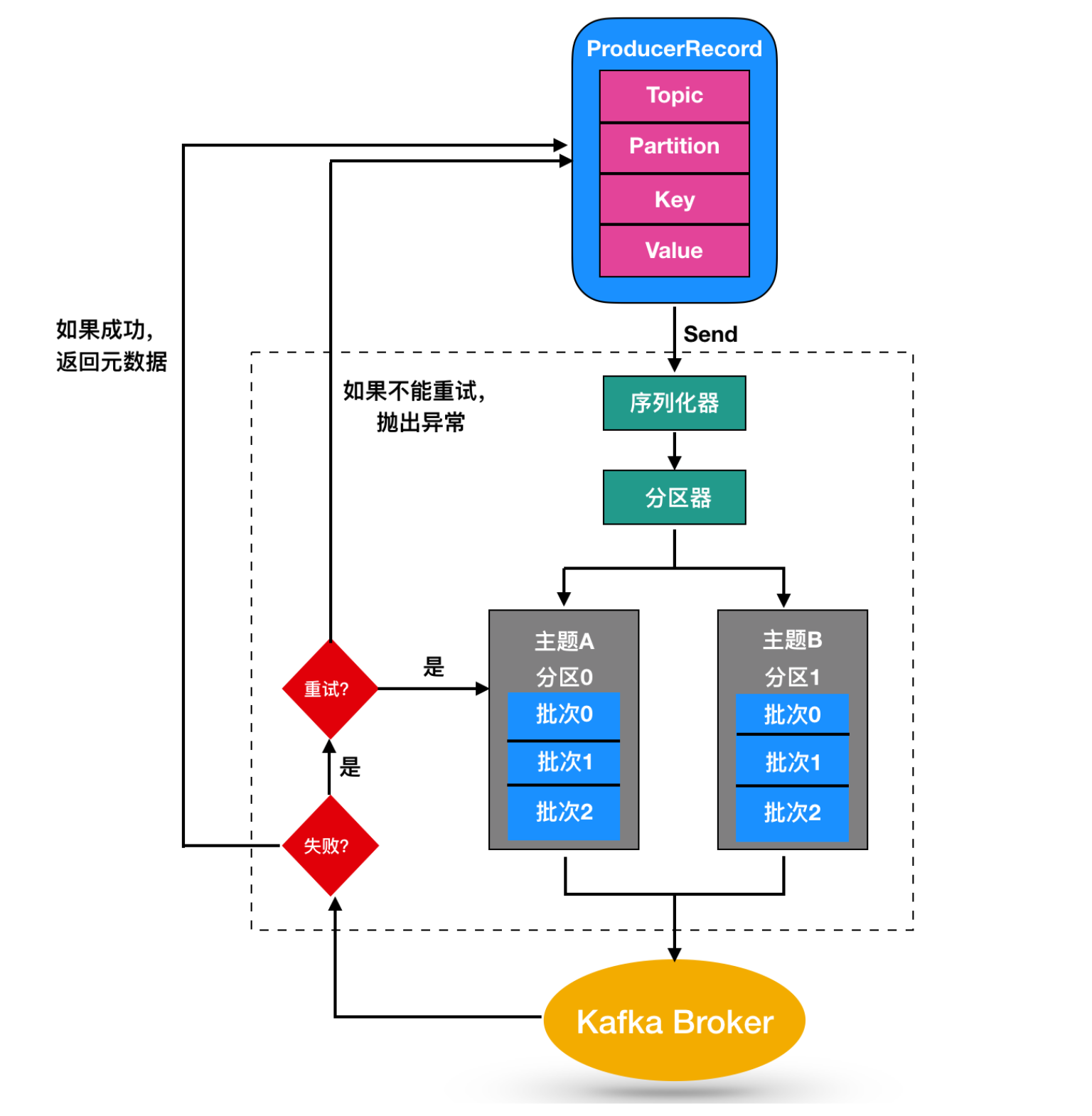
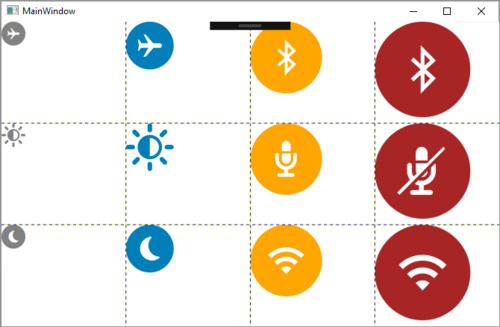
<Image Grid.Row="0" Grid.Column="0" Width="32" Height="32" Source="Resources/Airplane_Off.png" ></Image> <Image Grid.Row="0" Grid.Column="1" Width="64" Height="64" Source="Resources/Airplane_On.png" ></Image> <Image Grid.Row="0" Grid.Column="2" Width="96" Height="96" Source="Resources/Bluetooth_Off.png" ></Image> <Image Grid.Row="0" Grid.Column="3" Width="128" Height="128" Source="Resources/Bluetooth_On.png" ></Image>
這裏主要有兩個問題,因為我們默認提供的是32×32的圖標,因此除了第一列Width和Height設置為32的圖標,其他的圖標都存在模糊的問題。第二個問題是針對圖標的每一種顏色,都需要對應提供不同的圖標文件(圖中的例子需要有灰色和藍色兩份文件)。相對的SVG圖標僅僅需要一份文件。即可在程序中動態設定不同的顏色了。
這裏先給出最終WPF項目中,對SVG圖標的引用的代碼,然後我們再進行詳細解釋。對應的工程名為WpfAppWithFontIcons。
<TextBlock Grid.Row="0" Grid.Column="0" Text="{x:Static local:FontIcons.airplane_mode_circ}" Foreground="Gray" FontSize="32" ></TextBlock> <TextBlock Grid.Row="0" Grid.Column="1" Text="{x:Static local:FontIcons.airplane_mode_circ}" Foreground="{StaticResource dellBlue}" FontSize="64" ></TextBlock> <TextBlock Grid.Row="0" Grid.Column="2" Text="{x:Static local:FontIcons.bluetooth_inactive}" Foreground="Orange" FontSize="96" ></TextBlock> <TextBlock Grid.Row="0" Grid.Column="3" Text="{x:Static local:FontIcons.bluetooth_inactive}" Foreground="Brown" FontSize="128" ></TextBlock>
代碼最大的不同應該是由<Image/>標籤更改為<TextBlock/>標籤,這是因為我們是通過ttf字體文件,曲線救國的方式來使用SVG圖標。
具體的步驟如下:
準備SVG圖標文件,將這些文件打包成一整個ttf字體文件。打包的方式有很多種,通常我使用的是IcoMoon的免費解決方案。地址如下:
通過這個網站選擇SVG圖標文件上傳,打包生成一個zip文件。解壓後文件夾結構如下圖:
ttf文件在fonts文件夾中,實際使用時,需要作為資源文件,添加到WPF工程中。點擊圖中的demo.html會打開一個本地網頁,可用於查找ttf文件中包含的SVG圖標,以及對應的unicode。實際我們是通過對unicode的引用來显示SVG圖標的。
完整的project結構如下圖,Fonts文件夾是手動添加用來放置ttf文件。ttf文件名字都是根據項目需要來取,並不固定。
