接上回書
書接,分享了Class文件的主要構成,同時也詳細分析了魔數、次版本號、主版本號、常量池集合、訪問標誌的構造,接下來我們就繼續學習。
歡迎關注微信公眾號:萬貓學社,每周一分享Java技術乾貨。
類索引和父類索引
類索引(this_class)和父類索引(super_class)都是一個u2類型的數據,類索引用於確定這個類的全限定名,父類索引用於確定這個類的父類全限定名。由於java語言不允許多重繼承,所以父類索引只有一個。
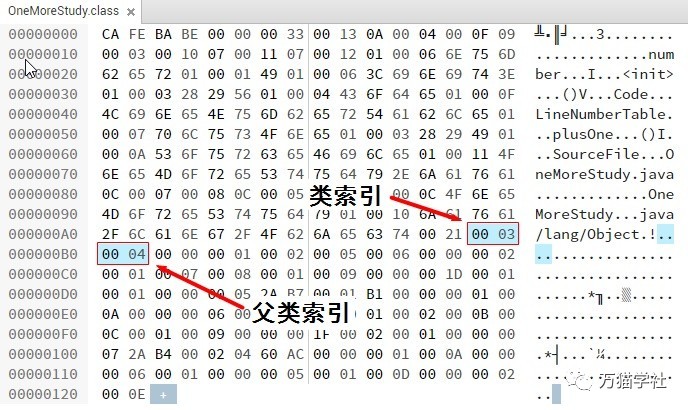
類索引和父類索引各自指向常量池中類型為CONSTANT_Class_info的類描述符,再通過類描述符中的索引值找到常量池中類型為CONSTANT_Utf8_info的字符串。再來看一下之前的Class文件例子:
歡迎關注微信公眾號:萬貓學社,每周一分享Java技術乾貨。
結合之前javap分析出來的常量池內容:
#3 = Class #17 // OneMoreStudy
#4 = Class #18 // java/lang/Object
#17 = Utf8 OneMoreStudy
#18 = Utf8 java/lang/Object類索引為0x0003,去常量池裡找索引為3的類描述符,類描述符中的索引為17,再去找索引為17的字符串,就是“OneMoreStudy”。
父類索引為0x0004,去常量池裡找索引為4的類描述符,類描述符中的索引為18,再去常量池裡找索引為18的字符串,就是“java/lang/Object”。
歡迎關注微信公眾號:萬貓學社,每周一分享Java技術乾貨。
接口索引集合
接口索引集合(interface)是一組u2類型的數據的集合,由於java語言允許實現多個接口,所以接口索引也有多個,它們按照implements語句后的接口順序從左到右依次排列在接口索引集合中。接口索引集合的第一項數據是接口集合計數值(interfaces_count),表示有多少接口索引。如果該類沒有實現任何接口,那麼該計數值為0,後面的接口索引表不佔任何字節。之前的例子OneMoreStudy類沒有實現任何接口,所以接口集合計數值就是0,如下圖:
歡迎關注微信公眾號:萬貓學社,每周一分享Java技術乾貨。
字段表集合
字段表(field_info)是用來描述接口或類中聲明的變量。包括類級變量(靜態變量)和實例級變量(成員變量),但是不包括在方法內部聲明的局部變量。具體結構如下錶:
| 類型 | 名稱 | 數量 | 描述 |
|---|---|---|---|
| u2 | access_flags | 1 | 字段的訪問標誌 |
| u2 | name_index | 1 | 字段的簡單名稱索引 |
| u2 | descriptor_index | 1 | 字段的描述符索引 |
| u2 | attributes_count | 1 | 字段的屬性計數值 |
| attribute_info | attributes | attributes_count | 字段的屬性 |
字段表中的access_flags,和類的access_flags是非常類似的,但是標識和含義是不一樣的。具體如下錶:
| 標誌名稱 | 標誌值 | 含義 |
|---|---|---|
| ACC_PUBLIC | 0x0001 | 字段是否public |
| ACC_PRIVATE | 0x0002 | 字段是否private |
| ACC_PROTECTED | 0x0004 | 字段是否protected |
| ACC_STATIC | 0x0008 | 字段是否static |
| ACC_FINAL | 0x0010 | 字段是否為final |
| ACC_VOLATILE | 0x0040 | 字段是否volatile |
| ACC_TRANSIENT | 0x0080 | 字段是否transient |
| ACC_SYNTHETIC | 0x1000 | 字段是否由編譯器自動產生的 |
| ACC_ENUM | 0x4000 | 字段是否enum |
歡迎關注微信公眾號:萬貓學社,每周一分享Java技術乾貨。
