環境資訊中心綜合外電;姜唯 編譯;林大利 審校
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※教你寫出一流的銷售文案?
北部有線電視-提供穩定的寬頻光纖上網、高畫質HD數位頻道、第四台電視、數位電視,現在申辦免費體驗3個月"HD99高畫質套餐"
RepeatForever:指定觸發器將無限期重複。
WithRepeatCount:指定重複次數
var trigger = TriggerBuilder.Create().WithSimpleSchedule(s=>s.WithIntervalInSeconds(1).RepeatForever()).Build();
var trigger = TriggerBuilder.Create().WithSimpleSchedule(s=>s.WithIntervalInSeconds(1) .WithRepeatCount(10)).Build();
注:底層實現是repeatCount+1,也就是總共執行repeatCount+1次
/// <summary> /// Specify a the number of time the trigger will repeat - total number of /// firings will be this number + 1. /// </summary> /// <remarks> /// </remarks> /// <param name="repeatCount">the number of seconds at which the trigger should repeat.</param> /// <returns>the updated SimpleScheduleBuilder</returns> /// <seealso cref="ISimpleTrigger.RepeatCount" /> /// <seealso cref="RepeatForever" /> public SimpleScheduleBuilder WithRepeatCount(int repeatCount) { this.repeatCount = repeatCount; return this; }
WithInterval:以毫秒為單位指定重複間隔,由於是TimeSpan也可以指定時分秒
WithIntervalInHours:以小時為單位指定重複間隔
WithIntervalInMinutes:以分鐘單位指定重複間隔
WithIntervalInSeconds:以秒為單位指定重複間隔
var trigger = TriggerBuilder.Create().WithSimpleSchedule(s=>s .WithIntervalInSeconds(1) .WithInterval(TimeSpan.FromDays(1)) .WithIntervalInMinutes(1) .WithIntervalInHours(1) .WithRepeatCount(5)) .Build();
注:底層都是通過WithInterval實現的
/// <summary> /// Specify a repeat interval in milliseconds. /// </summary> /// <remarks> /// </remarks> /// <param name="timeSpan">the time span at which the trigger should repeat.</param> /// <returns>the updated SimpleScheduleBuilder</returns> /// <seealso cref="ISimpleTrigger.RepeatInterval" /> /// <seealso cref="WithRepeatCount(int)" /> public SimpleScheduleBuilder WithInterval(TimeSpan timeSpan) { interval = timeSpan; return this; } /// <summary> /// Specify a repeat interval in seconds. /// </summary> /// <remarks> /// </remarks> /// <param name="seconds">the time span at which the trigger should repeat.</param> /// <returns>the updated SimpleScheduleBuilder</returns> /// <seealso cref="ISimpleTrigger.RepeatInterval" /> /// <seealso cref="WithRepeatCount(int)" /> public SimpleScheduleBuilder WithIntervalInSeconds(int seconds) { return WithInterval(TimeSpan.FromSeconds(seconds)); }
靜態方法:
RepeatMinutelyForever
RepeatMinutelyForTotalCount
RepeatSecondlyForever
RepeatSecondlyForTotalCount
RepeatHourlyForever
RepeatHourlyForTotalCount
var trigger = TriggerBuilder.Create().WithSchedule(SimpleScheduleBuilder.RepeatSecondlyForTotalCount(2)).Build();
/// <summary> /// Create a SimpleScheduleBuilder set to repeat forever with a 1 minute interval. /// </summary> /// <remarks> /// </remarks> /// <returns>the new SimpleScheduleBuilder</returns> public static SimpleScheduleBuilder RepeatMinutelyForever() { SimpleScheduleBuilder sb = Create() .WithInterval(TimeSpan.FromMinutes(1)) .RepeatForever(); return sb; } /// <summary> /// Create a SimpleScheduleBuilder set to repeat forever with an interval /// of the given number of minutes. /// </summary> /// <remarks> /// </remarks> /// <returns>the new SimpleScheduleBuilder</returns> public static SimpleScheduleBuilder RepeatMinutelyForever(int minutes) { SimpleScheduleBuilder sb = Create() .WithInterval(TimeSpan.FromMinutes(minutes)) .RepeatForever(); return sb; } /// <summary> /// Create a SimpleScheduleBuilder set to repeat forever with a 1 second interval. /// </summary> /// <remarks> /// </remarks> /// <returns>the new SimpleScheduleBuilder</returns> public static SimpleScheduleBuilder RepeatSecondlyForever() { SimpleScheduleBuilder sb = Create() .WithInterval(TimeSpan.FromSeconds(1)) .RepeatForever(); return sb; } /// <summary> /// Create a SimpleScheduleBuilder set to repeat forever with an interval /// of the given number of seconds. /// </summary> /// <remarks> /// </remarks> /// <returns>the new SimpleScheduleBuilder</returns> public static SimpleScheduleBuilder RepeatSecondlyForever(int seconds) { SimpleScheduleBuilder sb = Create() .WithInterval(TimeSpan.FromSeconds(seconds)) .RepeatForever(); return sb; } /// <summary> /// Create a SimpleScheduleBuilder set to repeat forever with a 1 hour interval. /// </summary> /// <remarks> /// </remarks> /// <returns>the new SimpleScheduleBuilder</returns> public static SimpleScheduleBuilder RepeatHourlyForever() { SimpleScheduleBuilder sb = Create() .WithInterval(TimeSpan.FromHours(1)) .RepeatForever(); return sb; } /// <summary> /// Create a SimpleScheduleBuilder set to repeat forever with an interval /// of the given number of hours. /// </summary> /// <remarks> /// </remarks> /// <returns>the new SimpleScheduleBuilder</returns> public static SimpleScheduleBuilder RepeatHourlyForever(int hours) { SimpleScheduleBuilder sb = Create() .WithInterval(TimeSpan.FromHours(hours)) .RepeatForever(); return sb; } /// <summary> /// Create a SimpleScheduleBuilder set to repeat the given number /// of times - 1 with a 1 minute interval. /// </summary> /// <remarks> /// <para>Note: Total count = 1 (at start time) + repeat count</para> /// </remarks> /// <returns>the new SimpleScheduleBuilder</returns> public static SimpleScheduleBuilder RepeatMinutelyForTotalCount(int count) { if (count < 1) { throw new ArgumentException("Total count of firings must be at least one! Given count: " + count); } SimpleScheduleBuilder sb = Create() .WithInterval(TimeSpan.FromMinutes(1)) .WithRepeatCount(count - 1); return sb; } /// <summary> /// Create a SimpleScheduleBuilder set to repeat the given number /// of times - 1 with an interval of the given number of minutes. /// </summary> /// <remarks> /// <para>Note: Total count = 1 (at start time) + repeat count</para> /// </remarks> /// <returns>the new SimpleScheduleBuilder</returns> public static SimpleScheduleBuilder RepeatMinutelyForTotalCount(int count, int minutes) { if (count < 1) { throw new ArgumentException("Total count of firings must be at least one! Given count: " + count); } SimpleScheduleBuilder sb = Create() .WithInterval(TimeSpan.FromMinutes(minutes)) .WithRepeatCount(count - 1); return sb; } /// <summary> /// Create a SimpleScheduleBuilder set to repeat the given number /// of times - 1 with a 1 second interval. /// </summary> /// <remarks> /// <para>Note: Total count = 1 (at start time) + repeat count</para> /// </remarks> /// <returns>the new SimpleScheduleBuilder</returns> public static SimpleScheduleBuilder RepeatSecondlyForTotalCount(int count) { if (count < 1) { throw new ArgumentException("Total count of firings must be at least one! Given count: " + count); } SimpleScheduleBuilder sb = Create() .WithInterval(TimeSpan.FromSeconds(1)) .WithRepeatCount(count - 1); return sb; } /// <summary> /// Create a SimpleScheduleBuilder set to repeat the given number /// of times - 1 with an interval of the given number of seconds. /// </summary> /// <remarks> /// <para>Note: Total count = 1 (at start time) + repeat count</para> /// </remarks> /// <returns>the new SimpleScheduleBuilder</returns> public static SimpleScheduleBuilder RepeatSecondlyForTotalCount(int count, int seconds) { if (count < 1) { throw new ArgumentException("Total count of firings must be at least one! Given count: " + count); } SimpleScheduleBuilder sb = Create() .WithInterval(TimeSpan.FromSeconds(seconds)) .WithRepeatCount(count - 1); return sb; } /// <summary> /// Create a SimpleScheduleBuilder set to repeat the given number /// of times - 1 with a 1 hour interval. /// </summary> /// <remarks> /// <para>Note: Total count = 1 (at start time) + repeat count</para> /// </remarks> /// <returns>the new SimpleScheduleBuilder</returns> public static SimpleScheduleBuilder RepeatHourlyForTotalCount(int count) { if (count < 1) { throw new ArgumentException("Total count of firings must be at least one! Given count: " + count); } SimpleScheduleBuilder sb = Create() .WithInterval(TimeSpan.FromHours(1)) .WithRepeatCount(count - 1); return sb; } /// <summary> /// Create a SimpleScheduleBuilder set to repeat the given number /// of times - 1 with an interval of the given number of hours. /// </summary> /// <remarks> /// <para>Note: Total count = 1 (at start time) + repeat count</para> /// </remarks> /// <returns>the new SimpleScheduleBuilder</returns> public static SimpleScheduleBuilder RepeatHourlyForTotalCount(int count, int hours) { if (count < 1) { throw new ArgumentException("Total count of firings must be at least one! Given count: " + count); } SimpleScheduleBuilder sb = Create() .WithInterval(TimeSpan.FromHours(hours)) .WithRepeatCount(count - 1); return sb; }
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※推薦評價好的iphone維修中心
現在,我們絕大多數人都會在網上購物買東西。但是很多人都不清楚的是,很多電商網站會存在安全漏洞。烏雲就通報過,國內很多家公司的網站都存在 CSRF 漏洞。如果某個網站存在這種安全漏洞的話,那麼我們在購物的過程中,就很可能會被網絡黑客盜刷信用卡。是不是瞬間有點「不寒而栗」 的感覺?
首先,我們需要弄清楚 CSRF 是什麼。它的全稱是 Cross-site request forgery ,翻譯成中文的意思就是「跨站請求偽造」,這是一種對網站的惡意利用。簡單而言,就是某惡意網站在我們不知情的情況下,以我們的身份在你登錄的某網站上胡作非為——發消息、買東西,甚至轉賬……
這種攻擊模式聽起來有點像跨站腳本(XSS),但 CSRF 與 XSS 非常不同,並且攻擊方式幾乎相左。XSS 利用站點內的信任用戶,而 CSRF 則通過偽裝來自受信任用戶的請求來利用受信任的網站。與 XSS 攻擊相比,CSRF 攻擊往往很少見,因此對其進行防範的資源也相當稀少。不過,這種「受信任」的攻擊模式更加難以防範,所以被認為比 XSS 更具危險性。
這個過程到底是怎樣的呢?讓我們看個簡單而鮮活的案例。
銀行網站 A,它以 GET 請求來完成銀行轉賬的操作,如:
http://www.mybank.com/Transfer.php?toBankId=11&money=1000
危險網站 B,它裏面有一段 HTML 的代碼如下:
<img src=http://www.mybank.com/Transfer.php?toBankId=11&money=1000>
可能會發生什麼?你登錄了銀行網站 A,然後訪問危險網站 B 以後,突然發現你的銀行賬戶少了10000塊……
為什麼會這樣呢?原因是在訪問危險網站 B 之前,你已經登錄了銀行網站 A,而 B 中的以 GET 的方式請求第三方資源(這裏的第三方就是指銀行網站了,原本這是一個合法的請求,但這裏被不法分子利用了),所以你的瀏覽器會帶上你的銀行網站 A 的 Cookie 發出 GET 請求,去獲取資源
「http://www.mybank.com/Transfer.php?toBankId=11&money=1000」,
結果銀行網站服務器收到請求后,認為這是一個合理的轉賬操作,就立刻轉賬了……
其實,真實的銀行網站不會如此不加防範,但即使用 POST 替代 GET,也只是讓危險網站多花些力氣而已。危險網站 B 依然可以通過嵌入 Javascript 來嘗試盜取客戶資金,所以我們時不時會聽到客戶資金被盜的案件,其實這並不是很不稀奇。
相信,很多人了解到這兒,會出現一身冷汗,還讓不讓我們在「618」期間能夠愉快地享受網購的快感了?難道沒有什麼辦法防住它嘛?
