環境資訊中心綜合外電;姜唯 編譯;林大利 審校
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
北部有線電視-提供穩定的寬頻光纖上網、高畫質HD數位頻道、第四台電視、數位電視,現在申辦免費體驗3個月"HD99高畫質套餐"
不管是在現實生活還是當今遊戲中,各式各樣的排名層出不窮。如果我們做好一款遊戲,卻沒有實現排行榜,一定是不完美的。排行榜不僅是玩家了解自己實力的途徑,也是遊戲運營刺激用戶留存的一種途徑。在微信小遊戲中普遍存以下兩種排名
其中好友的排名,需要通過微信子域實現。在子域上下文中,只能調用微信提供相關的api,且數據傳輸只能進不能出。即使在子域中調用雲函數也不行。這個對數據很嚴格,開發略為複雜。但好處也很明顯
儘管這樣,我們還是先實現世界排行。世界排行需要用戶授權。早期只需要調用wx.authorize就可以實現,現在很不穩定(好像廢棄了)。所以不得不通過生成一個授權按鈕來實現
微信小遊戲為開發者提供了一部分免費的雲環境。可以實現文件存儲,數據存儲以及通過雲函數實現服務端接口。開通方式也很簡單,這裏不做說明。既然要實現排名,優先選用雲函數來實現對應的api。要實現雲函數,需要在project.config.json文件中通過屬性cloudfunctionRoot指定雲函數目錄。由於,是通過cocoscretor開發,每次構建發布都會清空輸出內容。為了解決人肉複製粘貼,我們需要通過定製小遊戲構建模板實現微信小遊戲所有代碼的管理。小遊戲地心俠士構建模板如下
從圖中,可以看到獲取openid、獲取世界排名、保存用戶授權信息等雲函數都放在cocoscreator代碼環境中。這樣在開發完成后,通過cocoscreator構建發布,對應的雲函數也會一起打包過去
首先在構建模板的cloud-functions文件件中,使用npm初始一個名為getOpenId的node項目。初始好以後,運行npm install wx-server-sdk@latest --save。這樣就建立好了一個雲函數的基本框架。
我們在index.js文件,輸入以下代碼
// author:herbert 464884492 // project:地心俠士 獲取用戶openid const cloud = require('wx-server-sdk') cloud.init() exports.main = async (event, context) => { const wxContext = cloud.getWXContext() return { event, openid: wxContext.OPENID, appid: wxContext.APPID, unionid: wxContext.UNIONID, } }
調用雲函數時,上下文中便可以得到玩家openid和uninid。玩家進入遊戲就先調用此函數,得到玩家的openid用於後邊更新玩家數據和獲取世界排行的條件。
小遊戲端調用雲函數前,需要初始雲環境。因為採用定製構建模板,所以我們直接在模板的game.js文件末尾初始我的雲環境
// author:herbert 464884492
// 地心俠士 初始雲環境
....
wxDownloader.init();
window.boot();
//初始化雲調用
this.wx.cloud.init({
traceUser: true,
env: 'dxxs-dxxs'
});
...