這裏提到了簡單名稱、描述符,和全限定名有什麼區別呢?稍微說一下。
簡單名稱是沒有類型和參數修飾的方法或字段名稱,比如OneMoreStudy類中的number字段和plusOne()方法的簡單名稱分別是“number”和“plusOne”。
全限定名是把類全名中的“.”替換成“/”就可以了,比如java.lang.Object類的全限定名就是“java/lang/Object”。
描述符是用來描述字段的數據類型、方法的參數列表(包括數量、類型以及順序)和返回值。基礎數據類型和無返回的void類型都有一個大寫字母表示,對象類型用字符L加對象的全限定名來表示,如下錶:
| 標識字符 | 含義 |
|---|---|
| B | 基本類型byte |
| C | 基本類型char |
| D | 基本類型double |
| F | 基本類型float |
| I | 基本類型int |
| J | 基本類型long |
| S | 基本類型short |
| Z | 基本類型boolean |
| V | 特殊類型void |
| L | 對象類型 如 Ljava/lang/Object |
對於數組類型,每一維度使用一個前置的“[”字符來描述,比如java.lang.Object[][]的二維數據,就是“[[Ljava/lang/Object”。在描述方法時,按照先參數列表,后返回值的順序描述,參數列表按照嚴格順序放在“()”值中,比如boolean equals(Object anObject),就是“(Ljava/lang/Object)B”。
歡迎關注微信公眾號:萬貓學社,每周一分享Java技術乾貨。
再來看一下之前的Class文件例子:
OneMoreStudy類中只有一個字段number,所以字段計數值為0x0001。字段number只被private修飾,沒有其他修飾,所以字段的訪問標誌位為0x0002。字段的簡單名稱索引是0x0005,去常量池中找索引為5的字符串,為“number”。字段的描述符索引為0x0006,去常量池中找索引為6的字符串,為“I”,是基本類型int。以下是常量池相關內容:
#5 = Utf8 number
#6 = Utf8 I字段number的屬性計數值為0x0000,也就是沒有需要額外描述的信息。
字段表集合中不會列出從父類或者父接口中繼承而來的字段,但有可能列出原版Java代碼中沒有的字段,比如在內部類中為了保持對外部類的訪問性,會自動添加指向外部類實例的字段。
歡迎關注微信公眾號:萬貓學社,每周一分享Java技術乾貨。
方法表集合
方法表的結構和字段表的是一樣的,也是依次包括了訪問標誌(access_flags)、名稱索引(name_index)、描述符索引(descriptor_index)和屬性表集合(attributes)。具體如下錶:
| 類型 | 名稱 | 數量 | 描述 |
|---|---|---|---|
| u2 | access_flags | 1 | 方法的訪問標誌 |
| u2 | name_index | 1 | 方法的簡單名稱索引 |
| u2 | descriptor_index | 1 | 方法的描述符索引 |
| u2 | attributes_count | 1 | 方法的屬性計數值 |
| attribute_info | attributes | attributes_count | 方法的屬性 |
對於方法的訪問標誌,所有標誌位和取值如下錶:
| 標誌名稱 | 標誌值 | 含義 |
|---|---|---|
| ACC_PUBLIC | 0x0001 | 方法是否public |
| ACC_PRIVATE | 0x0002 | 方法是否private |
| ACC_PROTECTED | 0x0004 | 方法是否protected |
| ACC_STATIC | 0x0008 | 方法是否static |
| ACC_FINAL | 0x0010 | 方法是否為final |
| ACC_SYNCHRONIZED | 0x0020 | 方法是否sychronized |