當然是有的。
在業界目前防禦 CSRF 攻擊主要有三種策略:驗證 HTTP Referer 字段;在請求地址中添加 token 並驗證;在 HTTP 頭中自定義屬性並驗證。下面就分別對這三種策略進行詳細介紹。
根據 HTTP 協議,在 HTTP 頭中有一個字段叫 Referer,它記錄了該 HTTP 請求的來源地址。在通常情況下,訪問一個安全受限頁面的請求來自於同一個網站,比如需要訪問http://bank.example/withdraw?account=bob&amount=1000000&for=Mallory,用戶必須先登陸 bank.example,然後通過點擊頁面上的按鈕來觸發轉賬事件。這時,該轉帳請求的 Referer 值就會是轉賬按鈕所在的頁面的 URL,通常是以 bank.example 域名開頭的地址。而如果黑客要對銀行網站實施 CSRF 攻擊,他只能在他自己的網站構造請求,當用戶通過黑客的網站發送請求到銀行時,該請求的 Referer 是指向黑客自己的網站。因此,要防禦 CSRF 攻擊,銀行網站只需要對於每一個轉賬請求驗證其 Referer 值,如果是以 bank.example 開頭的域名,則說明該請求是來自銀行網站自己的請求,是合法的。如果 Referer 是其他網站的話,則有可能是黑客的 CSRF 攻擊,拒絕該請求。
這種方法的顯而易見的好處就是簡單易行,網站的普通開發人員不需要操心 CSRF 的漏洞,只需要在最後給所有安全敏感的請求統一增加一個攔截器來檢查 Referer 的值就可以。特別是對於當前現有的系統,不需要改變當前系統的任何已有代碼和邏輯,沒有風險,非常便捷。
然而,這種方法並非萬無一失。Referer 的值是由瀏覽器提供的,雖然 HTTP 協議上有明確的要求,但是每個瀏覽器對於 Referer 的具體實現可能有差別,並不能保證瀏覽器自身沒有安全漏洞。使用驗證 Referer 值的方法,就是把安全性都依賴於第三方(即瀏覽器)來保障,從理論上來講,這樣並不安全。事實上,對於某些瀏覽器,比如 IE6 或 FF2,目前已經有一些方法可以篡改 Referer 值。如果 bank.example 網站支持 IE6 瀏覽器,黑客完全可以把用戶瀏覽器的 Referer 值設為以 bank.example 域名開頭的地址,這樣就可以通過驗證,從而進行 CSRF 攻擊。
即便是使用最新的瀏覽器,黑客無法篡改 Referer 值,這種方法仍然有問題。因為 Referer 值會記錄下用戶的訪問來源,有些用戶認為這樣會侵犯到他們自己的隱私權,特別是有些組織擔心 Referer 值會把組織內網中的某些信息泄露到外網中。因此,用戶自己可以設置瀏覽器使其在發送請求時不再提供 Referer。當他們正常訪問銀行網站時,網站會因為請求沒有 Referer 值而認為是 CSRF 攻擊,拒絕合法用戶的訪問。
CSRF 攻擊之所以能夠成功,是因為黑客可以完全偽造用戶的請求,該請求中所有的用戶驗證信息都是存在於 cookie 中,因此黑客可以在不知道這些驗證信息的情況下直接利用用戶自己的 cookie 來通過安全驗證。要抵禦 CSRF,關鍵在於在請求中放入黑客所不能偽造的信息,並且該信息不存在於 cookie 之中。可以在 HTTP 請求中以參數的形式加入一個隨機產生的 token,並在服務器端建立一個攔截器來驗證這個 token,如果請求中沒有 token 或者 token 內容不正確,則認為可能是 CSRF 攻擊而拒絕該請求。
這種方法要比檢查 Referer 要安全一些,token 可以在用戶登陸后產生並放於 session 之中,然後在每次請求時把 token 從 session 中拿出,與請求中的 token 進行比對,但這種方法的難點在於如何把 token 以參數的形式加入請求。對於 GET 請求,token 將附在請求地址之後,這樣 URL 就變成 http://url?csrftoken=tokenvalue。 而對於 POST 請求來說,要在 form 的最後加上 <input type=”hidden” name=”csrftoken” value=”tokenvalue”/>,這樣就把 token 以參數的形式加入請求了。但是,在一個網站中,可以接受請求的地方非常多,要對於每一個請求都加上 token 是很麻煩的,並且很容易漏掉,通常使用的方法就是在每次頁面加載時,使用 javascript 遍歷整個 dom 樹,對於 dom 中所有的 a 和 form 標籤后加入 token。這樣可以解決大部分的請求,但是對於在頁面加載之後動態生成的 html 代碼,這種方法就沒有作用,還需要程序員在編碼時手動添加 token。
該方法還有一個缺點是難以保證 token 本身的安全。特別是在一些論壇之類支持用戶自己發表內容的網站,黑客可以在上面發布自己個人網站的地址。由於系統也會在這個地址後面加上 token,黑客可以在自己的網站上得到這個 token,並馬上就可以發動 CSRF 攻擊。為了避免這一點,系統可以在添加 token 的時候增加一個判斷,如果這個鏈接是鏈到自己本站的,就在後面添加 token,如果是通向外網則不加。不過,即使這個 csrftoken 不以參數的形式附加在請求之中,黑客的網站也同樣可以通過 Referer 來得到這個 token 值以發動 CSRF 攻擊。這也是一些用戶喜歡手動關閉瀏覽器 Referer 功能的原因。
這種方法也是使用 token 並進行驗證,和上一種方法不同的是,這裏並不是把 token 以參數的形式置於 HTTP 請求之中,而是把它放到 HTTP 頭中自定義的屬性里。通過 XMLHttpRequest 這個類,可以一次性給所有該類請求加上 csrftoken 這個 HTTP 頭屬性,並把 token 值放入其中。這樣解決了上種方法在請求中加入 token 的不便,同時,通過 XMLHttpRequest 請求的地址不會被記錄到瀏覽器的地址欄,也不用擔心 token 會透過 Referer 泄露到其他網站中去。
然而這種方法的局限性非常大。XMLHttpRequest 請求通常用於 Ajax 方法中對於頁面局部的異步刷新,並非所有的請求都適合用這個類來發起,而且通過該類請求得到的頁面不能被瀏覽器所記錄下,從而進行前進,後退,刷新,收藏等操作,給用戶帶來不便。另外,對於沒有進行 CSRF 防護的遺留系統來說,要採用這種方法來進行防護,要把所有請求都改為 XMLHttpRequest 請求,這樣幾乎是要重寫整個網站,這代價無疑是不能接受的。
下文將以 Java 為例,對上述三種方法分別用代碼進行示例。無論使用何種方法,在服務器端的攔截器必不可少,它將負責檢查到來的請求是否符合要求,然後視結果而決定是否繼續請求或者丟棄。在 Java 中,攔截器是由 Filter 來實現的。我們可以編寫一個 Filter,並在 web.xml 中對其進行配置,使其對於訪問所有需要 CSRF 保護的資源的請求進行攔截。
在 filter 中對請求的 Referer 驗證代碼如下
清單 1. 在 Filter 中驗證 Referer
// 從 HTTP 頭中取得 Referer 值 String referer=request.getHeader("Referer"); // 判斷 Referer 是否以 bank.example 開頭 if((referer!=null) &&(referer.trim().startsWith(“bank.example”))){ chain.doFilter(request, response); }else{ request.getRequestDispatcher(“error.jsp”).forward(request,response); }
以上代碼先取得 Referer 值,然後進行判斷,當其非空並以 bank.example 開頭時,則繼續請求,否則的話可能是 CSRF 攻擊,轉到 error.jsp 頁面。
如果要進一步驗證請求中的 token 值,代碼如下
清單 2. 在 filter 中驗證請求中的 token
HttpServletRequest req = (HttpServletRequest)request; HttpSession s = req.getSession(); // 從 session 中得到 csrftoken 屬性 String sToken = (String)s.getAttribute(“csrftoken”); if(sToken == null){ // 產生新的 token 放入 session 中 sToken = generateToken(); s.setAttribute(“csrftoken”,sToken); chain.doFilter(request, response); } else{ // 從 HTTP 頭中取得 csrftoken String xhrToken = req.getHeader(“csrftoken”); // 從請求參數中取得 csrftoken String pToken = req.getParameter(“csrftoken”); if(sToken != null && xhrToken != null && sToken.equals(xhrToken)){ chain.doFilter(request, response); }else if(sToken != null && pToken != null && sToken.equals(pToken)){ chain.doFilter(request, response); }else{ request.getRequestDispatcher(“error.jsp”).forward(request,response); } }
首先判斷 session 中有沒有 csrftoken,如果沒有,則認為是第一次訪問,session 是新建立的,這時生成一個新的 token,放於 session 之中,並繼續執行請求。如果 session 中已經有 csrftoken,則說明用戶已經與服務器之間建立了一個活躍的 session,這時要看這個請求中有沒有同時附帶這個 token,由於請求可能來自於常規的訪問或是 XMLHttpRequest 異步訪問,我們分別嘗試從請求中獲取 csrftoken 參數以及從 HTTP 頭中獲取 csrftoken 自定義屬性並與 session 中的值進行比較,只要有一個地方帶有有效 token,就判定請求合法,可以繼續執行,否則就轉到錯誤頁面。生成 token 有很多種方法,任何的隨機算法都可以使用,Java 的 UUID 類也是一個不錯的選擇。