後續調用雲函數中,第一步都是要獲取openid,這裏定義一個全局變量將其保存起來,調用方法如下
// author:herbert 464884492 // 地心俠士 玩家openid private static openId: string = null; private static initenv() { return new Promise((resolve, reject) => { if (!this.wx) reject(); //直接使用本地緩存 if (this.openId != null) resolve(); // 調用雲函數獲取 this.wx.cloud.callFunction({ name: 'getOpenId', complete: res => { this.openId = res.result.openid; resolve(); } }); }); }
先看下地心俠士布局界面
上圖中可以看到,地心俠士虛擬了一個遊戲操作區域。玩家聚焦到世界排行時,需要渲染一個授權按鈕在確定的位置。需求很簡單,可考慮到移動端多分辨率,這個操作就變得複雜了。需要做屏幕適配。地心俠士採用自適應寬度的適配策略,配置如下圖
遊戲運行時獲取實際分辨率的寬度與設計的寬度相除,變可知道當前寬度變化比列,鍵盤容器九宮格使用了主鍵widget底部111px,高度161px。確定按鈕寬度105px
微信小遊戲以左上角為原點,通過top和left確定位置。然而,cocoscreator以左下角為原點,所以在計算top值時需要用屏幕寬度 – box上邊緣y坐標。適配代碼如下
// author:herbert 464884492 // 地心俠士 動態生成透明授權按鈕 initUserInfoButton() { // 獲取設計尺寸 let desingSize: cc.Size = cc.view.getDesignResolutionSize(); // 獲取實際屏幕尺寸 let screenSize: cc.Size = cc.view.getFrameSize(); // 獲取寬度倍率 let widthRate = screenSize.width / desingSize.width; // 獲取當前倍率下九宮格鍵盤實際高度 let halfKcHeight = 161 * widthRate / 2; // 獲取當前倍率下確定按鈕實際寬度 let btnwidth = this.btnKeySuer.width * widthRate; WxCloudFun.createUserinfoButton("", // 確定按鈕中心點對應小遊戲left值 (屏幕寬度-確定按鈕實際寬度)/2 // 定義實際授權按鈕size為105*40,所以還必須加上對應的偏差值 // 以下代碼中left體現整體適配過程,不考慮中間過程可以直接使用 // (屏幕寬度-授權按鈕)/2 即可得到left值 screenSize.width / 2 - 52.5 * widthRate + (btnwidth - 105) / 2, // Canvas 適配策略是 Fit Width,所以Canvas下邊沿不一定就是屏幕邊緣 // 通過111*widthRate得到具體下沿值,在加上虛擬鍵盤一半高度,可得到中心位置 // 由於微信原點在左上角,需要保持按鈕處於中心位置,坐標還需要上移一半按鈕高度 screenSize.height - (111 * widthRate + halfKcHeight + 20), () => { this.keyCode = cc.macro.KEY.r; this.scheduleOnce(async () => { this.dlgRank.active = true; // 獲取排名數據 await this.getRankInfo(); }, 0); }); }
經過上一步驟的適配操作,只要玩家聚焦到【世界排行】,地心俠士虛擬鍵盤的確定按鈕正上方會覆蓋一個透明的userInfoButton,玩家點擊確定就會喚起授權對話框,然後在對應的回調函數就可以完成用戶數據保存操作
// author:herbert 464884492 // 地心俠士 獲取玩家基本信息 public static createUserinfoButton(text: string, left: number, top: number, cb: Function) { this.userInfoButton = this.wx.createUserInfoButton({ type: 'text', text: text, style: { left: left, top: top, height: 40, width: 105, lineHeight: 40, textAlign: 'center', fontSize: 16, backgroundColor: '#ff000000',// 透明 color: '#ffffff', } }); this.userInfoButton.hide(); this.userInfoButton.onTap((res) => { // 將獲取到的用戶數據提交到雲端 this.wx.cloud.callFunction({ name: 'putUserinfo', data: { ...res.userInfo, openid: this.openId } }); this.hideUserInfoButton(); cb.call(); }); }
在代碼中,除了傳入玩家微信信息外。我還額外傳遞進入遊戲時就獲取的openid。正常情況下不需要的,因為,雲函數中天然會告訴你openid。不過,我們在後端使用了got獲取玩家頭像保存到雲端文件存儲中。引入此包后,後端就獲取不到openid了,相當奇怪。對應雲平台雲函數代碼如下
