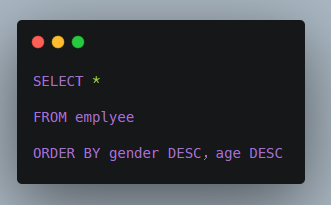
在開始之前,我先賣個關子提一個問題:我們現在有一個Employee員工類。
@Data
@AllArgsConstructor
public class Employee {
private Integer id;
private Integer age; //年齡
private String gender; //性別
private String firstName;
private String lastName;
}
你知道怎麼對一個Employee對象組成的List集合,先按照性別字段倒序排序,再按照年齡的倒序進行排序么?如果您不知道4行代碼以內的解決方案(其實是1行代碼就可以實現,但筆者格式化為4行),我覺得您有必要一步步的看下去。
一、字符串List排序
cities是一個字符串數組。注意london的首字母是小寫的。
List<String> cities = Arrays.asList(
"Milan",
"london",
"San Francisco",
"Tokyo",
"New Delhi"
);
System.out.println(cities);
//[Milan, london, San Francisco, Tokyo, New Delhi]
cities.sort(String.CASE_INSENSITIVE_ORDER);
System.out.println(cities);
//[london, Milan, New Delhi, San Francisco, Tokyo]
cities.sort(Comparator.naturalOrder());
System.out.println(cities);
//[Milan, New Delhi, San Francisco, Tokyo, london]
- 當使用sort方法,按照String.CASE_INSENSITIVE_ORDER(字母大小寫不敏感)的規則排序,結果是:[london, Milan, New Delhi, San Francisco, Tokyo]
- 如果使用Comparator.naturalOrder()字母自然順序排序,結果是:[Milan, New Delhi, San Francisco, Tokyo, london]
同樣我們可以把排序器Comparator用在Stream管道流中。
cities.stream().sorted(Comparator.naturalOrder()).forEach(System.out::println);
//Milan
//New Delhi
//San Francisco
//Tokyo
//london
在java 7我們是使用Collections.sort()接受一個數組參數,對數組進行排序。在java 8之後可以直接調用集合類的sort()方法進行排序。sort()方法的參數是一個比較器Comparator接口的實現類,Comparator接口的我們下一節再給大家介紹一下。
二、整數類型List排序
List<Integer> numbers = Arrays.asList(6, 2, 1, 4, 9);
System.out.println(numbers); //[6, 2, 1, 4, 9]
numbers.sort(Comparator.naturalOrder()); //自然排序
System.out.println(numbers); //[1, 2, 4, 6, 9]
numbers.sort(Comparator.reverseOrder()); //倒序排序
System.out.println(numbers); //[9, 6, 4, 2, 1]
三、按對象字段對List<Object>排序
這個功能就比較有意思了,舉個例子大家理解一下。
Employee e1 = new Employee(1,23,"M","Rick","Beethovan");
Employee e2 = new Employee(2,13,"F","Martina","Hengis");
Employee e3 = new Employee(3,43,"M","Ricky","Martin");
Employee e4 = new Employee(4,26,"M","Jon","Lowman");
Employee e5 = new Employee(5,19,"F","Cristine","Maria");
Employee e6 = new Employee(6,15,"M","David","Feezor");
Employee e7 = new Employee(7,68,"F","Melissa","Roy");
Employee e8 = new Employee(8,79,"M","Alex","Gussin");
Employee e9 = new Employee(9,15,"F","Neetu","Singh");
Employee e10 = new Employee(10,45,"M","Naveen","Jain");
List<Employee> employees = Arrays.asList(e1, e2, e3, e4, e5, e6, e7, e8, e9, e10);
employees.sort(Comparator.comparing(Employee::getAge));
employees.forEach(System.out::println);
- 首先,我們創建了10個Employee對象,然後將它們轉換為List
- 然後重點的的代碼:使用了函數應用Employee::getAge作為對象的排序字段,即使用員工的年齡作為排序字段
- 然後調用List的forEach方法將List排序結果打印出來,如下(當然我們重寫了Employee的toString方法,不然打印結果沒有意義):
Employee(id=2, age=13, gender=F, firstName=Martina, lastName=Hengis)
Employee(id=6, age=15, gender=M, firstName=David, lastName=Feezor)
Employee(id=9, age=15, gender=F, firstName=Neetu, lastName=Singh)
Employee(id=5, age=19, gender=F, firstName=Cristine, lastName=Maria)
Employee(id=1, age=23, gender=M, firstName=Rick, lastName=Beethovan)
Employee(id=4, age=26, gender=M, firstName=Jon, lastName=Lowman)
Employee(id=3, age=43, gender=M, firstName=Ricky, lastName=Martin)
Employee(id=10, age=45, gender=M, firstName=Naveen, lastName=Jain)
Employee(id=7, age=68, gender=F, firstName=Melissa, lastName=Roy)
Employee(id=8, age=79, gender=M, firstName=Alex, lastName=Gussin)
- 如果我們希望List按照年齡age的倒序排序,就使用reversed()方法。如:
employees.sort(Comparator.comparing(Employee::getAge).reversed());
四、Comparator鏈對List<Object>排序
下面這段代碼先是按性別的倒序排序,再按照年齡的倒序排序。
employees.sort(
Comparator.comparing(Employee::getGender)
.thenComparing(Employee::getAge)
.reversed()
);
employees.forEach(System.out::println);
//都是正序 ,不加reversed
//都是倒序,最後面加一個reserved
//先是倒序(加reserved),然後正序
//先是正序(加reserved),然後倒序(加reserved)
細心的朋友可能注意到:我們只用了一個reversed()倒序方法,這個和SQL的表述方式不太一樣。這個問題不太好用語言描述,建議大家去看一下本文對應的視頻!
排序結果如下:
Employee(id=8, age=79, gender=M, firstName=Alex, lastName=Gussin)
Employee(id=10, age=45, gender=M, firstName=Naveen, lastName=Jain)
Employee(id=3, age=43, gender=M, firstName=Ricky, lastName=Martin)
Employee(id=4, age=26, gender=M, firstName=Jon, lastName=Lowman)
Employee(id=1, age=23, gender=M, firstName=Rick, lastName=Beethovan)
Employee(id=6, age=15, gender=M, firstName=David, lastName=Feezor)
Employee(id=7, age=68, gender=F, firstName=Melissa, lastName=Roy)
Employee(id=5, age=19, gender=F, firstName=Cristine, lastName=Maria)
Employee(id=9, age=15, gender=F, firstName=Neetu, lastName=Singh)
Employee(id=2, age=13, gender=F, firstName=Martina, lastName=Hengis)
歡迎關注我的博客,裏面有很多精品合集
- 本文轉載註明出處(必須帶連接,不能只轉文字):字母哥博客。
覺得對您有幫助的話,幫我點贊、分享!您的支持是我不竭的創作動力! 。另外,筆者最近一段時間輸出了如下的精品內容,期待您的關注。
- 《手摸手教你學Spring Boot2.0》
- 《Spring Security-JWT-OAuth2一本通》
- 《實戰前後端分離RBAC權限管理系統》
- 《實戰SpringCloud微服務從青銅到王者》
- 《VUE深入淺出系列》
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!