ttf字體文件需要以<FontFamily/>的形式添加到項目的<Resources/>節點中。然後再通過<Style/>指定給<TextBlock/>。當然不在<Resources/>節點定義Style,而是在每個<TextBlock/>中指定FontFamily屬性也是可以的。有關XAML的語法細節,回字的四種寫法什麼的,這裏略過不提。
<Window.Resources> <FontFamily x:Key="Fonticon">/Fonts/rcc-fonticon-ribbon-v2.ttf#rcc-fonticon-ribbon-v2</FontFamily> <Style TargetType="TextBlock"> <Setter Property="FontFamily" Value="{StaticResource Fonticon}" ></Setter> </Style> <SolidColorBrush x:Key="dellBlue">#007DB8</SolidColorBrush> </Window.Resources>
這裏說明一下“/Fonts/rcc-fonticon-ribbon-v2.ttf#rcc-fonticon-ribbon-v2”值的定義,#前面的是文件路徑,#後面的是font name,查看的方法是雙擊ttf文件,參考下圖。
在定義好FontFamily之後,我們並不推薦直接將unicode寫到XAML或.cs文件中。因為在XAML中,你需要如下編寫:
<TextBlock Grid.Row="0" Grid.Column="0" Text="" Foreground="Gray" FontSize="32" ></TextBlock>
而在C#代碼中,又需要以下面這種格式:
textBlockAirplane.Text = "\ue900";
兩種不統一的格式會在將來修改時帶來極大的困難,特別是圖標被多處引用時,全局的查找替換根本就是噩夢。此外,毫無意義的unicode值的可讀性根本等於0。正常人類無法將””,”\ue900″和Airplane的圖標聯繫起來。
我推薦的做法是生成一個FontIcons Class,以string類型屬性的形式暴露出來。這樣可以獲得IDE智能語法提示的支持,更新時也僅需修改這個Class,Find All Reference更是方便無比。同時無論在XAML文件,還是C#代碼中,我們看到的都是統一的“FontIcons.airplane_mode_circ”。
public static class FontIcons { public static string airplane_mode_circ { get; } = "\ue900"; public static string bluetooth_inactive { get; } = "\ue901"; public static string brightness { get; } = "\ue902"; public static string brightness_inactive { get; } = "\ue903"; public static string browse_inactive { get; } = "\ue904"; public static string camera { get; } = "\ue905"; }
那麼我們是不是需要手工來編寫FontIcons Class呢?大哥我們是能把午飯(我不愛喝咖啡)轉換成Code的生物啊!當然是寫個小工具來自動生成了。在Sample庫中,參考IcoMoonReader工程,只需將IcoMoon生成的.svg文件(icomoon.zip解壓后的fonts文件夾里)丟在IconMoonReader.exe同級目錄,即可生成相應代碼。
其實只有一個方法啦,使用時需要注意具體的文件名是否正確。