// author:herbert 464884492 // 地心俠士 雲函數保存玩家基本信息 const cloud = require('wx-server-sdk') const got = require('got') cloud.init() // 雲函數入口函數 exports.main = async(event, context) => { const { nickName, avatarUrl, gender, openid } = event; let wxContext = cloud.getWXContext(); // 如果後端拿不到openid就採用前端傳入的openid wxContext.OPENID = wxContext.OPENID || openid; const log = cloud.logger() log.info({ tip: `正在請求頭像地址[${avatarUrl}]` }) // 獲取頭像數據流 const stream = await got.stream(avatarUrl); let chunks = []; let size = 0; const body = await (async() => { return new Promise((res, reg) => { stream.on('data', chunk => { chunks.push(chunk) size += chunk.length log.info({ tip: `正在讀取圖片流信息:[${chunk.length}]` }) }) stream.on('end', async() => { const body = Buffer.concat(chunks, size) log.info({ tip: `正在保存頭像文件:[${size}]` }) res(body) }) }) })() //保存頭像到雲存儲 const { fileID } = await cloud.uploadFile({ cloudPath: `avatars/${wxContext.OPENID}.jpg`, fileContent: body }) // 添加或更新玩家信息到數據庫 const db = cloud.database() const { data } = await db.collection("dxxs").where({ _openid: wxContext.OPENID }).get() const updateData = { fileId: fileID, nickName: nickName, sex: gender == 1 ? '男' : '女', avatarUrl: avatarUrl } if (data.length > 0) { log.info({ tip: `正在修改數據庫信息:[${size}]` }) await db.collection("dxxs").doc(data[0]._id).update({ data: updateData }) } else { log.info({ tip: `正在添加數據庫信息:[${size}]` }) await db.collection("dxxs").add({ data: { ...updateData, _openid: openid } }) } return { openid: wxContext.OPENID, appid: wxContext.APPID, unionid: wxContext.UNIONID } }
保存完用戶數據后,通過一個回調函數,實現了玩家排名數據獲取。細心的朋友可以在前邊授權按鈕適配的章節看到await this.getRankInfo();這句代碼。後端雲函數就是一個簡單數據查詢。效果圖如下
從上圖可以看到,我實現了三個維度排名,需要在前端需要傳入排名字段。對應代碼如下
// author:herbert 464884492 // 地心俠士 獲取排名信息 public static async getWorldRanking(field: string = "level") { const { result } = await this.wx.cloud.callFunction({ name: 'getWordRanking', data: { order: field } }); return result.ranks; }
雲函數代碼如下
// author:herbert 464884492 // 地心俠士 雲函數返回排名信息 const cloud = require('wx-server-sdk') cloud.init() exports.main = async (event, context) => { const wxContext = cloud.getWXContext() const db = cloud.database(); const { order = "level" } = event; const openData = await db.collection("dxxs") .orderBy(order, "asc") .get() const ranks = openData.data.map(item => { return { openid: item._openid, [order]: item[order], nickName: item.nickName, fileId: item.fileId, avatarUrl: item.avatarUrl } }); return { ranks: ranks, openid: wxContext.OPENID, appid: wxContext.APPID, unionid: wxContext.UNIONID } }
這裡有一個CoscosCreator遊戲開發群,歡迎喜歡聊技術的朋友加入
歡迎感興趣的朋友關注我的訂閱號“小院不小”,或點擊下方二維碼關注。我將多年開發中遇到的難點,以及一些有意思的功能,體會都會一一發布到我的訂閱號中
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?
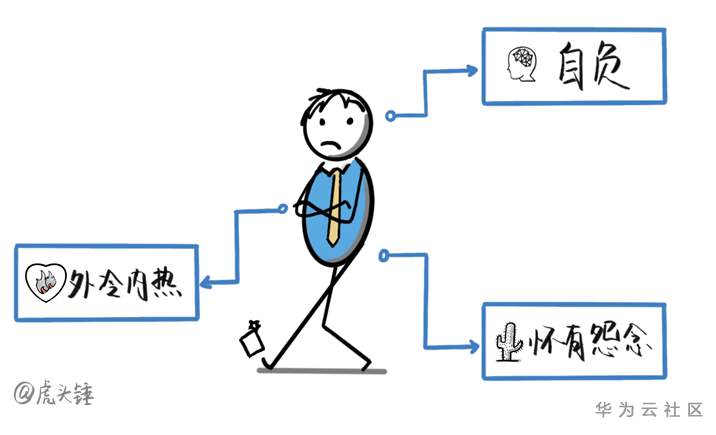
摘要:《Scrum精髓》一書中將Scrum Master的職責總結為六類:敏捷教練,服務型領導,“保護傘”,“清道夫”,過程權威,“變革代言人”。作為“保護傘“,Scrum Master應該保護團隊免受任何干擾,當然也包括團隊內衝突,成員關係等。
拜訪企業的過程中,不少企業領導提到過一個相似的問題:“我們團隊有個人平時總是和我(或者其他成員)對着干,把團隊氛圍搞得很差,Scrum Master應該怎麼引導他們,讓他們好好工作?”
