環境資訊中心綜合外電;姜唯 編譯;林大利 審校
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!
北部有線電視-提供穩定的寬頻光纖上網、高畫質HD數位頻道、第四台電視、數位電視,現在申辦免費體驗3個月"HD99高畫質套餐"
摘錄自2020年8月4日中央社報導
美國農業部(USDA)動植物健康檢查局副局長艾爾西(Osama El-Lissy)表示,截至7月29日止,已鑑定出芥菜、高麗菜、牽牛花、薄荷、鼠尾草、迷迭香、薰衣草等植物種子,另有木棉花、玫瑰種子。目前鑑定出的品種雖屬無害,但植物專家警告,外來種子有可能損害農作物。
美國哥倫比亞廣播公司新聞網(CBS News)報導,全美50州都有民眾通報收到可疑種子包裹。美國農業部已提醒民眾收到後千萬不要栽種,應立刻向當地的農政單位通報。德州農業廳長米勒(Sid Miller)呼籲民眾保持警覺,「那可能是細菌,也可能是病毒或某個外來種植物」。
維吉尼亞州的農業官員警告:「外來物種會造成環境浩劫,取代或破壞原生植物及昆蟲,嚴重損害農作物。降低外來物種入侵並大量繁殖的風險並減少相關管控成本,最有效的方法就是採取措施、預防入侵物種的引入。」
愛荷華州農業暨土地管理廳的種子檢驗官員普魯伊斯納(Robin Pruisner)表示,有通報指出種子上可能含有殺蟲或除黴劑,對農作物危害甚大。
生物多樣性
國際新聞
美國
種子
外來物種
入侵植物
外來種植物
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
時間序列數據伴隨着我們的生活和工作。從牙牙學語時的“1, 2, 3, 4, 5, ……”到房價的走勢變化,從金融領域的刷卡記錄到運維領域的核心網性能指標。時間序列中的規律能加深我們對事物和場景的認識,時間序列中的異常能提醒我們某些部分可能出現問題。那麼如何去發現時間序列中的規律、找出其中的異常點呢?接下來,我們將揭開這些問題的面紗。
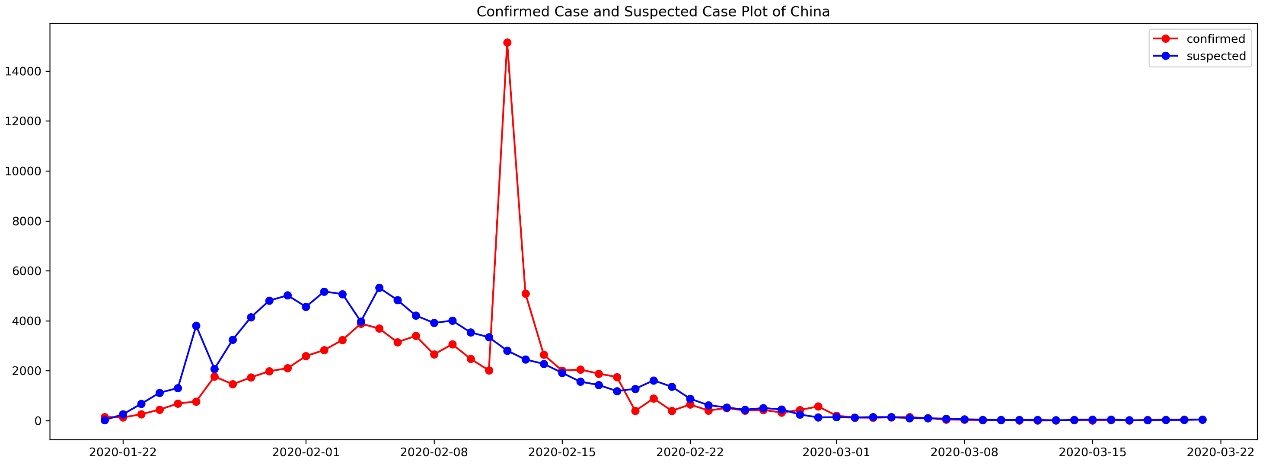
直觀上講,異常就是現實與心理預期產生較大差距的特殊情形。如2020年春節的新型肺炎(COVID-19,coronavirus disease 2019),可以看到2月12日有一個明顯的確診病例的升高,這就是一個異常點,如下圖:
從統計上講,嚴重偏離預期的點,常見的可以通過3-sigma準則來判定。
從數學上講,它就是一個分段函數:
那麼我們有哪些方法來發現異常呢?異常分析的方法有很多,在本文中,我們主要講解時間序列分解的算法。接下來,我們先從時間序列的定義開始講起。
前面章節,我們列舉了生活和工作中的一些時間序列的例子,但是並沒有給出定義。在本節中,我們將首先給出時間序列的定義,然後給出時間序列的分類方法,最後再給大家展示常見的時間序列。
1.時間序列的定義
時間序列是不同時間點的一系列變量所組成的有序序列。例如北京市2013年4月每日的平均氣溫就構成了一個時間序列,為了方便,我們一般認為序列中相鄰元素具有相同的時間間隔。