除了在服務器端利用 filter 來驗證 token 的值以外,我們還需要在客戶端給每個請求附加上這個 token,這是利用 js 來給 html 中的鏈接和表單請求地址附加 csrftoken 代碼,其中已定義 token 為全局變量,其值可以從 session 中得到。
清單 3. 在客戶端對於請求附加 token
function appendToken(){ updateForms(); updateTags(); } function updateForms() { // 得到頁面中所有的 form 元素 var forms = document.getElementsByTagName('form'); for(i=0; i<forms.length; i++) { var url = forms[i].action; // 如果這個 form 的 action 值為空,則不附加 csrftoken if(url == null || url == "" ) continue; // 動態生成 input 元素,加入到 form 之後 var e = document.createElement("input"); e.name = "csrftoken"; e.value = token; e.type="hidden"; forms[i].appendChild(e); } } function updateTags() { var all = document.getElementsByTagName('a'); var len = all.length; // 遍歷所有 a 元素 for(var i=0; i<len; i++) { var e = all[i]; updateTag(e, 'href', token); } } function updateTag(element, attr, token) { var location = element.getAttribute(attr); if(location != null && location != '' '' ) { var fragmentIndex = location.indexOf('#'); var fragment = null; if(fragmentIndex != -1){ //url 中含有隻相當頁的錨標記 fragment = location.substring(fragmentIndex); location = location.substring(0,fragmentIndex); } var index = location.indexOf('?'); if(index != -1) { //url 中已含有其他參數 location = location + '&csrftoken=' + token; } else { //url 中沒有其他參數 location = location + '?csrftoken=' + token; } if(fragment != null){ location += fragment; } element.setAttribute(attr, location); } }
在客戶端 html 中,主要是有兩個地方需要加上 token,一個是表單 form,另一個就是鏈接 a。這段代碼首先遍歷所有的 form,在 form 最後添加一隱藏字段,把 csrftoken 放入其中。然後,代碼遍歷所有的鏈接標記 a,在其 href 屬性中加入 csrftoken 參數。注意對於 a.href 來說,可能該屬性已經有參數,或者有錨標記。因此需要分情況討論,以不同的格式把 csrftoken 加入其中。
如果你的網站使用 XMLHttpRequest,那麼還需要在 HTTP 頭中自定義 csrftoken 屬性,利用 dojo.xhr 給 XMLHttpRequest 加上自定義屬性代碼如下:
清單 4. 在 HTTP 頭中自定義屬性
var plainXhr = dojo.xhr; // 重寫 dojo.xhr 方法 dojo.xhr = function(method,args,hasBody) { // 確保 header 對象存在 args.headers = args.header || {}; tokenValue = '<%=request.getSession(false).getAttribute("csrftoken")%>'; var token = dojo.getObject("tokenValue"); // 把 csrftoken 屬性放到頭中 args.headers["csrftoken"] = (token) ? token : " "; return plainXhr(method,args,hasBody); };
這裏改寫了 dojo.xhr 的方法,首先確保 dojo.xhr 中存在 HTTP 頭,然後在 args.headers 中添加 csrftoken 字段,並把 token 值從 session 里拿出放入字段中。
通過上文討論可知,目前業界應對 CSRF 攻擊有一些克制方法,但是每種方法都有利弊,沒有一種方法是完美的。如何選擇合適的方法非常重要。如果網站是一個現有系統,想要在最短時間內獲得一定程度的 CSRF 的保護,那麼驗證 Referer 的方法是最方便的,要想增加安全性的話,可以選擇不支持低版本瀏覽器,畢竟就目前來說,IE7+, FF3+ 這類高版本瀏覽器的 Referer 值還無法被篡改。
如果系統必須支持 IE6,並且仍然需要高安全性。那麼就要使用 token 來進行驗證,在大部分情況下,使用 XmlHttpRequest 並不合適,token 只能以參數的形式放於請求之中,若你的系統不支持用戶自己發布信息,那這種程度的防護已經足夠,否則的話,你仍然難以防範 token 被黑客竊取並發動攻擊。在這種情況下,你需要小心規劃你網站提供的各種服務,從中間找出那些允許用戶自己發布信息的部分,把它們與其他服務分開,使用不同的 token 進行保護,這樣可以有效抵禦黑客對於你關鍵服務的攻擊,把危害降到最低。畢竟,刪除別人一個帖子比直接從別人賬號中轉走大筆存款嚴重程度要輕的多。
如果是開發一個全新的系統,則抵禦 CSRF 的選擇要大得多。筆者建議對於重要的服務,可以盡量使用 XMLHttpRequest 來訪問,這樣增加 token 要容易很多。另外盡量避免在 js 代碼中使用複雜邏輯來構造常規的同步請求來訪問需要 CSRF 保護的資源,比如 window.location 和 document.createElement(“a”) 之類,這樣也可以減少在附加 token 時產生的不必要的麻煩。
最後,要記住 CSRF 不是黑客唯一的攻擊手段,無論你 CSRF 防範有多麼嚴密,如果你系統有其他安全漏洞,比如跨站域腳本攻擊 XSS,那麼黑客就可以繞過你的安全防護,展開包括 CSRF 在內的各種攻擊,你的防線將如同虛設。我們只有充分重視 CSRF,根據系統的實際情況選擇最合適的策略,這樣才能把 CSRF 的危害降到最低。
點擊關注,第一時間了解華為雲新鮮技術~
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
在這之前已經把編輯個人的所有信息的功能已經完成了
之後先對首頁的列表搞動態的,之前都是寫死的靜態
1、之前都是把好友寫死的,現在就在js裏面定義一個數組,用循環來動態的綁定
在onReady中定義,取真實的數據給定義的列表數組list
通過調用 db.collection(‘users’).get() 這裏沒有加其他的限制,得到的就是所有的數據了,拿到全部的數據之後就會觸發then方法了
用then返回的res中有一個data的列表集合,有一個注意的點就是,這樣子讀取是吧數據庫中的數據的全部字段,但是我們需要用的只是
用戶的頭像和點贊數、用戶昵稱,其他的數據其實是不需要的
可以加一個field方法,可以要求返回的字段是哪些的
可以看到是只有一個用戶,我們為了模擬的話,就可以多賬號進行調試,
1、創立多賬號
①首先這個多賬號的一定要是測試號,所以先進入微信的管理後台 https://mp.weixin.qq.com/
②進入 【成員管理】添加項目成員
③回到微信開發者工具中-》工具-》多賬號調試-》可以通過添加虛擬測試號來進行測試的,不用真實的微信號都可以
之後就是對點贊的功能進行設計了(就可以在index.wxml中給點贊的小心上加一個點擊事件即可了
(小細節在小程序中規定,在客戶端中讀取用戶列表的時候,一般不會把整個數據庫的用戶都讀取出來的,是有一個限制的
一般都是把前二十條數據給讀取出來的,如果數據一多的話,一般都是進行分頁處理了–一般都是用數據庫中的collection.skip和collection.limit,這兩個東西一起配合的話就可以做下拉加載的功能了)
由於這個點贊是要對找到用戶的id地址的,所以在wxml中給點贊這個圖標加上一個id自定義屬性的掛載
data-id="{{ item._id}}"
這個東西的用處就是,在點擊這個心心的時候就可以拿到這個自定義的屬性id了
通過把handleLinks(ev)函數中把ev打印出來發現,這個自定義屬性id 的位置在
ev.target.dataset.id
console.log就是用來測試的,如果沒效果的話,一般都是直接在點擊事件後面通過promise 的then把res打印出來看看情況是怎麼樣的
***有時候這些點擊事件無法觸發的話,就可以在檢查一下樣式,可能這個區域在前端显示是在這裏,但是實際上是在其他的地方,
也就是布局引起的問題了
可以看到這裏就是碰到的是點贊的這個圖標,但是這個樣式是在左上角進行了渲染的
這個時候為了演示把,就把自定義屬性,和點擊事件放在點贊圖標還有點贊數包含的這個text裏面了
<text bindtap="handleLinks" data-id="{{ item._id}}" > <!-- 點贊圖標 --> <text class="iconfont icondianzan" ></text> <!-- 點贊數 --> <text>{{ item.links }}</text> </text>
改完之後,再點擊心心或者是數量,就可以正常的進行點贊了
但是發現只有給自己點贊的時候才可以改變點贊的數量,而改其他人點贊的時候就改不了
比如:
這就是一個權限的問題了也就是只能改自己的數據(點贊數)改不了別人的數據l
因為在小程序端中,由於用戶可以直接對數據庫進行操作,所以會有一定的風險,所以就通過這個訪問權限來進行了限制
那?
怎麼修改別人的數據呢?—這個操作就要在服務端來進行操作了! 也就是在雲函數中去完成一個雲函數的操作了
下面就是講解 如何在 服務端來對数字字段來進行更改!