本文就針對這樣的問題來聊聊,團隊中遇到“刺頭”應該怎麼辦?
學生時代班級里總有幾個刺頭,他們惹是生非,擾亂課堂紀律——課堂上講話,接老師話茬,讓老師很是頭疼。企業中,很多團隊也有一兩個成員,他們難以合作,常常捅婁子,給團隊交付帶來不良影響,令管理層也很頭疼。
在交流過程中,筆者從不同人口中了解到不同類型的刺頭,分別有:
技術骨幹通常掌握着項目的核心技術,是開發交付不可或缺的關鍵角色,項目少了他很可能會產生較大的影響。有的技術骨幹對其他人,甚至是領導都愛答不理,和團隊很難溝通協作。
同一時期入職的員工,有的人做上了項目經理,有的人還在原地踏步寫一些基礎代碼
做同一個項目的團隊成員,有的人績效一直是A,獎金豐厚,有的人一直作為“吊車尾”混跡於團隊尾端
兩種情況的後者會存在一部分人表現出對工作消極懈怠,在團隊內傳播負面能量。比如經常抱怨、不滿、碎碎念,對其他團隊成員尤其是新人加以冷嘲熱諷。
大多數人做事講究善始善終,離職時都會做好交接工作。但有小部分人在離職時喜歡破罐子破摔——反正都要走了,還遵守什麼規矩,於是不認真交接,消極怠工,就等着離職辦手續。
正所謂”初生牛犢不怕虎“,有些應屆畢業生在學校做過幾個項目,便感覺自己懂得很多,比其他同學高一等,步入職場后,對其他同事不尊重;還有一些工作經驗少的年輕員工做過幾個技術框架簡單的項目,便感覺自己的技術能力很強,心裏有了“開發就那麼點東西”的錯誤想法,進而輕視日常工作,不服從領導安排。
除個別極端情況比如天生性格不好,大多數刺頭不配合都是有原因的。
以上幾種情況總結起來有如下幾點原因:
筆者接觸過的技術骨幹性格很多都是外冷內熱——他們本身是樂於助人的,但由於他們日常工作很忙或者工作太投入,沒有太多精力去顧及自己對別人的態度,所以給人造成愛答不理的錯覺。
有少數技術牛人因為自己能力突出而變得自負,看不起公司其他人。在這部分人看來團隊成員都應該很輕鬆的完成任務,團隊成員問的問題都沒有技術含量,懶得回答;而且這部分人技術至上,很多公司管理層因為不會開發技術而被他們輕視。
和他們類似,有些年輕員工因為閱歷有限,沒有接觸過複雜的場景,做兩個項目就以為自己能力很突出,表現同上。
做同樣工作,評價有的高有的低,如果不懂得正視自己的缺點,那獲得低評價的人難免心中不服。經常如此,就會感覺自己懷才不遇,對周遭事物存在怨念。
如果員工在一家公司工作的很開心,通常離職時也會站好最後一班崗;離職前搗蛋的員工則多數是因為工作憋了一肚子氣或者和團隊鬧不愉快,離職前這幾天正好把憋得氣全撒出去。
常見的怨念來源還有工作中與其他成員的衝突未得到解決,個人未被團隊關注等。
針對這些問題,Scrum Master應該如何引導呢?