時間序列可以分為確定的和隨機的。例如,一個1990年出生的人,從1990年到1999年年齡可以表述為{0,1,2,…,9},這個序列並沒有任何隨機因素。這是一個確定性的時間序列。現實生活中我們所面對的序列更多的是摻雜了隨機因素的時間序列,例如氣溫、銷售量等等,這些是帶有隨機性的例子。我們說的時間序列一般是指帶有隨機性的。
那麼對於隨機性的時間序列,又如何進行分類呢?
2.時間序列的分類
從研究對象上分,時間序列分為一元時間序列和多元時間序列,如新冠肺炎例子中,只看確診病例的變化,它是一元時間序列。如果把確診病例和疑似病例聯合起來看,它是一個多元時間序列。
從時間參數上分,時間序列分為離散時間的時間序列和連續時間的時間序列。例如氣溫變化曲線,通常是按照天、小時進行預測、計算的,這個採集的時間是離散的,因此,它是一個離散時間的時間序列。再如花粉在水中呈現不規則的運動,它無時無刻不在運動,它是一個連續時間的時間序列,這就是大家眾所周知的布朗運動。在我們的工作中,我們一般遇到的都是離散時間的時間序列。
從統計特徵上分,時間序列分為平穩時間序列和非平穩時間序列。平穩序列從直觀上講,均值和標準差不隨着時間發生變化,而非平穩序列均值或者標準差一般會隨着時間發生變化。下面兩個圖分別給出平穩序列和非平穩序列的例子。
3.常見的時間序列
在本節,我們將給大家列舉一些常見的時間序列,讓大家對常見的時間序列有一個直觀的概念。
前面給大家講了異常和時間序列的概念,本章將給大家講解時間序列分解技術。
1.目的
時間序列分解是探索時序變化規律的一種方法,主要探索周期性和趨勢性。基於時序分解的結果,我們可以進行後續的時間預測和異常檢測。
2.主要組成部分
在時間序列分析中,我們經常要關注趨勢和周期。因此,一般地,我們將時序分成三個部分:趨勢部分、周期部分和殘差部分。結合下圖CO2含量的例子(見下圖)對這三個主要部分進行解釋:
1)趨勢部分:展示了CO2含量逐年增加;
2)周期部分:反應了一年中CO2含量是周期波動的;
3)殘差部分:趨勢和周期部分不能解釋的部分。
3.時序分解模型
時間序列分解基於分解模型的假設。通常,我們會考慮以下兩種模型:
加法模型適用於以下場景:
乘法模型適用於以下場景:
另外,當我們不清楚選擇哪個模型時,可以兩個模型都使用,選擇誤差最小的那一個。
由於乘法模型與加法模型可以相互轉化,我們後面僅以加法模型來進行介紹。
4.時序分解算法
基於周期、趨勢分解的時序分解算法主要有經典時序分解算法、Holt-Winters算法和STL算法。經典時序分解算法起源於20世紀20年代,方法較簡單。Holt-Winters算法於1960年由Holt的學生 Peter Winters 提出,能夠適應隨着時間變化的季節項。STL(Seasonal and Trend decomposition using Loess)分解法,由Cleveland 等於1990年提出,比較通用,且較為穩健。三者之間的關係,如下圖所示:
4.1經典時序分解算法
經典時序分解算法是最簡單的一種分解算法,它是很多其他分解算法的基礎。該算法基於“季節部分不隨着時間發生變化”這一假設,且需要知道序列的周期。另外,該算法基於滑動平均技術。