二、點贊功能實現與update雲函數
由於要在服務端來做的話,就可以把這一塊的部分代碼刪掉了
handleLinks(ev){ let id = ev.target.dataset.id; db.collection('users').doc(id).update({ data : { links : 5 } }).then((res)=>{ console.log(res) }); }
需要新創一個雲函數(新建一個node.js雲函數
這些默認的結構都是可以刪掉的了
之後就是參考 微信開放文檔 雲開發-》SDK文檔->數據庫-》collection->update-》示例代碼demo
其中:這個就是指定了數據庫的環境
cloud.init({
env: cloud.DYNAMIC_CURRENT_ENV
})
然後就是在服務端拿到數據庫db
const db = cloud.database()
然後可以在示例代碼中看到async這個異步的操作
直接複製 try catch
try { return await db.collection('todos').where({ done: false }) .update({ data: { progress: _.inc(10) }, }) } catch(e) { console.error(e) }
return就是返回一個異步的數據,而catch就是返回錯誤信息
主要修改的就是 db.collecion()中要反問那個數據庫表單,這裏不能寫死為users,因為可能其他的地方也是要用到更新的這個功能的
所以最好就是把update這個雲函數寫成一個通用的方式
其中雲函數入口函數
exports.main = async (event, context) => { 這個裡面的event就是前端傳參過來的對象了 就訪問 event.colletion,然後不用where而是用doc 再把event的doc也傳進來,這 ***小知識點:ES6的擴展運算符 。。。 (三個點)
更新成功了之後,就可以返回結果到前台了
這個就是update雲函數中js文件的代碼(傳進去的doc實際上是用戶的_id
// 雲函數入口文件 const cloud = require('wx-server-sdk') cloud.init({ env: cloud.DYNAMIC_CURRENT_ENV }) const db = cloud.database() // 雲函數入口函數 exports.main = async (event, context) => { try { return await db.collection(event.collection).doc(event.doc) .update({ data: { ...event.data }, }) } catch (e) { console.error(e) } }
View Code
把雲函數寫好之後,這個時候雲函數還是在本地,要把這個雲函數傳到雲開發平台上
上傳了之後一定要去雲平台-》雲函數中去檢查一下
之後就可以調用這個雲函數了
再回到index.js 點贊的方法 handleLinkes方法中進行設置即可;
如果雲函數沒問題,可能是雲函數裏面定義的env出了問題,就可以寫死了,傳入自己的那個環境,就不用默認的那個環境了
【注意】修改了雲函數記得要重新上傳到雲平台才行
(因為在服務端是不會受到數據庫權限的限制的)
後面要優化的就是(上面的點贊是寫死給多少links的,並且不能點完之後立馬更新
可以把數據庫的links讀出來,+1之後再寫入,但是這樣的話就多了一個數據庫的操縱了 ,但是數據庫本身就提供了累加或者累減等運算的操作的
(這樣的話就只需要一次的數據庫讀取即可了)
在開放文檔 db.command裏面就有很多的方法
https://developers.weixin.qq.com/miniprogram/dev/wxcloud/reference-sdk-api/database/command/Command.inc.html
示例代碼 將一個 todo 的進度自增 10: const _ = db.command db.collection('todos').doc('todo-id').update({ data: { progress: _.inc(10) } })
為了在服務端不把運算給寫死了,一般都是把運算直接通過前端來傳入的
由於前端不認識下劃線這種操作,因為前端要先解析,之後再把東西傳到服務端的,所以就可以在前端給服務端傳一個字符串的話
然後再在服務端解析即可
data : "{links : _.inc(1)}"
在前端把這個字符串傳入到服務端中,之後就可以在服務端那邊對這個字符串進行解析了
所以在update雲函數中 就要對event.data這個傳過來的數據進行判斷,判斷它的類型,是普通的還是字符串類型的,如果是字符串類型的話就要進行解析
用js裏面的eval方法,它是把字符串轉成 js 語句的
if(typeof event.data == 'string'){ event.data = eval('(' + event.data + ')') }
即可了(點一下心心就可以讓點贊數+1)
後面有空的話,可以繼續進行優化,也就是對一次的點贊數進行限制,或者是點一下加+1,再點一下就是取消了就-1了
後面就是要把點贊了之後,實時的把點贊數進行更新
可以看到給服務端那邊上傳之後,對數據庫進行了更新之後,then返回的結果res,中有一個是updated==1,就可以進行if判斷了
再用for循環對列表中的每一個元素判斷,是不是現在被點擊點贊的這個id
let updated = res.result.stats.updated; if(updated){ // 先用擴展運算符 克隆一份數組 let cloneListData = [...this.data.listData]; for(let i = 0;i < cloneListData.length ; i++){ if( cloneListData[i]._id == id){ cloneListData[i].links++; } } this.setData({ listData : cloneListData }); }
點贊數增加 就是通過_inc 但是在服務端中的update函數中是用全局的,不能寫死,所以運算的規則就通過前端傳過去
為了以後其他的頁面也有更新功能的話做準備了
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案
單一職責原則(Single Responsibility Principle, SRP):一個類只負責一個功能領域中的相應職責,或者可以定義為:就一個類而言,應該只有一個引起它變化的原因。
單一職責原則是實現高內聚、低耦合的指導方針,它是最簡單但又最難運用的原則
單一職責原則是最簡單的面向對象設計原則,它用於控制類的粒度大小
設計原則很重要的一點就是簡單,單一職責,也就是我們經常所說的專人干專事。
一個單元(一個類、函數或者微服務)應該有且只有一個職責。無論如何,一個微服務不應該包含多於一個的職責。職責單一的後果之一就是職責單位(微服務,類,接口,函數)的數量劇增。據說Amazon,Netflix這些採用微服務架構的網站一個小功能就會調用幾十上百個微服務。但是相較於每個函數都是多個業務邏輯或職責功能的混合體的情況,維護成本還是低很多的。 SRP中的“單一職責”是個比較模糊的概念。對於函數,它可能指單一的功能,不涉及複雜邏輯;但對於類或者接口,它可能是指對單一對象的操作,也可能是指對該對象單一屬性的操作。總而言之,單一職責原則就是為了讓代碼邏輯更加清晰,可維護性更好,定位問題更快的一種設計原則。
這犀利的措辭一看就是來自開發界的術語。高內聚是說一個功能模塊最好僅完成一個獨立的子功能並且完成的很好。低耦合是指模塊與模塊之間盡量獨立/聯繫少/接口簡單。
這個原則出現的背景是為了讓程序“可復用/可擴展/夠靈活/可維護”。干過一陣子產品的人對這幾個詞應該都不陌生。對於程序設計者來說,這幾個詞是十分重要的,不亞於產品經理口中的“用戶體驗”(原則or擋箭牌)。
單一職責的優點如下:
•類的複雜性降低,實現什麼職責都有清晰明確的定義。•可讀性提高,複雜性降低。•可維護性提高,可讀性提高。•變更引起的風險降低,變更是必不可少的,如果接口的單一職責做得好,一個接口修改只對相應的實現類有影響,對其他的接口無影響,這對系統的擴展性、維護性都有非常大的幫助。
記得在三字經裡邊有這樣一段 教之道,貴以專(出自三字經) 說的就是無論學習還是構建團隊,最重要的是專才,而不是全才。就好比一個足球隊,如果都是前鋒或者都是後衛,那麼這樣的球隊一定不能出成績,反而是將各個位置上的人進行統一協調,根據分工不同,共同協作,形成1+1>2的效果,那麼這樣的團隊就非常容易出成績。
有很多公司為了趕進度,經常會招聘一些所謂的全能型人才,但是這種人往往專業的程度不夠,當遇到某些棘手的問題的時候,往往不能夠非常快速的解決問題。從而導致最終交付的質量較差。
實施單一職責的目的如下:
•以類來隔離需求功能點,這樣當一個點的需求發生變化的時候,不會影響別的類的邏輯,這個和設計模式中的開閉原則類似,對於擴展持開放態度,對於修改持關閉態度。•是一個原子模塊級的粒度,至於原子的粒度到底是什麼樣的,應該因業務而異,設計的過程中同時考慮業務的擴展,所以這就要求在設計的過程中,必須有業務專家共同參与,共同規避風險。•粒度小,靈活,復用性強,方便更高一級別的抽象。
每個微服務單獨運行在獨立的進程中,能夠實現松耦合,並且獨立部署。
分3步:
1.把一個具體的問題抽象成一類問題;
2.根據用戶體驗流程劃分功能模塊;
3.針對每個功能設計封閉的解決方案。
在實際工作中,有一個經常會用到的設計模式,DAO模式,又叫數據訪問對象,裏面定義了數據庫中表的增、刪、改、查操作,按照單一職責原則,為什麼不把增、刪、改、查分別定義成四種接口?這是因為數據庫的表操作,基本上就是這四種類型,不可能變化,所以沒有必要分開定義,反而經常變化的是數據庫的表結構,表結構一變,這四種操作都要跟着變。所以通常我們會針對一張表實現一個DAO,一張表就代表一種類型的職責。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計最專業,超強功能平台可客製化
前面講解ls命令時,我們已經知道長格式显示的第一列就是文件的權限,例如:
[root@es ~]# ls -l anaconda-ks.cfg
-rw-------. 1 root root 1573 May 18 23:28 anaconda-ks.cfg
第一位為文件類型
| 文件類型標識 | 文件類型 |
|---|---|
| – | 普通文件 |
| d | 目錄文件 |
| l | 軟鏈接文件 |
| s(偽文件) | 套接字文件 |
| b(偽文件) | 塊設備文件 |
| c(偽文件) | 字符設備文件 |
| p(偽文件) | 管道符文件 |
第一列的權限位如果不計算最後的 “.” (這個點的含義我們在後面解釋),則共有10位,這10位權限位的含義如圖所示。
修改權限的命令 chmod ,基本信息如下
[root@es ~]#chmod [選項] 權限模式 文件名
選項:
-R : 遞歸設置權限,也就是給子目錄中的所有文件設定權限
chmod 命令的權限模式的格式時”[ugoa][[+-=][perms]]”,也就是“[用戶身份][[賦予方式][權限]]”的格式
用戶身份:
u:代表所有者(user)
g:代表所屬組(group)
o:代表其他人(other)
a:代表全部身份(all)
賦予方式:
+:加入權限
-:減去權限
=:設置權限
權限:
-r:讀取權限(read)
-w:寫權限(write)
-x:執行權限(execute)
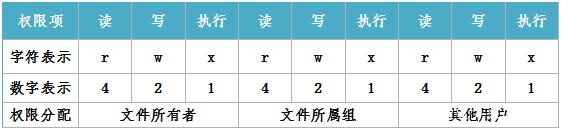
数字權限的賦予方式是最簡單的,但是不如之前的字母權限好記,直觀。我們來看看這些数字權限的含義。
4:代表”r”權限
2:代表”w”權限
1:代表”x”權限
数字權限的賦予方式更加簡單,但是需要用戶對這幾個数字更加熟悉。其實常用權限也並不多,只有如下幾個。
644:這是文件的基本權限,代表所有者擁有讀,寫權限,而所屬組和其他人擁有隻讀權限。
755:這是文件的執行權限和目錄的基本權限,代表所有者擁有讀,寫和執行權限,而所屬組和其他人擁有讀和執行權限。
777:這時最大權限。在實際的生產服務器中,要儘力避免給文件或目錄賦予這樣的權限,這會造成一定的安全隱患。
首先,讀,寫,執行權限對文件和目錄的作用是不同的。
權限對文件的作用
讀(r):對文件有讀(r)權限,代表可以讀取文件中的數據。如果把權限對應到命令上,那麼一旦對文件有讀(r)權限,就可以對文件執行cat,more,less,head,tail等文件查看命令。
寫(w):對文件有寫(w)權限,代表可以修改文件中的數據。如果把權限對應到命令上,那麼一旦對文件有寫(w)權限,就可以對文件執行vim,echo等修改文件數據的命令。注意:對文件有寫權限,是不能刪除文件本身的,只能修改文件中的數據。如果要想刪除文件,則需要對文件的上級目錄擁有寫權限。
執行(x):對文件有執行(x)權限,代表文件擁有了執行權限,可以運行。在Linux中,只要文件有執行(x)權限,這個文件就是執行文件了。只是這個文件到底能不能正確執行,不僅需要執行(x)權限,還要看文件中代碼是不是正確的語言代碼。文件夾來說,執行(x)權限是最高權限。
權限對目錄的作用
讀(r):對目錄有讀(r)權限,代表可以查看目錄下的內容,也就是可以查看目錄下有哪些子文件和子目錄。如果把權限對應到命令上,那麼一旦對目錄擁有了讀(r)權限,就可以在目錄下執行ls命令,查看目錄下的內容
寫(w):對目錄有寫(r)權限,代表可以修改目錄下的數據,也就是可以在目錄中新建,刪除,複製,剪切子文件或子目錄。如果把權限對應到命令上,那麼一旦目錄擁有了寫(w)權限,就可以在目錄下執行touch,rm,cp,mv命令。對目錄來說寫(w)權限是最高權限。
執行(x):目錄是不能運行的,那麼對目錄擁有執行(x)權限,代表可以進入到目錄。如果把權限對應到命令上,那麼一旦對目錄擁有了執行(x)權限,就可以對目錄執行cd命令,進入目錄。
目錄的可用權限其實有以下幾個
0:任何權限都不賦予
5:基本的目錄瀏覽和進入權限
7:完全權限
修改權限的命令 chown ,基本信息如下
[root@es ~]#chown [選項] 所有者:所屬組 文件或目錄
選項:
-R : 遞歸設置權限,也就是給子目錄中的所有文件設定權限
普通用戶不能修改文件的所有者,哪怕自己是這個文件的所有者也不行,只有超級用戶才能修改
普通用戶可以修改所有者是自己的文件的權限=
#用八進制數值显示umask權限
[root@centos7 ~]# umask
0022
#用字母表示文件和目錄的初始權限
[root@centos7 ~]# umask -S
u=rwx,g=rx,o=rx
我們需要先了解一下新建文件和目錄的默認最大權限
對文件來講,新建文件的默認最大權限是666,沒有執行(x)權限。這時因為執行權限對文件來講比較危險,不能在新建文件的時候默認賦予,而必須通過用戶手工賦予。
文件的默認權限最大隻能是666,而umask的值是022
“-rw-rw-rw-“減去”—–w–w-” 等於”-rw-r–r–“
對目錄來講,新建文件的默認最大權限是777。這時因為對目錄而言,執行(x)權限僅僅代表進入目錄,所以即使建立新文件時直接默認賦予,也沒有什麼危險。
目錄的權人權限最大隻能是777,而umask的值是022
“drwxrwxrwx” 減去 “d—-w–w-” 等於 “drwx-r-xr-x”
如果文檔對你有幫助的話,留個贊再走吧 ,你的點擊是我的最大動力。
我是鍵盤俠,現實中我唯唯諾諾,網絡上我重拳出擊,關注我,持續更新Linux乾貨教程。
更多鍵盤俠Linux系列教程:鏈接地址
更多Linux乾貨教程請掃:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※教你寫出一流的銷售文案?