| ACC_BRIDGE | 0x0040 | 方法是否是由編譯器產生的橋接方法 |
| ACC_VARARGS | 0x0080 | 方法是否接受不定參數 |
| ACC_NATIVE | 0x0100 | 方法是否為native |
| ACC_ABSTRACT | 0x0400 | 方法是否為abstract |
| ACC_STRICT | 0x0800 | 方法是否為strictfp |
| ACC_SYNTHETIC | 0x1000 | 方法是否由編譯器自動產生 |
方法中的Java代碼,經過編譯器編程成字節碼指令后,放在方法屬性表集合中一個名為“Code”的屬性里,後面會有更多分享。
歡迎關注微信公眾號:萬貓學社,每周一分享Java技術乾貨。
再來看一下之前的Class文件例子:
方法計算值為0x0003,表示集合中有兩個方法(編譯器自動添加的無參構造方法和源碼中的plusOne方法)。第一個方法的訪問標誌是0x0001,表示只有ACC_PUBLIC標誌為true。
名稱索引為0x0007,在常量池中為索引為7的字符串為“ ”,這就是編譯器自動添加的無參構造方法。描述符索引為0x0008,在常量池中為索引為7的字符串為“()V”,方法的屬性計數值為0x0001,表示該方法有1個屬性,屬性名稱索引為0x0009,在常量池中為索引為7的字符串為“Code”。以下是常量池相關內容:
#7 = Utf8 <init>
#8 = Utf8 ()V
#9 = Utf8 Code歡迎關注微信公眾號:萬貓學社,每周一分享Java技術乾貨。
屬性表集合
屬性表(attribute_info)在前面的分享中出現了幾次,在Class文件、字段表、方法表都可以有自己的屬性表集合,用來描述某些場景下特有的信息。
屬性表不在要求具有嚴格的順序,並且只要不與已有的屬性名重複,任何人實現的編譯器都可以寫入自己定義的屬性信息,Java虛擬機在運行時會忽略掉它不認識的屬性。
我總結了一些比較常見的屬性,如下錶:
| 屬性名稱 | 使用位置 | 含義 |
|---|---|---|
| Code | 方法表 | Java代碼編譯成的字節碼指令 |
| ConstantValue | 字段表 | final關鍵字定義的常量值 |
| Exceptions | 方法表 | 方法拋出的異常 |
| InnerClasses | 類文件 | 內部類列表 |
| LineNumberTable | Code屬性 | Java源碼的行號與字節碼指定的對應關係 |
| LocalVariableTable | Code屬性 | 方法的局部變量描述 |
| SourceFile | 類文件 | 記錄源文件名稱 |
對於每個屬性,它的名稱都從常量池中引用一個CONSTANT_Utf8_info類型的常量,而屬性值的結構則是完全自定義的,只需要用一個u4類型來說明屬性值所佔的位數就可以了。具體結構如下:
| 類型 | 名稱 | 數量 | 含義 |
|---|---|---|---|
| u2 | attribute_name_index | 1 | 屬性名稱索引 |
| u2 | attribute_length | 1 | 屬性值所佔的位數 |
| u1 | info | attribute_length | 屬性值 |
歡迎關注微信公眾號:萬貓學社,每周一分享Java技術乾貨。
總結
Class文件主要由魔數、次版本號、主版本號、常量池集合、訪問標誌、類索引、父類索引、接口索引集合、字段表集合、方法表集合和屬性表集合組成。隨着JDK版本的不斷升級,Class文件結構也在不斷更新,學習之路,永不止步。
歡迎關注微信公眾號:萬貓學社,每周一分享Java技術乾貨。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※收購3c,收購IPHONE,收購蘋果電腦-詳細收購流程一覽表
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
※公開收購3c價格,不怕被賤賣!
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象