其中,m=2k+1. 也就是說,時刻t的趨勢項的估計值可以通過前後k個時刻內的平均值得到。階數 m 越大,趨勢越光滑。由上面的公式可以看出,m一般取奇數,這保證了對稱性。但是在很多場景下,周期是偶數,例如一年有4個季度,則周期為4,是偶數。此時,需要做先做一個4階滑動平均(4-MA),再對所得結果做一個2階滑動平均(2-MA),整個過程記為 。這樣處理后的結果是對稱的,即加權的滑動平均,數學表達如下:
下面我們將講解經典時序分解算法的計算步驟。
經典時序分解算法雖然簡單、應用廣泛,但是也存在一些問題:
1) 無法估計序列最前面幾個和最後面幾個的趨勢和周期部分,例如若m=4,則無法估計前2個和后2個觀測的趨勢和周期的部分;
2) 嚴重依賴“季節性部分每個周期都是相同的”這一假設;
3) 過度光滑趨勢部分。
4.2Holt-Winters算法
在上一節中,我們介紹了經典時序分解算法,但是它嚴重依賴“季節性部分每個周期都是相同的”這一假設。為了能夠適應季節部分隨時間發生變化,Holt-Winters算法被提出。Holt-Winters算法是基於簡單指數光滑技術。首先,我們先介紹簡單指數光滑技術。
簡單指數光滑的思想主要是以下兩點:
簡單指數光滑的模型比較簡單,如下:
Holt-Winters算法是簡單指數光滑在趨勢(可理解為水平的變化率)和季節性上的推廣,主要包括水平(前文中的趨勢項)、趨勢項和季節項三個部分。
4.3 STL算法
STL(Seasonal and Trend decomposition using Loess)是一個非常通用的、穩健性強的時序分解方法,其中Loess是一種估算非線性關係的方法。STL分解法由 Cleveland et al. (1990) 提出。
STL算法中最主要的是局部光滑技術 (locally weighted scatterplot smoothing, LOWESS or LOESS),有時也稱為局部多項式回歸擬合。它是對兩維散點圖進行平滑的常用方法,它結合了傳統線性回歸的簡潔性和非線性回歸的靈活性。當要估計某個響應變量值時,先從其預測點附近取一個數據子集(如下圖實點 是要預測的點,選取周圍的需點來進行擬合),然後對該子集進行線性回歸或二次回歸,回歸時採用加權最小二乘法(如下圖,採用的是高斯核進行加權),即越靠近估計點的值其權重越大,最後利用得到的局部回歸模型來估計響應變量的值。用這種方法進行逐點運算得到整條擬合曲線。
STL算法的主要環節包含內循環、外循環和季節項后平滑三個部分:
外循環主要作用則是引入了一個穩健性權重項,以控制數據中異常值產生的影響,這一項將會考慮到下一階段內循環的臨近權重中去。
趨勢分量和季節分量都是在內循環中得到的。循環完后,季節項將出現一定程度的毛刺現象,因為在內循環中平滑時是在每一個截口中進行的,因此,在按照時間序列重排后,就無法保證相鄰時段的平滑了,為此,還需要進行季節項的后平滑,后平滑基於局部二次擬合,並且不再需要在loess中進行穩健性迭代。
對於異常的判斷,我們常用的有 n-sigma 準則和boxplot準則(箱線圖準則)。那這些準備是如何計算的,有哪些區別和聯繫呢?