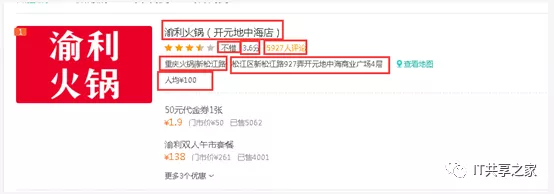
最近有個小夥伴在群里問美團數據怎麼獲取,而且她只要火鍋數據,她在上海,只要求抓上海美團火鍋的數據,而且要求也不高,只要100條,想做個簡單的分析,相關的字段如下圖所示。
乍一看,這個問題還真的是蠻難的,畢竟美團也不是那麼好抓,什麼驗證碼,模擬登陸等一大堆拂面而來,嚇得小夥伴都倒地了。
通過F12查看,抓包,分析URL,找規律,等等操作。
不過白慌,今天小編給大家介紹一個小技巧,另闢蹊徑去搞定美團的數據,這裏需要用到抓包工具Fiddler。講道理,之前我開始接觸網絡爬蟲的時候也沒有聽過這個東東,後來就慢慢知道了,而且它真的蠻實用的,建議大家都能學會用它。這個工具專門用於抓包,而且其安裝包也非常小,如下圖所示。
接下來,我們開始進行抓取信息。
1、在Fiddler的左側找到meituan網站的鏈接,如下圖所示。鏈接的左邊返回的response(響應)的文件類型,可以看到是JSON文件,爾後雙擊這一行鏈接。
2、此時在右側會显示下圖的界面,點擊黃色區域內的那串英文“Responsebody is encoded. Click to decode.”意思是response是加密的,點擊此處進行解碼,對返回的網頁進行解碼。
3、此時會彈出下圖所示的界面,在WebView中可以看到返回的數據,與網頁中的內容對應一致。
4、不過美團網限制一頁最多显示32條火鍋信息,如下圖所示。
5、如果我想獲取100條信息的話,那得前後找4頁,才能夠滿足要求。有沒有辦法讓其一次性多显示一些數據呢?答案是可以的,操作方法如下。
在左側找到對應的美團網鏈接,然後點擊右鍵一次選擇CopyàJustUrl,如下圖所示。
7、將得到的URL放到瀏覽器中去進行訪問,如下圖所示。可以看到limit=32,即代表可以獲取到32條相關的火鍋信息,並且返回的內容和Fiddler抓包工具返回的信息是一致的。
8、此時,我們直接在瀏覽器中將limit=32這個參數改為limit=100,也就是說將32更改為100,讓其一次性返回100條火鍋數據,天助我也,竟然可以一次性訪問到,如下圖所示。就這樣,輕輕鬆松的拿到了一百條數據。
9、接下來,可以將瀏覽器返回的數據進行Ctrl+A全部選中,放到一個本地文件中去,存為txt格式,在sublime中打開,如下圖所示。
10、其實乍一看覺得很亂,其實它就是一個JSON文件,剩下的工作就是對這個JSON文件做字符串的提取,寫個代碼,提取我們的目標信息,包括店門、星級、評論數、關鍵詞、地址、人均消費等,如下圖所示。
11、運行程序之後,我們會得到一個txt文件,列與列之間以製表符分開,如下圖所示。
12、在txt文件中看上去很是費勁,將其導入到Excel文件中去,就清晰多了,如下圖所示。接下來就可以很方便的對數據做分析什麼的了。
13、至此,抓取美團火鍋數據的簡易方法就介紹到這裏了,希望小夥伴們都可以學會,以後抓取類似的數據就不用找他人幫你寫程序啦~~
14、關於本文涉及的部分代碼,小編已經上傳到github了,後台回復【美團火鍋】四個字即可獲取。
看完本文有收穫?請轉發分享給更多的人
IT共享之家
入群請在微信後台回復【入群】
想學習更多Python網絡爬蟲與數據挖掘知識,可前往專業網站:http://pdcfighting.com/
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※想知道最厲害的網頁設計公司"嚨底家"!
※別再煩惱如何寫文案,掌握八大原則!
※產品缺大量曝光嗎?你需要的是一流包裝設計!
1 def loadTestsFromTestCase(self, testCaseClass) #看名稱分析:從TestCase找測試集--那麼就是把我們的def用例加載到testSuit裏面 2 def loadTestsFromModule(self, module, *args, pattern=None, **kws) #看名稱分析:從模塊裏面找測試集,那麼 模塊>類>test_方法>添加到testSuit裏面 3 def loadTestsFromName(self, name, module=None) #看名稱分析: 接收到name直接添加到testSuit裏面 4 def loadTestsFromNames(self, names, module=None) #看名稱分析:接受到的是一個包含測試test_方法的列表 5 def getTestCaseNames(self, testCaseClass) # 看名稱分析: 取出一個包含test_方法的列表 6 def discover(self, start_dir, pattern='test*.py', top_level_dir=None) ## 看名稱分析:發現--找test_方法 7 def _get_directory_containing_module(self, module_name) #獲取目錄包含的模塊 8 def _get_name_from_path(self, path) #從路徑從找名稱 9 def _get_module_from_name(self, name) #從名稱找模塊 10 def _match_path(self, path, full_path, pattern) #正則匹配路徑--參數包含pattern 那估計是匹配我們測試腳本格式的 11 def _find_tests(self, start_dir, pattern, namespace=False) #找測試集合 12 def _find_test_path(self, full_path, pattern, namespace=False) #找測試集合的路徑
View Code
1 那就是1234 2 一個discover,getTest,_match_path 3 二個find 4 三個_get 5 四個loadTests 6 7 discover 邏輯 8 > 9 _find_tests【兩個處理邏輯 一個是本次傳的目錄和上次傳的一樣或不一樣,】 10 【一樣:直接從我們傳的目錄下面繼續去找testcaose---】 11 【不一樣:會從我們傳的目錄下面去執行os.path.listdir找到所有的子文件列表paths(文件)),然後遍歷得到單獨的path做 start_dir+path拼接】 12 > 13 ①—get_name_from_path【傳入start_dir,判斷當前傳入的目錄是否為上次傳入的頂級目錄返回".",不一樣可能有點繞-並返回一個值這個值有四種情況 . test ...test dir.tests--正常應該是返回test文件名 14 ②_find_test_path(self, full_path, pattern, namespace=False) 15 【執行這個從路徑中找test,那麼很明顯 一樣:傳目錄路徑 不一樣傳文件路徑 】 16 _find_test_path
View Code
1 class TestLoader(object): 2 """ 3 This class is responsible for loading tests according to various criteria 4 and returning them wrapped in a TestSuite 5 """ 6 testMethodPrefix = 'test' 7 sortTestMethodsUsing = staticmethod(util.three_way_cmp) 8 suiteClass = suite.TestSuite 9 _top_level_dir = None 10 11 def __init__(self): 12 super(TestLoader, self).__init__() 13 self.errors = [] 14 # Tracks packages which we have called into via load_tests, to 15 # avoid infinite re-entrancy. 16 self._loading_packages = set() #這裏創建了一個空的self._loading_packages={}無序且不重複的元素集合
View Code 1.discover方法:unittest.defaultTestLoader a.定義了三個布爾值屬性 is_not_importable==True則是不能導入,is_namespace ,set_implicit_top b.對頂層目錄做了處理–當服務首次啟動 執行unittest.defaultTestLoader.discover(“文件目錄A”,pattern,top_level_dir=None):self._top_level_dir = top_level_dir = start_dir 這三個相等。 再次執行unittest.defaultTestLoader.discover(“文件目錄B”,pattern,top_level_dir=None): top_level_dir=self._top_level_dir【也就是他會默認上次start_dir 為頂層目錄】– 無論是首次還是複次–上面的操作完成之後 self._top_level_dir = top_level_dir 仍然繼續執行了一句這個—也就是說 self._top_level_dir == top_level_dir 始終一樣 c.針對頂層目錄不是一個目錄文件做了一系列的處理如果你傳的目錄是一個可導入的模塊-他在這個異常處理中.會重新自導入這個模塊。並開始追尋他的絕對路徑,判斷其模塊的可用性,然後執行_find_tests()尋找用例 d.如果是一個目錄就直接開始執行_find_tests()尋找用例 e.所以他這裏分兩種情況可以找到用例 第一種:傳的目錄 第二種:傳入的可導入模塊-這種情況self._top_level_dir 最終也是一個絕對路徑
1 def discover(self, start_dir, pattern='test*.py', top_level_dir=None): #一般我們top_level_dir傳的都None 2 set_implicit_top = False #是否存在頂層目錄 3 if top_level_dir is None and self._top_level_dir is not None: 4 # make top_level_dir optional if called from load_tests in a package 5 top_level_dir = self._top_level_dir #複次走這裏 6 elif top_level_dir is None: #初次走這裏 7 set_implicit_top = True 8 top_level_dir = start_dir 9 #上面這一串花里胡哨的東西就是處理頂層目錄-如果是第一次啟動服務- 10 #就走elif-top_level_dir==我們下面傳的值--之後--self._top_level_dir就不為空了, 11 #但是top_level_dir 頂部是處理==None所以會走if=True 12 top_level_dir = os.path.abspath(top_level_dir)#轉絕對路徑 13 if not top_level_dir in sys.path: 14 #這裡是防止重複將top_level_dir加入執行目錄--BUT如果我第一次傳的start_dir=a,第二次傳的start_dir=b 15 #分析一下--第一次就是把a加入到了執行目錄---下面self._top_level_dir=a 二次(複次)傳b的時候,會出現top_level_dir=a---並沒有判斷b是否在執行目錄 16 #這裏加一波問號????????????????????? 17 #但是一般情況 我們目錄就只有一個--所以這裏--先放着。。。先看後面再來看這裏 18 # all test modules must be importable from the top level directory 19 # should we *unconditionally* put the start directory in first 20 # in sys.path to minimise likelihood of conflicts between installed 21 # modules and development versions? 22 sys.path.insert(0, top_level_dir) 23 self._top_level_dir = top_level_dir 24 #如果top_level_dir我們傳的目錄不在可執行目錄--則臨時添加進去 25 is_not_importable = False #是否 不能導入 26 is_namespace = False #is_namespace那麼這個字段的意思就是是否可以找到傳入的路徑 27 tests = [] 28 if os.path.isdir(os.path.abspath(start_dir)): #判斷我們傳的是否為一個目錄--實際上這裏直接用top_level_dir不香嗎-- 29 start_dir = os.path.abspath(start_dir) 30 # 之前把top_level_dir = start_dir 31 # 然後top_level_dir = os.path.abspath(top_level_dir) 32 #現在start_dir = os.path.abspath(start_dir) 33 #為什麼不 直接用top_level_dir? 小朋友你是否有許多問號 34 # 問題出在上面--複次的時候--並沒有走 top_level_dir = start_dir 而是走的 top_level_dir = self._top_level_dir , 35 #所以如果我們上次傳的路徑如果和這次不一樣--那麼top_level_dir是不等於start_dir--而start_dir才是我們傳的-- 36 if start_dir != top_level_dir: #所以這裏相當於判斷前後傳的路徑是否一樣--一般來說我們的start_dir都是等於top_level_dir的 37 is_not_importable = not os.path.isfile(os.path.join(start_dir, '__init__.py'))#如果是一個文件返回false 38 #如果不一樣--則判斷我們當前傳入的start_dir/__init__.py是不是一個正確的文件路徑..os.path.isfile() 返回布爾值 39 else: #如果我們傳入的不是一個目錄,就開始一堆花里胡哨的報錯東西了。。暫時不用管 40 # support for discovery from dotted module names 41 try: 42 __import__(start_dir) 43 #這裏就很有意思了---__impor__("PyFiles.Besettest")那就是導入PyFiles 44 #那麼也就是說這個97.33的概率會報錯--也就是說你如果目錄錯了--下面的else基本不會走。。。除非你很神奇的填的路徑右側是一個可導入的模塊 45 except ImportError: 46 is_not_importable = True #如果導入不鳥--就is_not_importable設置為true 在這裏我清楚了這個字段的含義--不能導入=true 47 else:#那麼這裏假設導入成功之後 48 the_module = sys.modules[start_dir] #這裡是如果我們導入成功--就走這裏-取出start_dir導入的賦值給the_module 49 top_part = start_dir.split('.')[0] #這裡是將我們導入的模塊名稱取出來 50 try: 51 start_dir = os.path.abspath( #打印導入模塊所在目錄的絕對路徑 52 os.path.dirname((the_module.