很多人對於Scrum Master的理解是Scrum Master的工作就是幫助團隊召開各種會議,其實這是對Scrum Master工作的一種誤解。Scrum Master除了組織團隊召開會議,還有幫助團隊掃除障礙,促進團隊溝通等工作要做。《Scrum精髓》一書中將Scrum Master的職責總結為六類:敏捷教練,服務型領導,“保護傘”,“清道夫”,過程權威,“變革代言人”。作為“保護傘“,Scrum Master應該保護團隊免受任何干擾,當然也包括團隊內衝突,成員關係等。
敏捷開發中,Scrum Master應該幫助團隊成員建立共同的願景與集體價值觀,幫助每個成員成長並實現其自身價值,同時鼓勵成員們相互尊重、信賴。當遇到上文的問題時,Scrum Master可通過引導的方式加強團隊協作改變團隊現狀。
對於之前提到的問題,Scrum Master可以參考如下措施。
外冷內熱型的團隊成員通常沒有機會與其他成員交流,定期抽出時間比如每次完成發布計劃或者兩個月為間隔,搞一次團隊建設(以下簡稱團建),團建可以讓整個團隊放鬆身心,團建本身也是一個很好的拉近團隊成員之間距離的方法。
團建通常會策劃一系列團隊運動:參与團建的成員以組為單位進行PK,每組成員在團建中為了團隊榮譽,盡情的釋放自己的能量。
團建考驗團隊協作,工作中看起來很難合作的人,可能在遊戲中就很容易合作。如果遊戲中合作愉快,這次合作的經歷很容易就會被帶到工作中,從而推動團隊向一個更积極的方向發展,讓團隊更有凝聚力。
自信的人通常對自己的能力有一個正確的判斷,清楚自己的能力範圍;而自負的人則會高估自己的能力,輕視他人。自負常常源於自己認知有限,自負的刺頭通常認為自己技術能力已經處於行業巔峰,如果讓刺頭意識到自己並沒有比他人強太多,就可以讓其認清事實,調整心態,具體有如下幾種做法:
讓刺頭與能力更強的人一起共事,一方面可以認識到自己的不足,另一方面可以提高自己的境界。
如果刺頭是一個剛工作的年輕人,與老員工一起工作通常會發現老員工思考問題方式,代碼編寫習慣等都和自己不同,Bug也更少。兩人對比如同《賣油翁》里的陳康肅和賣油翁,“無他,唯手熟爾”,習慣源自多年工作經驗的積累——走過的坑多了就知道如何避開了。差距會讓刺頭認識到自己能力不足,還有很多方面需要提升,同時也是年輕人學習的一個好機會。
技術骨幹和能力相當的人共事,可以了解到自身並沒有比其他人強太多,在團隊內也並非無可替代,進而消除其自負心理。
如果公司內沒有比刺頭更強的人,可以讓其處理更難的工作
更強的人應該接受更強的挑戰。Scrum Master可以建議刺頭認領更難的工作,而非其擅長的工作,比如讓其使用行業新技術優化現有產品或者開發一系列工具提高團隊工作效率,建議的同時可以說“你覺得這工作有困難么,大概多久能完成”,或者“我聽說XXX用了一周就作完了,你技術這麼強應該也沒問題吧” 之類能夠刺激到他的話。
如果刺頭能夠按時完成工作,項目一定程度上會從中獲益;如果不能,刺頭自身也會有一種挫敗感——原來自己並非無所不能,自己和別人比還是有差距的,自負的情況也會有所改善。
對工作存有怨念的刺頭,我們應該找到怨念的根因,想辦法疏導。
面對既將離職的刺頭,Scrum Master可以通過稱讚其以往對團隊做出的貢獻,緩和其不滿情緒。雖然雙方合作關係即將結束,但刺頭多少對團隊有些感情,Scrum Master動之以情,曉之以理,在維持其情緒穩定的同時,鼓勵其做到善始善終,站好最後一班崗。
刺頭沒有離職打算:
Scrum Master可以通話一對一談話的形式,為其打開心結。比如可以從最近狀態切入,引出根因(比如績效不如別人好,晉陞沒有別人快),然後解析其他人狀態,將刺頭與其他人形成對比,並列舉差異;Scrum Master可以在最後進行鼓勵比如“如果你能完成XX目標,我覺得你就可以獲得更好的績效,而且你絕對有這個能力完成”,讓刺頭了解與別人差距的同時也得到認可,並且獲得前進的動力。
講一個親身經歷的故事,故事發生在筆者步入職場后的第一個團隊。團隊的項目經理A和技術人員B同年入職,兩人對項目貢獻都很多。論技術A不如B,但是A的職級比B高一級(職級直接影響待遇),B大為不滿,工作中處處與A對着干,消極怠工,嚴重影響項目交付。公司總部領導了解情況后,給B制定了目標,只要B完成目標就提升其職級,最後B努力完成了目標,領導兌現諾言,給B提升了職級。對於B來說,職級上調,其目的已經達到,工作狀態也慢慢變得积極。
Scrum Master也可以找刺頭單獨談話。如果感覺直奔主題不好的話,可以在閑暇之餘對其進行重點關注,比如午休一起打打遊戲等,建立一定社交基礎后再嘗試詢問,然後逐步引導。
如果刺頭負面情緒來源於衝突沒有得到很好解決,Scrum Master可以擔任衝突調解員。Scrum Master站在客觀角度,和衝突雙方一起重新審視衝突,並客觀的給出建議,解決衝突。