1.n-sigma 準則
n-sigma準則有計算簡單、效率高且有很強的理論支撐,但是需要近似正態的假設,且均值和標準差的計算用到了全部的數據,因此,受異常點的影響較大。
2.boxplot 準則
為了降低異常點的影響,boxplot準則被提出。boxplot(箱線圖)是一種用作显示一組數據分散情況的統計圖,經常用於異常檢測。BoxPlot的核心在於計算一組數據的中位數、兩個四分位數、上限和下限,基於這些統計值畫出箱線圖。
根據上面的統計值就可以畫出下面的圖,超過上限的點或這個低於下限的點都可以認為是異常點。
從上面的計算上可以看出,boxplot對異常點是穩健的。
在前面的章節,我們了解了時序分解的算法,也學習了異常判斷的準則,那麼如何基於時序分解進行異常檢測呢?在本章,我們將首先給出異常檢測算法的原理,再給出基於時序分解的異常檢測算法步驟。
1.異常檢測算法原理
回顧一下異常的定義,它是一個分段函數:
我們可以看到預測值(擬合值)和閾值是不知道的。對於預測值,我們可以通過找規律來猜這個預測值是多少,本章我們可以通過時序分解找周期和趨勢的規律,進而得到預測值。對於閾值,我們可以看到閾值是針對真實值和預測值的差值設置的,目的是把異常值找到,因此我們只要找到正常值的殘差和異常值的殘差的邊界即可。而我們n-sigma準則和boxplot準則就可以根據殘差把邊界找出來,即閾值。這個思考和實現的過程示意圖如下:
2.基於時序分解的異常檢測算法
Demo代碼下載地址 ,本文主要是想記錄基於時間序列的異常檢測方法,希望能夠幫到你。
點擊關注,第一時間了解華為雲新鮮技術~
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
獲取流數據的時候,通常需要根據所需把流拆分出其他多個流,根據不同的流再去作相應的處理。
舉個例子:創建一個商品實時流,商品有季節標籤,需要對不同標籤的商品做統計處理,這個時候就需要把商品數據流根據季節標籤分流。
先模擬一個實時的數據流
import lombok.Data;
@Data
public class Product {
public Integer id;
public String seasonType;
}
自定義Source
import common.Product;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import java.util.ArrayList;
import java.util.Random;
public class ProductStremingSource implements SourceFunction<Product> {
private boolean isRunning = true;
@Override
public void run(SourceContext<Product> ctx) throws Exception {
while (isRunning){
// 每一秒鐘產生一條數據
Product product = generateProduct();
ctx.collect(product);
Thread.sleep(1000);
}
}
private Product generateProduct(){
int i = new Random().nextInt(100);
ArrayList<String> list = new ArrayList();
list.add("spring");
list.add("summer");
list.add("autumn");
list.add("winter");
Product product = new Product();
product.setSeasonType(list.get(new Random().nextInt(4)));
product.setId(i);
return product;
}
@Override
public void cancel() {
}
}
輸出:
使用 filter 算子根據數據的字段進行過濾。
import common.Product;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import source.ProductStremingSource;
public class OutputStremingDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Product> source = env.addSource(new ProductStremingSource());
// 使用Filter分流
SingleOutputStreamOperator<Product> spring = source.filter(product -> "spring".equals(product.getSeasonType()));
SingleOutputStreamOperator<Product> summer = source.filter(product -> "summer".equals(product.getSeasonType()));
SingleOutputStreamOperator<Product> autumn = source.filter(product -> "autumn".equals(product.getSeasonType()));
SingleOutputStreamOperator<Product> winter = source.filter(product -> "winter".equals(product.getSeasonType()));
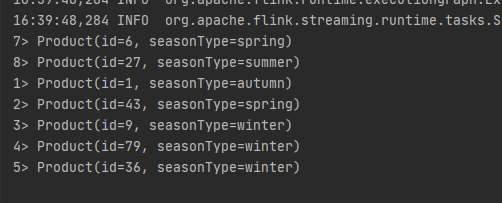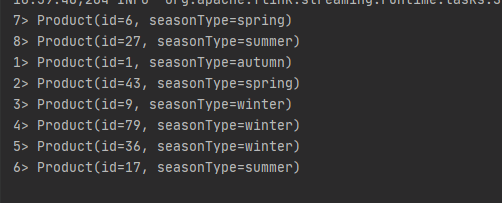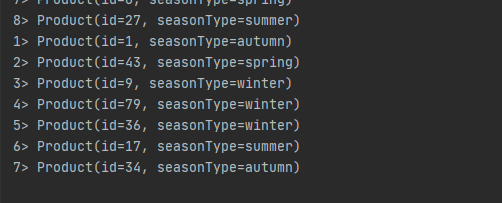
source.print();
winter.printToErr();
env.execute("output");
}
}
結果輸出(紅色為季節標籤是winter的分流輸出):
重寫OutputSelector內部類的select()方法,根據數據所需要分流的類型反正不同的標籤下,返回SplitStream,通過SplitStream的select()方法去選擇相應的數據流。
只分流一次是沒有問題的,但是不能使用它來做連續的分流。
SplitStream已經標記過時了
public class OutputStremingDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Product> source = env.addSource(new ProductStremingSource());
// 使用Split分流
SplitStream<Product> dataSelect = source.split(new OutputSelector<Product>() {
@Override
public Iterable<String> select(Product product) {
List<String> seasonTypes = new ArrayList<>();
String seasonType = product.getSeasonType();
switch (seasonType){
case "spring":