using (var stream = new FileStream("rcc-fonticon-ribbon-v2.svg", FileMode.Open)) { using (var reader = new StreamReader(stream)) { var pattern = "unicode(\\S)*\\sglyph-name(\\S)*\""; var input = reader.ReadToEnd(); foreach (Match match in Regex.Matches(input, pattern)) { pattern = "\"\\S*\""; var list = new List<string>(); foreach (var result in Regex.Matches(match.Value, pattern)) { list.Insert(0, result.ToString()); } var name = list[0].Replace("\"", "").Replace("-","_"); var code = list[1].Replace("&#x", "\\u").Replace(";", ""); Console.WriteLine($"public static string {name} {{ get; }} = {code};"); } } }
把生成的C#字符串定義貼到具體工程的FontIcons Class(名字隨意)。
這樣一個優秀的解決方案如果僅支持WPF,那又談何遷移到MS Store呢?實際上這套機制放到UWP工程中也是可以的。雖然UWP可以通過SvgImageSource屬性原生支持SVG了,但我們的這套方案在圖標的應用方面毫不遜色,甚至可以說更為方便。具體的例子可以參考AppWithFontIcon工程。在這個UWP的工程中,除了放ttf文件的位置我換到了現成的Assets文件夾,幾乎沒有改變。
<TextBlock Grid.Row="0" Grid.Column="0" Text="{x:Bind local:FontIcons.airplane_mode_circ}" Foreground="Gray" FontSize="32" ></TextBlock> <TextBlock Grid.Row="0" Grid.Column="1" Text="{x:Bind local:FontIcons.airplane_mode_circ}" Foreground="{StaticResource dellBlue}" FontSize="64" ></TextBlock> <TextBlock Grid.Row="0" Grid.Column="2" Text="{x:Bind local:FontIcons.bluetooth_inactive}" Foreground="Orange" FontSize="96" ></TextBlock> <TextBlock Grid.Row="0" Grid.Column="3" Text="{x:Bind local:FontIcons.bluetooth_inactive}" Foreground="Brown" FontSize="{x:Bind DynamicFontSize(),Mode=OneWay,FallbackValue=128}" ></TextBlock>
因為UWP沒有了x:static關鍵字,所以我換成了x:Bind。換成x:Bind之後甚至可以動態的響應值的變化。比如我在這裏把FontSize做了一個x:bind到DynamicFontSize()方法,讓字體隨着界面改變,動態的變大變小。雖然並沒有什麼卵用……但是Demo的時候可以增加點噱頭……
本篇到此結束,照例貼上Github地址:
感謝耐着性子看到這裏的同學!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※想知道網站建置、網站改版該如何進行嗎?將由專業工程師為您規劃客製化網頁設計及後台網頁設計
※不管是台北網頁設計公司、台中網頁設計公司,全省皆有專員為您服務
※Google地圖已可更新顯示潭子電動車充電站設置地點!!