__file__))) 53 except AttributeError: #這裡是如果導入模塊成功了---但是尼瑪打印導入模塊的絕對路徑又報錯--不想看了+2 54 # look for namespace packages 55 try: #然後有開始進行模塊導入檢查---日了狗了。。。。。 56 # fuck----想直接關機了+1,這裏估計是想找到為什麼不能導入的原因。。大神的思路就是完美,如果是我就拋出一個目錄不對就完事 57 #這一塊的學習 文檔 Python標準模塊--import 58 spec = the_module.__spec__ 59 #將導入成功的模塊的規格說明賦值給spec-- 60 #打印出來就是ModuleSpec(name='besettest.interface', loader=<_frozen_importlib_external.SourceFileLoader object at 0x0000000003D6E780>, origin='E:\\PyFiles\\Besettest\\besettest\\interface\\__init__.py', submodule_search_locations=['E:\\PyFiles\\Besettest\\besettest\\interface']) 61 #這麼一串東西--也沒用過。。。。大概就是模塊名稱、路徑、導入的模塊對象吧 62 #origin 加載模塊的位置-- 63 #loader_state模塊特定數據的容器 64 except AttributeError: #如果模塊的規格說明取不出來。。。。。。。 65 spec = None #我查閱了一下。。。的確存在部分模塊規格說明為None的--所以還得繼續往下看 66 67 if spec and spec.loader is None: #如果存在規格說明 且 數據容器為None。 68 if spec.submodule_search_locations is not None: 69 #這是個什麼玩意呢--模塊 搜索 位置s(列表)。。。 70 is_namespace = True #如果spec.submodule_search_locations不為none ----- 71 # 2.5級英文翻譯 就是模塊的路徑 如果模塊路徑不為空is_namespace可以找到---is_namespace那麼這個字段的意思就是存在命名空間。。就是可以找到這個模塊 72 for path in the_module.__path__: #這裏我研究懷疑是故意提升逼格。。the_module.__path__==spec.submodule_search_locations 73 if (not set_implicit_top and #首次set_implicit_top==True 複次set_implicit_top==Fase 74 not path.startswith(top_level_dir)): 75 continue 76 #這裏讓我稍微有點疑惑。。為什麼要判斷是首次還是複次--我猜是判斷the_module.__path__列表裡面有幾個某塊的路徑 77 #如果是首次直接下一步--如果是複次會有多個路徑。但是如果是複次top_level_dir這個路徑又是上次的。。。日 78 #他的作用是找到導入模塊的路徑-知道這個就行。。。 79 self._top_level_dir = \ 80 (path.split(the_module.__name__ 81 .replace(".", os.path.sep))[0]) #取出導入模塊的上級目錄絕對路徑。。。 82 #the_module.__name__.replace(".", os.path.sep) 這一串我看來是沒有必要的。。因為 the_module.__name__既然取到了模塊名稱那他肯定是一個字符串 83 tests.extend(self._find_tests(path, #然後調用_find_tests 尋找測試。加入tests列表--這個有點熟悉的味道--- 84 pattern, #我覺得基本不會走這裏去找---腳本路徑一般都會填對 填錯了,都不知道執行到哪裡去了。。。 85 namespace=True)) 86 elif the_module.__name__ in sys.builtin_module_names: 87 #判斷 sys.builtin_module_names返回一個列表,包含所有已經編譯到Python解釋器里的模塊的名字 和sys.models是一個字典 88 #就是沒法導入報錯 89 # builtin module 90 raise TypeError('Can not use builtin modules ' 91 'as dotted module names') from None 92 else: #沒發現這個模塊 93 raise TypeError( 94 'don\'t know how to discover from {!r}' 95 .format(the_module)) from None 96 97 if set_implicit_top: #如果是首次。。。。 98 if not is_namespace: #is_namespace默認的是false-且可以找到模塊相關規格 99 self._top_level_dir = \ 100 self._get_directory_containing_module(top_part) #interface.testFiles interface假設這個是導入的 -self._top_level_dir 是一個目錄的絕對路徑 101 #top_part導入的模塊名稱----- 102 sys.path.remove(top_level_dir) #只知道是從系統路徑移除--但是不知道為什麼移除。。。。 103 else: 104 sys.path.remove(top_level_dir) # 105 106 if is_not_importable: #如果我們傳的文件不能導入---就直接拋出異常 107 raise ImportError('Start directory is not importable: %r' % start_dir) 108 109 if not is_namespace: #is_namespace默認的是false--這裏就是可以找到模塊。。。。 110 tests = list(self._find_tests(start_dir, pattern)) 111 return self.suiteClass(tests)
View Code 2._find_tests()–尋找testCase並生成測試套件tests=[]
1 def _find_tests(self, start_dir, pattern, namespace=False): #注意這裏如果我們傳的不是腳本目錄而是一個可導入的模塊namespace是等於True的 2 """Used by discovery. Yields test suites it loads.""" 3 # Handle the __init__ in this package 4 name = self._get_name_from_path(start_dir) #返回一個name name存在三種返回情況 "."-當本次和上次傳入的start_dir一致 不一致 "文件名" "...文件名" 5 #get_name_from_path的邏輯在這裏就很清晰了 6 7 # name is '.' when start_dir == top_level_dir (and top_level_dir is by 8 # definition not a package). 9 if name != '.' and name not in self._loading_packages: 10 #當name最少有一個且也不再self._loading_packages.【self._loading_packages初始化的時候建的空集合】 走下面這個 11 # name is in self._loading_packages while we have called into 12 # loadTestsFromModule with name. 13 tests, should_recurse = self._find_test_path( #然後這裏start_dir是我們傳的模塊--他就去找。。這裏就恢復到了傳測試目錄的邏輯了 14 start_dir, pattern, namespace) 15 if tests is not None: 16 yield tests 17 if not should_recurse: 18 # Either an error occurred, or load_tests was used by the 19 # package. 20 return 21 # Handle the contents. 22 paths = sorted(os.listdir(start_dir)) #那就從這裏開始--當我們穿的目錄和上次一樣-他會找到目錄下所有的文件然後排序--我們的用例執行順序就是從這裏開始搞了。。 23 for path in paths: #遍歷我們傳的目錄下的所有文件 24 full_path = os.path.join(start_dir, path) 將我們傳入的目錄和目錄下的py文件拼接的完整路徑 25 tests, should_recurse = self._find_test_path( #把我們文件路徑和我們的文件格式傳入_find_test_path這個方法-- 26 full_path, pattern, namespace) 27 如果當前傳的是一個目錄-會返回should_recurse=True--這個英文直譯是應該_遞歸--下面yield from 就是執行遞歸的操作 28 if tests is not None: 29 yield tests 30 if should_recurse: #這句是判斷他是不是一個目錄 31 # we found a package that didn't use load_tests. 32 name = self._get_name_from_path(full_path) 33 self._loading_packages.add(name) 34 try: 35 yield from self._find_tests(full_path, pattern, namespace) 36 finally: 37 self._loading_packages.discard(name)
View Code yield與yield from
1 def a(n): 2 testList=b(n) 3 return testList 4 5 def b(n,m=1): 6 print("執行第%s次"%m) 7 for a in range(n): 8 if not divmod(a,2)[1] and a!=0: 9 print(a) 10 yield a #是用yield之後返回的是一個生成器 11 if divmod(a,3)[1]: 12 m =m+1 13 yield from b(a,m) #重新執行b方法 14 15 print(list(a(7))) 16 17 執行第1次 18 2 19 執行第2次 20 4 21 執行第3次 22 2 23 執行第4次 24 6 25 [2, 4, 2, 6]
View Code _get_name_from_path 他主要做了:從我們傳的路徑裏面找腳本文件 名。。。如果找到了腳本文件則返迴文件名稱—如果沒找到也就是我們返回一個點 或者 至少一個點(三種情況 . test_case …..test_case 返回name可能存在的三種值) 在_test_find調用這個方法path=start_dir(我們傳的目錄)–這個返回一個點 或者 至少一個點 在 _fin_test_path調用這個方法是傳的我們傳的目錄下的文件路口–返回的name就是文件名
1 name = self._get_name_from_path(start_dir) #因為discover我們是支持我們傳目錄或者模塊尋找testcase的,所以這個方法 2 3 def _get_name_from_path(self, path): 4 #主要正確邏輯三個 比如我們的腳本目錄結構是 E://a/b/ b目錄下面有script.py 和 /c/script.py 5 #第一次是我們自己傳的目錄--之前在discover他做了一個處理 就是第一次運行時會把我們傳的目錄賦值給頂層目錄--- 6 #第一個邏輯判斷我們傳的是不是 -和頂層一樣---一樣的話===_find_tests方法就直接從目錄下面找腳本-當如如果有目錄也會繼續走--他是在_find_tests_path判斷的--最終也是回到找腳本模塊上 7 #如果不一樣--那就是找了 找到這個目錄了---那麼就從頂層開始找這個目錄的相對路徑--其實就是找最後那個目錄(必須是一個packge。上面說的目錄都是包)、。。然後返回一個name 8 #如果還有子目錄 d---那就會返回 c.d 9 if path == self._top_level_dir: #首次運行pattern,top_level_dir=None):self._top_level_dir = top_level_dir = start_dir -第二次運行如果目錄沒有變,這裏也是直接返回的 10 return '.' 11 12 13 path = _jython_aware_splitext(os.path.normpath(path)) #如果我們當前傳的和上次傳的目錄不一致。。這裏得path我們當前傳的路徑 14 15 _relpath = os.path.relpath(path, self._top_level_dir) #從self._top_level_dir開始找path的相對路徑 16 #這裡是從我們傳的path開始找到self._top_level_dir上次傳的相對路徑 17 #例如: path=path1="E:\\PyFiles\\Besettest\\besettest\\interface\\testFiles" self._top_level_dir="E:\\PyFiles\\Besettest\\besettest\\interface\\result" 18 #那麼_relpath="..\testFiles" -暫時還不清楚為什麼要找這個?????????????????????????? 19 assert not os.path.isabs(_relpath), "Path must be within the project" 20 #↑↑斷言 不是絕對路徑-也就是說_relpath是否為相對路徑↑↑↑特么的 這裏肯定是一個相對路徑啊。。。上面都有relpath了。。。丟 21 #↓↓↓↓斷言以..開頭就失敗。。。↓↓↓--這兩處超出理解範圍了。。。。。。 22 assert not _relpath.startswith('..'), "Path must be within the project" 23 24 name = _relpath.replace(os.path.sep, '.') #然後這裏又把分隔符替換成. 返回 a.b 當然或許會有異常情況返回.....這是我意淫的 25 return name
View Code self._find_test_path #找測試的路徑 兩個主要邏輯: 傳到full_path 是一個文件 還是一個目錄