seasonTypes.add(seasonType);
break;
case "summer":
seasonTypes.add(seasonType);
break;
case "autumn":
seasonTypes.add(seasonType);
break;
case "winter":
seasonTypes.add(seasonType);
break;
default:
break;
}
return seasonTypes;
}
});
DataStream<Product> spring = dataSelect.select("machine");
DataStream<Product> summer = dataSelect.select("docker");
DataStream<Product> autumn = dataSelect.select("application");
DataStream<Product> winter = dataSelect.select("middleware");
source.print();
winter.printToErr();
env.execute("output");
}
}
推薦使用這種方式
首先需要定義一個OutputTag用於標識不同流
可以使用下面的幾種函數處理流發送到分流中:
之後再用getSideOutput(OutputTag)選擇流。
public class OutputStremingDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Product> source = env.addSource(new ProductStremingSource());
// 使用Side Output分流
final OutputTag<Product> spring = new OutputTag<Product>("spring");
final OutputTag<Product> summer = new OutputTag<Product>("summer");
final OutputTag<Product> autumn = new OutputTag<Product>("autumn");
final OutputTag<Product> winter = new OutputTag<Product>("winter");
SingleOutputStreamOperator<Product> sideOutputData = source.process(new ProcessFunction<Product, Product>() {
@Override
public void processElement(Product product, Context ctx, Collector<Product> out) throws Exception {
String seasonType = product.getSeasonType();
switch (seasonType){
case "spring":
ctx.output(spring,product);
break;
case "summer":
ctx.output(summer,product);
break;
case "autumn":
ctx.output(autumn,product);
break;
case "winter":
ctx.output(winter,product);
break;
default:
out.collect(product);
}
}
});
DataStream<Product> springStream = sideOutputData.getSideOutput(spring);
DataStream<Product> summerStream = sideOutputData.getSideOutput(summer);
DataStream<Product> autumnStream = sideOutputData.getSideOutput(autumn);
DataStream<Product> winterStream = sideOutputData.getSideOutput(winter);
// 輸出標籤為:winter 的數據流
winterStream.print();
env.execute("output");
}
}
結果輸出:
更多文章:www.ipooli.com
掃碼關注公眾號《ipoo》
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!
我們福祿網絡致力於為廣大用戶提供智能化充值服務,包括各類通信充值卡(比如移動、聯通、電信的話費及流量充值)、遊戲類充值卡(比如王者榮耀、吃雞類點券、AppleStore充值、Q幣、鬥魚幣等)、生活服務類(比如肯德基、小鹿茶等),網娛類(比如QQ各類鑽等),作為一個服務提供商,商品質量的穩定、持續及充值過程的便捷一直是我們在業內的口碑。
在整個商品流通過程中,如何做好庫存的管理,以充分提高庫存運轉周期和資金使用效率,一直是個難題。基於此,我們提出了智能化的庫存管理服務,根據訂單數據及商品數據,來預測不同商品隨着時間推移的日常消耗情況。
目前成熟的時間序列預測算法很多,但商業領域性能優越的卻不多,經過多種嘗試,給大家推薦2種時間序列算法:facebook開源的Prophet算法和LSTM深度學習算法。
現將個人理解的2種算法特性予以簡要說明:
time,product,cnt
2019-10-01 00,**充值,6
2019-10-01 00,***遊戲,368
2019-10-01 00,***,1
2019-10-01 00,***,11
2019-10-01 00,***遊戲,17
2019-10-01 00
,三網***,39
2019-10-01 00,**網,6
2019-10-01 00,***,2
字段說明:
時間序列一般不進行特徵處理,當然可以根據具體情況進行歸一化處理或是取對數處理等。
目前待選的算法主要有2種:
以上是理論上的調參步驟,但我們在實際情況下在建議使用grid_search(網格尋參)方式,直接簡單效果好。當機器性能不佳時網格調參配合理論調參方法可以加快調參速度。建議初學者使用手動調參方式以理解每個參數對模型效果的影響。
holiday.csv
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from fbprophet import Prophet
data = pd.read_csv('../data/data2.csv', parse_dates=['time'], index_col='time')
def get_product_data(name, rule=None):
product = data[data['product'] == name][['cnt']]
product.plot()
if rule is not None:
product = product.resample(rule).sum()
product.reset_index(inplace=True)
product.columns = ['ds', 'y']
return product
holidays = pd.read_csv('holiday.csv', parse_dates=['ds'])