在日常工作中,Scrum Master應該多認可,多鼓勵團隊成員,多與成員溝通,營造出輕鬆,融洽的工作氛圍,避免團隊成員因工作產生負面情緒。
如果刺頭始終無法改變,雙方互相耗着必將是一個雙輸的局面。
調整其崗位,讓其在能力範圍內選擇自己想做的工作也是企業中常見的做法。
參考附錄
Kenneth S.Rubin:Scrum精髓. 北京:清華大學出版社
點擊關注,第一時間了解華為雲新鮮技術~
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案
原文compilers-for-free,主要用Ruby來描述,意譯為主,文章太長了,typo/翻譯錯誤等請留言,謝謝。
最後,對編譯器解釋器感興趣的可以看看
我喜歡編程,尤其喜歡元編程。當Ruby開發者討論元編程時他們說的通常是“讓程序來寫程序”,因為Ruby有很多這方面的特性,如 BasicObject#instance_eval, Module#define_method還有BasicObject#method_missing,這讓我們寫的程序能在運行時新增功能。
但是我發現元編程還有另一種更有趣的方面:操縱程序表示的程序(programs that manipulate representations of programs)。這些程序將一些程序的源碼作為輸入,然後在其上做一些事情,如分析,求值,翻譯或者轉換。
這是一個由解釋器、編譯器和靜態分析器組成的世界,我覺得它很迷人,我們能編寫的最純粹、最自指(self-referential)的軟件。
我會給你展示這個世界,並讓你對程序有不同的看法。我不會說一些很複雜的技術,我只會說很酷的技術,告訴你操縱其他程序的程序是有趣的,並希望能激勵你繼續探索這方面的知識。
我們從一個最熟悉的東西開始:程序執行。
假設我們有一個要運行的程序,以及一台運行它的機器。運行程序的第一步是把程序放到機器裏面。然後我們輸入一些數據作為程序的——命令行參數,或者配置文件,或者標準輸入,又或者其它的——總之我們把這些輸入放到了機器裏面。
原則上,程序在機器上執行,讀取輸入,併產生一些輸出:
但實際上,上圖只可能發生在那些硬件能直接執行該程序的情況。對於一個裸機,這意味着除非你的程序是用機器代碼寫的,否則就不可能像上圖那樣。(如果程序使用一些高級語言寫的,那麼機器要想理解這門語言,必須套一個語言虛擬機,比如Java字節碼之於JVM)。我們需要一個解釋器或者編譯器。
解釋器的大致工作機制如下:
我們試着構造一門玩具語言SIMPLE的解釋器,然後逐步討論。SIMPLE非常的直觀,類似於Ruby,但也不完全一樣。下面是一個SIMPLE的示例代碼:
a = 19 + 23
x = 2; y = x * 3
if (a < 10) { a = 0; b = 0 } else { b = 10 }
x = 1; while (x < 5) { x = x * 3 }
和Ruby不同的是,SIMPLE明確區分表達式和語句。表達式求值得到一個值。比如表達式19 + 23求值得到42,表達式x * 3將當前x的值乘以3。語句求值不產生任何值,但是可能有副作用(side effect)導致當前的值被修改。對賦值語句a = 19 + 23求值會將a的值修改為42。
除了賦值外,SIMPLE還有一些語句:序列語句(挨個求值,逗號隔開),條件語句(if (…) { … } else { … }),循環語句(while (…) { … })。這些語句不會直接影響變量的值,但是它們的代碼塊中可能包含賦值語句,這些賦值語句就會影響變量的值。
有一個名為Treetop的Ruby庫,可以很容易的構造解析器,所以我們會使用Treetop來構造SIMPLE的解析器。(這裏不討論Treetop的細節,如果想了解更多請參見Treetop documentation)
在使用Treetop之前,我們還得寫一個語法文件,就像下面:
grammar Simple
rule statement
sequence
end
rule sequence
first:sequenced_statement '; ' second:sequence
/
sequenced_statement
end
rule sequenced_statement
while / assign / if
end
rule while
'while (' condition:expression ') { ' body:statement ' }'
end
rule assign
name:[a-z]+ ' = ' expression
end
rule if
'if (' condition:expression ') { ' consequence:statement
' } else { ' alternative:statement ' }'
end
rule expression
less_than