1 def _find_test_path(self, full_path, pattern, namespace=False): 2 #_find_tests()調用這個方法 傳了一個我們傳的目錄下的a文件路徑、和需要找的文件pattern-namespace【傳的可能是true 也可能是false】,如果我的目錄是對的-namespace傳的就是false 3 """Used by discovery. 4 5 Loads tests from a single file, or a directories' __init__.py when 6 passed the directory. 7 8 Returns a tuple (None_or_tests_from_file, should_recurse). 9 """ 10 basename = os.path.basename(full_path) #basename==文件名.py後續帶py的統稱文件--不帶後綴的統稱文件名。。。 11 if os.path.isfile(full_path): #如果我們傳的full_path是一個文件---我們在discover傳的是一個腳本目錄-之前在_test_find是做了一個拼接得到的完整路徑full_path 12 if not VALID_MODULE_NAME.match(basename): #判斷他是不是一個py文件---- 13 14 # valid Python identifiers only 15 return None, False #如果不是直接返回 16 if not self._match_path(basename, full_path, pattern): #這裏雖然傳了三個值--但是實際上只有basename,pattern有用-- 17 #_match_path調用fnmatch(文件, 我們傳的文件格式或文件)這個需要————from fnmatch import fnmatch他的主要作用是做此模塊的主要作用是文件名稱的匹配 18 #當此次傳入的文件名與我們的文件格式匹配一致self._match_path返回true 19 return None, False #如果不一樣 就直接回到 _find_test繼續找 20 # if the test file matches, load it 21 name = self._get_name_from_path(full_path) #然後這裏把文件路徑又傳到 self._get_name_from_path去返迴文件名-這個時候因為我們傳的是腳本目錄-full_path目錄下的文件路徑,所以返回的name 就是文件名 22 23 #self._top_level_dir是當前文件目錄路徑,path是當前文件路徑--從目錄找文件--直接就是文件名--他返回的name就是文件名 24 try: 25 module = self._get_module_from_name(name) #_get_module_from_name 這個方法就是動態導入模塊名--然後返回一個所有導入的模塊的對象 moudel.__file__路徑、moudel.__name__名稱 26 except case.SkipTest as e: #如果導入不成功 case.SkipTest 實際上case是繼承--Exception--所以把這個理解為Exception就可以了-- 27 return _make_skipped_test(name, e, self.suiteClass), False 28 except: 29 error_case, error_message = \ 30 _make_failed_import_test(name, self.suiteClass) 31 self.errors.append(error_message) 32 return error_case, False 33 else: #module 獲取到值之後走這裏。。 34 mod_file = os.path.abspath( 35 getattr(module, '__file__', full_path)) #然後這裏取出我們導入模塊的 絕對路徑---如果反射找不到就返回該文件的路徑-其實差別不大-處理一下更嚴謹 36 realpath = _jython_aware_splitext( 37 os.path.realpath(mod_file)) #os.path.realpath(mod_file)然後又返回真實路徑---然後又去掉路徑的.py,。,,,,,,,,丟 38 fullpath_noext = _jython_aware_splitext( 39 os.path.realpath(full_path)) #然後full_path 找真實路徑去掉.py 40 if realpath.lower() != fullpath_noext.lower(): #如果動態導入的模塊的目錄路徑 不等於 傳進來(也就是pattern)的目錄路徑--實際上傳進來的路徑肯定是個絕對路徑--因為前面已經轉了好幾次絕對路徑了 41 module_dir = os.path.dirname(realpath) #不等於就找動態導入模塊所在的目錄----實際上上面處理的realpath已經是一個目錄了。。但是他防止realpath還是一個.py文件。所以又操作了一次 42 mod_name = _jython_aware_splitext( #full_path是文件的路徑.py的,然後這裏又先是basename取出文件(就是把路徑去掉,只留下xxx.py) 然後外面那個方法 把.py去掉--留下文件名 43 os.path.basename(full_path)) 44 expected_dir = os.path.dirname(full_path) 45 #然後找到需要執行腳本所在的目錄。。。。。也就是說正常情況 假設expected_dir="e://a/b" 那麼 mod_file =realpathfullpath_noext="e://a/b/scripy" 46 #scripy是一個py文件---上面這個if是說的 正常情況。。。我想不到導入模塊和導入模塊的路徑不相等的情況--不過這個不重要-源碼這樣肯定是有道理的 47 msg = ("%r module incorrectly imported from %r. Expected " 48 "%r. Is this module globally installed?") 49 raise ImportError( 50 msg % (mod_name, module_dir, expected_dir)) 51 return self.loadTestsFromModule(module, pattern=pattern), False 52 #然後走 從模塊從加載測試s 這個方法---也就是說discover實際上是調用loadTestsFromMould這個方法的。。測試套件也是在這一步處理的 53 elif os.path.isdir(full_path): #dicover裏面傳腳本目錄是走這裏。。 54 if (not namespace and #namespace-默認是false not namespace就是true 55 not os.path.isfile(os.path.join(full_path, '__init__.py'))): #不是一個包。。-也就是說我們傳的目錄應該是一個包,下面包含__init__.py 56 return None, False 57 58 load_tests = None #這個load_tests是啥意思呢??????????後面繼續看----看了一遍--並且用unittest.main()試了一下-模塊下面是沒有這個屬性的。。只是unittest的初始化文件有這個方法--他也是通過discover找的。。 59 tests = None 60 name = self._get_name_from_path(full_path) #這裏就是走子目錄的邏輯了 61 #get_name_from_path的邏輯在這裏就很清晰了 62 #A.如果通過_find_test 調用self._get_name_from_path 是為了判斷兩次start_dir是否一致一致返回. 不一致返回從上次的start_dir1找到本次start_dir12的相對路徑-- 63 #這裏又分兩種情況-A1正常情況-start_dir1是start_dir12的上級目錄。。。那麼返回的那麼就是-A.B這樣的了。。因為第一次的A是已經os.path.insert到環境變量了..所以A.B是可以直接用 64 #A2不正常情況 就是之前說的 最少返回一個點的...A這種返回---然後問題來了--他為什麼要這麼處理呢--原因是????????? 65 #我猜是與腳本同級存在另一個腳本目錄。。。後面驗證這一點。-----這裡在上面補充了--是因為子目錄中還存在腳本所有這麼走邏輯-完美的 66 try: 67 package = self._get_module_from_name(name) #上面是導入的一個module--這裡是導入一個包-- 返回-- 68 except case.SkipTest as e: 69 return _make_skipped_test(name, e, self.suiteClass), False 70 except: 71 error_case, error_message = \ 72 _make_failed_import_test(name, self.suiteClass) 73 self.errors.append(error_message) 74 return error_case, False 75 else: 76 load_tests = getattr(package, 'load_tests', None) #然後判斷這個包裏面有沒有'load_tests'這個屬性---這裏我代碼一直看下來,我們是不知道這個lood_tests是什麼的,字面意思 加載測試集合 77 # Mark this package as being in load_tests (possibly ;)) 78 self._loading_packages.add(name) #然後把模塊名稱添加到set集合 79 try: 80 tests = self.loadTestsFromModule(package, pattern=pattern) 81 #這裏傳了一個package模塊對象,和文件匹配規則合作或者文件。。--但是這裏導入一個包之後實際上是找不到testCase的-因為包下面的屬性肯定不是一個類-不會走loadTestsFromTestCase 82 #所以這裏返回的tests是一個空列表 83 if load_tests is not None: #貌似這個是棄用的,向後兼容-暫時沒看明白這個load_tests代表的意思 84 # loadTestsFromModule(package) has loaded tests for us. 85 return tests, False 86 return tests, True # 如果能走到這裏------就返回True_就是給_find_test判斷走遞歸的--_find_tests裏面就得到 should_recurse=True 87 finally: 88 self._loading_packages.discard(name) #然後這個刪掉set集合裏面之前導入的那個包 89 else: 90 return None, False
View Code
1 def loadTestsFromModule(self, module, *args, pattern=None, **kws): 2 """Return a suite of all test cases contained in the given module""" 3 # This method used to take an undocumented and unofficial 4 # use_load_tests argument. For backward compatibility, we still 5 # accept the argument (which can also be the first position) but we 6 # ignore it and issue a deprecation warning if it's present. 7 if len(args) > 0 or 'use_load_tests' in kws: #args這個默認是一個空元組 長度默認為0 kws是一個空字典 8 warnings.warn('use_load_tests is deprecated and ignored', 9 DeprecationWarning) 10 kws.pop('use_load_tests', None) 11 if len(args) > 1: 12 # Complain about the number of arguments, but don't forget the 13 # required `module` argument. 14 complaint = len(args) + 1 15 raise TypeError('loadTestsFromModule() takes 1 positional argument but {} were given'.format(complaint)) 16 if len(kws) != 0: 17 # Since the keyword arguments are unsorted (see PEP 468), just 18 # pick the alphabetically sorted first argument to complain about, 19 # if multiple were given. At least the error message will be 20 # predictable. 21 complaint = sorted(kws)[0] #取出第一個Key- 22 raise TypeError("loadTestsFromModule() got an unexpected keyword argument '{}'".format(complaint)) 23 tests = [] 24 for name in dir(module): #這裏得modul實際上使我們傳入的模塊對象---dir(object) 返回模塊下的所有屬性列表- 25 obj = getattr(module, name) #然後反射返回name對象。。返回的是一個class對象 26 if isinstance(obj, type) and issubclass(obj, case.TestCase): #這裏判斷obj是否是一個類--並且這個類是case.TestCase的子類,也就是說 是否寫在我們繼承unitest.testCase那個類的下面 27 tests.append(self.loadTestsFromTestCase(obj)) #可以看到最後走loadTestFromTestCase obj這裡是傳入的一個類名 28 29 load_tests = getattr(module, 'load_tests', None) 30 tests = self.suiteClass(tests) 31 if load_tests is not None: 32 try: 33 return load_tests(self, tests, pattern) 34 except Exception as e: 35 error_case, error_message = _make_failed_load_tests( 36 module.__name__, e, self.suiteClass) 37 self.errors.append(error_message) 38 return error_case 39 return tests #返回集合
View Code loadTestsFromTestCase:這裏就是添加testcase到suit集合裏面的主要邏輯