holidays['lower_window'] = -1
holidays = holidays.append(pd.DataFrame({
'holiday': '雙11',
'ds': pd.to_datetime(['2019-11-11', '2020-11-11']),
'lower_window': -1,
'upper_window': 1,
})).append(pd.DataFrame({
'holiday': '雙12',
'ds': pd.to_datetime(['2019-12-12', '2020-12-12']),
'lower_window': -1,
'upper_window': 1,
})
)
def predict(name, rule='1d', freq='d', periods=1, show=False):
ds = get_product_data(name, rule=rule)
if ds.shape[0] < 7:
return None
m = Prophet(holidays=holidays)
m.fit(ds)
future = m.make_future_dataframe(freq=freq, periods=periods) # 建立數據預測框架,數據粒度為天,預測步長為一年
forecast = m.predict(future)
if show:
m.plot(forecast).show() # 繪製預測效果圖
m.plot_components(forecast).show() # 繪製成分趨勢圖
mse = forecast['yhat'].iloc[ds.shape[0]] - ds['y'].values
mse = np.abs(mse) / (ds['y'].values + 1)
return [name, mse.mean(), mse.max(), mse.min(), np.quantile(mse, 0.9), np.quantile(mse, 0.8), mse[-7:].mean(),
ds['y'].iloc[-7:].mean()]
if __name__ == '__main__':
products = set(data['product'])
p = []
for i in products:
y = predict(i)
if y is not None:
p.append(y)
df = pd.DataFrame(p, columns=['product', 'total_mean', 'total_max', 'total_min', '0.9', '0.8', '7_mean',
'7_real_value_mean'])
df.set_index('product', inplace=True)
product_sum: pd.DataFrame = data.groupby('product').sum()
df = df.join(product_sum)
df.sort_values('cnt', ascending=False, inplace=True)
df.to_csv('result.csv', index=False)
結果如下:由於行數較多這裏只展示前1行
根據結果,對比原生數據,可以得出如下結論:
就算法與產品的匹配性可分為3個類型:
A. 因素分解圖
上圖中主要分為3個部分,分別對應prophet 3大要素,趨勢、節假日或特殊日期、周期性(包括年周期、月周期、week周期、天周期以及用戶自定義的周期)
下面依照上面因素分解圖的順序依次對圖進行說明:
LSTM(長短記憶網絡)主要用於有先後順序的序列類型的數據的深度學習網絡。是RNN的優化版本。一般用於自然語言處理,也可用於時間序列的預測。
簡單來說就是,LSTM一共有三個門,輸入門,遺忘門,輸出門, i 、o、 f 分別為三個門的程度參數, g 與RNN中的概念一致。公式里可以看到LSTM的輸出有兩個,細胞狀態c 和隱狀態 h,c是經輸入、遺忘門的產物,也就是當前cell本身的內容,經過輸出門得到h,就是想輸出什麼內容給下一單元。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
from torch import nn
from sklearn.preprocessing import MinMaxScaler
ts_data = pd.read_csv('../data/data2.csv', parse_dates=['time'], index_col='time')
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
n_vars = 1 if type(data) is list else data.shape[1]
df = pd.DataFrame(data)
cols, names = list(), list()
# input sequence (t-n, ... t-1)
for i in range(n_in, 0, -1):
cols.append(df.shift(i))
names += [('var%d(t-%d)' % (j + 1, i)) for j in range(n_vars)]
# forecast sequence (t, t+1, ... t+n)
for i in range(0, n_out):
cols.append(df.shift(-i))
if i == 0:
names += [('var%d(t)' % (j + 1)) for j in range(n_vars)]
else:
names += [('var%d(t+%d)' % (j + 1, i)) for j in range(n_vars)]
# put it all together
agg = pd.concat(cols, axis=1)
agg.columns = names
# drop rows with NaN values
if dropnan:
agg.dropna(inplace=True)
return agg
def transform_data(feature_cnt=2):
yd = ts_data[ts_data['product'] == '移動話費'][['cnt']]
scaler = MinMaxScaler(feature_range=(0, 1))
yd_scaled = scaler.fit_transform(yd.values)
yd_renamed = series_to_supervised(yd_scaled
, n_in=feature_cnt).values.astype('float32')
n_row = yd_renamed.shape[0]
n_train = int(n_row * 0.7)
train_X, train_y = yd_renamed[:n_train, :-1], yd_renamed[:n_train, -1]
test_X, test_y = yd_renamed[n_train:, :-1], yd_renamed[n_train:, -1]
# 最後,我們需要將數據改變一下形狀,因為 RNN 讀入的數據維度是 (seq, batch, feature),所以要重新改變一下數據的維度,這裏只有一個序列,所以 batch 是 1,而輸入的 feature 就是我們希望依據的幾天,這裏我們定的是兩個天,所以 feature 就是 2.