end
rule less_than
left:add ' < ' right:less_than
/
add
end
rule add
left:multiply ' + ' right:add
/
multiply
end
rule multiply
left:term ' * ' right:multiply
/
term
end
rule term
number / boolean / variable
end
rule number
[0-9]+
end
rule boolean
('true' / 'false') ![a-z]
end
rule variable
[a-z]+
end
end
這個語法文件包含一些rules,它們很好的显示了表達式和語句有哪些。sequence rule是兩個用逗號隔開的語句,while rule表示一個由關鍵字while開頭,後面跟一個圓括號包裹的條件表達式,再後面跟一個花括號包裹的代碼體。assignment rule表示變量名跟一個等號,再跟一個表達式。然後number,boolean和variable這些rules分別表示数字字面值,布爾字面值和變量名字。
當我們寫完語法文件,就可以使用Treetop讀取它,Treetop會生成一個解析器。解析器的代碼用Ruby的class組織,所以我們可以實例化解析器,然後給它一個表示字符串讓它解析。
假設語法文件名字是simple.treetop,然後我們用IRB演示一下:
>> Treetop.load('simple.treetop')
=> SimpleParser
>> SimpleParser.new.parse('x = 2; y = x * 3')
=> SyntaxNode+Sequence1+Sequence0 offset=0, "x = 2; y = x * 3" (first,second):
SyntaxNode+Assign1+Assign0 offset=0, "x = 2" (name,expression):
SyntaxNode offset=0, "x":
SyntaxNode offset=0, "x"
SyntaxNode offset=1, " = "
SyntaxNode+Number0 offset=4, "2":
SyntaxNode offset=4, "2"
SyntaxNode offset=5, "; "
SyntaxNode+Assign1+Assign0 offset=7, "y = x * 3" (name,expression):
SyntaxNode offset=7, "y":
SyntaxNode offset=7, "y"
SyntaxNode offset=8, " = "
SyntaxNode+Multiply1+Multiply0 offset=11, "x * 3" (left,right):
SyntaxNode+Variable0 offset=11, "x":
SyntaxNode offset=11, "x"
SyntaxNode offset=12, " * "
SyntaxNode+Number0 offset=15, "3":
SyntaxNode offset=15, "3"
解析器產生了一個名為具體語法樹(concrete syntax tree)的數據結構,也叫解析樹(parse tree),它包含了一大堆細節,但是實際上我們不需要這麼多細節,我們更希望一個抽象語法樹(abstract syntax tree),它包含更少的細節,更具表現力。
為了產出抽象語法樹,我們需要聲明一些類,它們是最後生成的抽象語法樹的節點。這些通過Struct很容易完成:
Number = Struct.new :value
Boolean = Struct.new :value
Variable = Struct.new :name
Add = Struct.new :left, :right
Multiply = Struct.new :left, :right
LessThan = Struct.new :left, :right
Assign = Struct.new :name, :expression
If = Struct.new :condition, :consequence, :alternative
Sequence = Struct.new :first, :second
While = Struct.new :condition, :body
現在,我們定義了一堆用來表示表達式和語句的node類:簡單的表達式如Number,Boolean只有包含一個value,二元表達式如Add,Multiply有left和right兩個表達式。Assign語句的name表示變量名,還有一個expression表示賦值語句的右側,等等等等。