1 def loadTestsFromTestCase(self, testCaseClass): #testCaseClass是我們傳的一個用例類 2 """Return a suite of all test cases contained in testCaseClass""" 3 if issubclass(testCaseClass, suite.TestSuite): #這個類是不是suite.TestSuite的子類--如果是的就拋出異常== 4 raise TypeError("Test cases should not be derived from " 5 "TestSuite. Maybe you meant to derive from " 6 "TestCase?") 7 testCaseNames = self.getTestCaseNames(testCaseClass) #getTestCaseNames 從類下面找到用例名稱--找到名稱返回的是一個列表 8 if not testCaseNames and hasattr(testCaseClass, 'runTest'): #這裏判斷testCaseNames是否為空-並且 是否存在"runTest"這個元素 9 testCaseNames = ['runTest'] 10 loaded_suite = self.suiteClass(map(testCaseClass, testCaseNames)) #是我的一個用例類--然後將testCaseNames類下面的測試方法--帶進去遍歷。。。高級用法---第一次見--這個方法很關鍵 11 return loaded_suite
View Code getTestCaseNames
1 def getTestCaseNames(self, testCaseClass): 2 """Return a sorted sequence of method names found within testCaseClass 3 """ 4 def isTestMethod(attrname, testCaseClass=testCaseClass, #定義一個內部方法 5 prefix=self.testMethodPrefix): #self.testMethodPrefix="test" 這個在TestLoader下第一行就已經默認了,他是我們用例開頭的固定格式 6 return attrname.startswith(prefix) and \ #這裏判斷了是否已test開頭以及 方法對象是否可用----getattr返回方法對象--callable()是檢測對象是否可用 返回一個布爾值 7 callable(getattr(testCaseClass, attrname)) 8 testFnNames = list(filter(isTestMethod, dir(testCaseClass))) 9 #dir(testCaseClass)返回該對象下面所有的屬性--包括變量test_1--所以上面需要檢測屬性時test開頭且是一個可以調用的對象-- 10 #filter函數---前面是一個function -後面是一個可迭代對象-會遍歷可迭代對象-並傳入function-functions返回true則添加到列表--這樣就找到了所有的 11 if self.sortTestMethodsUsing: 12 testFnNames.sort(key=functools.cmp_to_key(self.sortTestMethodsUsing)) 13 #sortTestMethodsUsing = staticmethod(util.three_way_cmp) 轉為為靜態方法-內存地址指向self.sortTestMethodsUsing 14 #然後通過functools這個模塊排序== 15 return testFnNames #然後返回用例方法名稱列表
View Code 所有的邏輯 就是在TestLoader找測試用例的時候–通過_find_tests這個方法從目錄開始找文件(子目錄)-模塊-類-方法名 然後將某個模塊下的類通過他下面的方法map返回多個對象,也就是說一個testClass下面存在五個test_method,他就會返回五個實例對象-並生成一個suite集合–然後加入到一個列表 如果一個模塊下有多個testClasee 同樣-實際上是一樣的–實際上他是先通過loadTestsFromModule這個方法找到所有的類對象之後在遍歷–然後才走上面那一步的,,,多個testClasss就存在多個suite集合– 也就是說 一個modul下面的 suite集合會添加到一個列表–[suite=[A-TestCase實例化對象1,A-TestCase實例化對象2],suite=[B-TestCase實例化對象1,B-TestCase實例化對象2]]—然後在將這個列表當做參數傳入TestSuite實例化一個新對象[suite=-[suite=[A-TestCase實例化對象1,A-TestCase實例化對象2],suite=[B-TestCase實例化對象1,B-TestCase實例化對象2]]]—-這樣就是一個模塊下用的結構 但是還沒有完–這裏只是一個modul下的—還有多個modul–到了大家估計也知道剩下的會幹什麼了— 沒錯–當我得到modul的全部suite集合之後—這個集合最終會返回給_find_tests方法–通過生成器返回給discover–也就是將這個suite集合又加入到了一個新的列表–然後discover又將這個list 帶入形成了一個—–最終的實例對象,最終返回的格式如下——- [suite= [suite1=-[suite=[A-TestCase實例化對象1,A-TestCase實例化對象2],suite=[B-TestCase實例化對象1,B-TestCase實例化對象2]]], [suite2=-[suite=[A-TestCase實例化對象1,A-TestCase實例化對象2],suite=[B-TestCase實例化對象1,B-TestCase實例化對象2]]] ] –看過源碼的都知道—我們run的時候—就這個實例對象是可以接受參數的–而這個參數就是result—因為TestSuite繼承的BaseTestsSuite 有一個__call__這個
魔術方法:如果在類中實現了 __call__ 方法,那麼實例對象也將成為一個可調用對象,具體百度。這裏不做過多解釋—–所以最終的suite是可以接受參數的test(result)–接受參數之後直接走——call下面的邏輯了 本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※教你寫出一流的銷售文案?
※超省錢租車方案
※FB行銷專家,教你從零開始的技巧
Optional 類(java.util.Optional) 是一個容器類,代表一個值存在或不存在,原來用 null 表示一個值不存在,現在 Optional 可以更好的表達這個概念。並且可以避免空指針異常。
Optional.of(T t) : 創建一個 Optional 實例。
Optional.empty() : 創建一個空的 Optional 實例。
Optional.ofNullable(T t):若 t 不為 null,創建 Optional 實例,否則創建空實例。
isPresent() : 判斷是否包含值。
orElse(T t) : 如果調用對象包含值,返回該值,否則返回t。
orElseGet(Supplier s) :如果調用對象包含值,返回該值,否則返回 s 獲取的值。
orElseThrow(Supplier es) : 當遇到一個不存在的值的時候,並不返回一個默認值,而是拋出異常。
map(Function f): 如果有值對其處理,並返回處理后的Optional,否則返回 Optional.empty()。
flatMap(Function mapper):與 map 類似,要求返回值必須是Optional。
filter(Predicate p):接收一個函數式接口,當符合接口時,則返回一個Optional對象,否則返回一個空的Optional對象。
1 import org.junit.Test; 2 import java.util.Optional; 3 /* 4 * Optional 容器類:用於盡量避免空指針異常 5 * Optional.of(T t) : 創建一個 Optional 實例 6 * Optional.empty() : 創建一個空的 Optional 實例 7 * Optional.ofNullable(T t):若 t 不為 null,創建 Optional 實例,否則創建空實例 8 * isPresent() : 判斷是否包含值 9 * ifPresent(Consumer<? super T> consumer) 判斷是否包含值,再執行 consumer 10 * orElse(T t) : 如果調用對象包含值,返回該值,否則返回t 11 * orElseGet(Supplier s) :如果調用對象包含值,返回該值,否則返回 s 獲取的值 12 * orElseThrow(Supplier<? extends X> exceptionSupplier) : 當遇到一個不存在的值的時候,並不返回一個默認值,而是拋出異常 13 * map(Function f): 如果有值對其處理,並返回處理后的Optional,否則返回 Optional.empty() 14 * flatMap(Function mapper):與 map 類似,要求返回值必須是Optional 15 * filter(Predicate<? super T> predicate):接收一個函數式接口,當符合接口時,則返回一個Optional對象,否則返回一個空的Optional對象 16 * 17 * map、flatMap 和 filter 的使用方法和 StreamAPI 中的一樣 18 */ 19 public class TestOptional { 20 21 22 /** 23 * 創建 Optional 實例 24 */ 25 @Test 26 public void test1(){ 27 28 // Optional.empty() : 創建一個空的 Optional 實例 29 Optional<String> empty = Optional.empty(); 30 System.out.println(empty);// 輸出結果:Optional.empty 31 //System.out.println(empty.get());// 報錯:java.util.NoSuchElementException: No value present 32 33 // Optional.of(T t) : 創建一個 Optional 實例 34 Optional<Employee> eop = Optional.of(new Employee()); 35 System.out.println(eop);// 輸出結果:Optional[Employee{name='null', age=null, gender=null, salary=null, status=null}] 36 System.out.println(eop.get());//輸出結果:Employee{name='null', age=null, gender=null, salary=null, status=null} 37 38 //注意:Optional.of(T t) 中,傳遞給of()的值不可以為空,否則會拋出空指針異常 39 //Optional<Employee> eop1 = Optional.of(null);//這一行直接報錯:java.lang.NullPointerException 40 41 //Optional.ofNullable(T t):若 t 不為 null,創建 Optional 實例,否則創建空實例 42 //所以,在創建Optional對象時,如果傳入的參數不確定是否會為Null時,就可以使用 Optional.ofNullable(T t) 方式創建實例。 43 Optional<Object> op = Optional.ofNullable(null);//這樣的效果和 Optional.empty() 一樣 44 System.out.println(op);//Optional.empty 45 op = Optional.ofNullable(new Employee());// 46 System.out.println(op);//Optional[Employee{name='null', age=null, gender=null, salary=null, status=null}] 47 } 48 49 50 /** 51 * isPresent() : 判斷是否包含值 52 * ifPresent(Consumer<? super T> consumer) 判斷是否包含值,再執行 consumer 53 */ 54 @Test 55 public void test2(){ 56 Optional<Employee> opt = Optional.of(new Employee()); 57 System.out.println(opt.isPresent());//輸出結果:true 58 opt = Optional.ofNullable(null); 59 System.out.println(opt.isPresent());//輸出結果:false 60 opt.ifPresent(employee -> System.out.println(employee));// 如果 opt.isPresent() 為false ,這裏就不輸出,否則就輸出 employee 61 } 62 63 /** 64 * orElse(T t) : 如果調用對象包含值,返回該值,否則返回t 65 * orElseGet(Supplier s) :如果調用對象包含值,返回該值,否則返回 s 獲取的值 66 */ 67 @Test 68 public void test3(){ 69 //Optional<Employee> opt = Optional.of(new Employee()); 70 Optional<Employee> opt = Optional.ofNullable(null); 71 /*Employee emp = opt.orElse(new Employee("張三",20)); 72 System.out.println(emp);*/ 73 74 int condition = 2;//模擬條件 75 Employee emp = opt.orElseGet(()-> { 76 if (condition == 1){ 77 return new Employee("李四"); 78 }else if (condition == 2){ 79 return new Employee("王二麻子"); 80 }else { 81 return new Employee("趙六"); 82 } 83 }); 84 System.out.println(emp); 85 } 86 /** 87 * orElseThrow(Supplier<? extends X> exceptionSupplier) : 當遇到一個不存在的值的時候,並不返回一個默認值,而是拋出異常 88 */ 89 @Test 90 public void test4(){ 91 Object obj = Optional.ofNullable(null).orElseThrow(IllegalArgumentException::new);//當參數為null,則拋出一個不合法的參數異常 92 System.out.println(obj); 93 } 94 95 96 }
備註:map、flatMap 和 filter 的使用方法和 StreamAPI 中的一樣,如需了解詳細使用方法,請參考:Stream API 詳解
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?
※網頁設計最專業,超強功能平台可客製化