train_X = train_X.reshape((-1, 1, feature_cnt))
test_X = test_X.reshape((-1, 1, feature_cnt))
print(train_X.shape, train_y.shape, test_X.shape, test_y.shape)
# 轉化成torch 的張量
train_x = torch.from_numpy(train_X)
train_y = torch.from_numpy(train_y)
test_x = torch.from_numpy(test_X)
test_y = torch.from_numpy(test_y)
return scaler, train_x, train_y, test_x, test_y
scaler, train_x, train_y, test_x, test_y = transform_data(24)
# lstm 網絡
class lstm_reg(nn.Module): # 括號中的是python的類繼承語法,父類是nn.Module類 不是參數的意思
def __init__(self, input_size, hidden_size, output_size=1, num_layers=2): # 構造函數
# inpu_size 是輸入的樣本的特徵維度, hidden_size 是LSTM層的神經元個數,
# output_size是輸出的特徵維度
super(lstm_reg, self).__init__() # super用於多層繼承使用,必須要有的操作
self.rnn = nn.LSTM(input_size, hidden_size, num_layers) # 兩層LSTM網絡,
self.reg = nn.Linear(hidden_size, output_size) # 把上一層總共hidden_size個的神經元的輸出向量作為輸入向量,然後回歸到output_size維度的輸出向量中
def forward(self, x): # x是輸入的數據
x, _ = self.rnn(x) # 單個下劃線表示不在意的變量,這裡是LSTM網絡輸出的兩個隱藏層狀態
s, b, h = x.shape
x = x.view(s * b, h)
x = self.reg(x)
x = x.view(s, b, -1) # 使用-1表示第三個維度自動根據原來的shape 和已經定了的s,b來確定
return x
def train(feature_cnt, hidden_size, round, save_path='model.pkl'):
# 我使用了GPU加速,如果不用的話需要把.cuda()給註釋掉
net = lstm_reg(feature_cnt, hidden_size)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(net.parameters(), lr=1e-2)
for e in range(round):
# 新版本中可以不使用Variable了
# var_x = Variable(train_x).cuda()
# var_y = Variable(train_y).cuda()
# 將tensor放在GPU上面進行運算
var_x = train_x
var_y = train_y
out = net(var_x)
loss = criterion(out, var_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (e + 1) % 100 == 0:
print('Epoch: {}, Loss:{:.5f}'.format(e + 1, loss.item()))
# 存儲訓練好的模型參數
torch.save(net.state_dict(), save_path)
return net
if __name__ == '__main__':
net = train(24, 8, 5000)
# criterion = nn.MSELoss()
# optimizer = torch.optim.Adam(net.parameters(), lr=1e-2)
pred_test = net(test_x) # 測試集的預測結果
pred_test = pred_test.view(-1).data.numpy() # 先轉移到cpu上才能轉換為numpy
# 乘以原來歸一化的刻度放縮回到原來的值域
origin_test_Y = scaler.inverse_transform(test_y.reshape((-1,1)))
origin_pred_test = scaler.inverse_transform(pred_test.reshape((-1,1)))
# 畫圖
plt.plot(origin_pred_test, 'r', label='prediction')
plt.plot(origin_test_Y, 'b', label='real')
plt.legend(loc='best')
plt.show()
# 計算MSE
# loss = criterion(out, var_y)?
true_data = origin_test_Y
true_data = np.array(true_data)
true_data = np.squeeze(true_data) # 從二維變成一維
MSE = true_data - origin_pred_test
MSE = MSE * MSE
MSE_loss = sum(MSE) / len(MSE)
print(MSE_loss)
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
摘錄自2020年8月11日中央社報導
澳洲當局今天(11日)表示,將持續關閉北領地(Northern Territory)邊界18個月,以免其他疫情重災區的民眾進入,藉此保護當地龐大且弱勢的原住民族群。法新社報導,根據政府統計,北領地僅有約25萬人居住,其中30%為原住民。
外界認為澳洲原住民更容易受到武漢肺炎(COVID-19)等疾病的威脅,因為社會經濟與文化因素會影響醫療照護資源的取得及潛在健康問題。許多原住民族群擔憂疫情恐襲擊偏遠且醫療資源有限的原住民社區。
自澳洲爆發疫情以來,北領地確診病例很少,無人病歿。北領地近來不允許維多利亞州(Victoria)及雪梨的人進入當地。
土地利用
國際新聞
澳洲
原住民
疫情下的社會衝突
弱勢族群
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
摘錄自2020年8月13日公視報導
日本連續一週的高溫已經造成10人死亡。韓國連下50多天的雨,也有42死或失聯。英國蘇格蘭東北部昨天則是發生一起嚴重的火車出軌意外,包括駕駛在內共3人死亡、6人受傷,由於事發當地連日豪雨引發土石災情,英國當局不排除出軌與天氣因素有關。
蘇格蘭東北部的「亞伯丁郡」12日上午9點43分發生列車出軌。這輛蘇格蘭鐵路的列車屬於雙車頭,並有四個車廂,原定終點站為「格拉斯哥皇后街」。不過卻在亞伯丁市區南邊15公里處的「斯冬希文鎮」出軌,當時車上9人,駕駛、調度員和一名乘客當場身亡,其餘六人受輕傷。
事發的斯冬希文鎮,近日來飽受水災所苦。當地媒體報導,可能是山崩引發這場意外,蘇格蘭首席大臣雖然不否認可能性,但希望交通警察部門能徹底調查原因。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!
摘錄自2020年8月13日中央社報導
巨大集團今天(13日)指出,近期自行車市場需求強勁,上半年全球捷安特銷售公司表現亮麗,營收皆較去(2019)年同期有兩位數成長,尤其在三大主要市場美國、歐洲、中國可見自行車銷售熱潮。
在武漢肺炎(COVID-19)疫情影響下,巨大分析,更多民眾選擇以自行車及電動自行車代步、休閒及運動,加上各國政府大力鼓勵民眾騎車,不僅提供購車補貼,也積極改善自行車道基礎設施,預期全球自行車及電動自行車需求會持續成長。
美利達則表示,疫情雖一度影響工廠製造,但復工後市場需求大增,歐美國家民眾改採自行車通勤的比例大增,通路商甚至因為今(2020)年度車款庫存不足,先把明年度的新車款拿來銷售。
污染治理
國際新聞
疫情下的食衣住行
自行車
電動自行車
自行車道
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!
摘錄自2020年8月13日聯合新聞網報導
英國研究團隊發出警告,紐西蘭的南阿爾卑斯山(The Southern Alps)自大約400年前的小冰河時代結束以來,冰河流失了多達62%的面積,相當於73平方公里。
利茲大學(University of Leeds)的卡里維克(Jonathan Carrivick)博士表示:「……新西蘭冰河的流失,隨著氣候變化以及其他影響變得更明顯,流失加速的情況可能只會更糟……。」
卡里維克博士還說:「……未來我們必須制定對策,以減少冰河融化後流入河流的水量,因為這會影響當地的水供應、景觀穩定性和生態系統。」
該研究利用電腦模擬、實地標記及歷史記錄來收集數據,並分析南阿爾卑斯山三個時期的體積變化:包含了1600至1978年、1978至2009年和2009至2019年。數據顯示自小冰期以來,冰的流失增加了兩倍,而且在最近40年間迅速增加。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益