Treetop還允許這些node類攜帶語義動作,這個語義動作是一個Ruby方法。我們可以用這個特性將具體語法樹的節點轉換為抽象語法樹的節點,讓我們把這個表示語義動作的方面命名為#to_ast。
下面展示了如何定義number,boolean和變量的語義動作方法:
rule number
[0-9]+ {
def to_ast
Number.new(text_value.to_i)
end
}
end
rule boolean
('true' / 'false') ![a-z] {
def to_ast
Boolean.new(text_value == 'true')
end
}
end
rule variable
[a-z]+ {
def to_ast
Variable.new(text_value.to_sym)
end
}
end
當Treetop應用number這條rule時,它繼續調用後面緊跟着的to_ast方法,這個方法把整数字面值轉換為一個整数字符串(使用String#to_i),然後用Number包裹創造處integer常量。#to_ast的實現在boolean和variable的rule中與之類似,它們最終都構造出合適的AST節點。
下面是一些二元表達式的#to_ast實現:
rule less_than
left:add ' < ' right:less_than {
def to_ast
LessThan.new(left.to_ast, right.to_ast)
end
}
/
add
end
rule add
left:multiply ' + ' right:add {
def to_ast
Add.new(left.to_ast, right.to_ast)
end
}
/
multiply
end
rule multiply
left:term ' * ' right:multiply {
def to_ast
Multiply.new(left.to_ast, right.to_ast)
end
}
/
term
end
在上面三個例子中,#to_ast遞歸地調用具體語法樹的左右子表達式的#to_ast,將它們轉換為AST,然後把它們組合起來,放到一個類中。
語句也類似
rule sequence
first:sequenced_statement '; ' second:sequence {
def to_ast
Sequence.new(first.to_ast, second.to_ast)
end
}
/
sequenced_statement
end
rule while
'while (' condition:expression ') { ' body:statement ' }' {
def to_ast
While.new(condition.to_ast, body.to_ast)
end
}
end
rule assign
name:[a-z]+ ' = ' expression {
def to_ast
Assign.new(name.text_value.to_sym, expression.to_ast)
end
}
end
rule if
'if (' condition:expression ') { ' consequence:statement
' } else { ' alternative:statement ' }' {
def to_ast
If.new(condition.to_ast, consequence.to_ast, alternative.to_ast)
end
}
end
一樣的,#to_ast遞歸調用子表達式或者子語句的#to_ast將它們轉換為AST,然後組合成一個正確的AST類。
當所有的#to_ast都定義完成后,我們對具體語法樹的根節點調用#to_ast,遞歸地將整個樹轉換為AST:
>> SimpleParser.new.parse('x = 2; y = x * 3').to_ast
=> #<struct Sequence
first=#<struct Assign
name=:x,
expression=#<struct Number value=2>
>,
second=#<struct Assign
name=:y,
expression=#<struct Multiply
left=#<struct Variable name=:x>,
right=#<struct Number value=3>
>
>
>
儘管Treetop的設計目的是產出具體語法樹,但是用我們定義的node類和語義動作生成的AST是更簡單的結構。代碼x = 2; y = x * 3的AST如下圖所示:
它告訴我們x = 2; y = x * 3 是一個序列語句,包含兩個賦值語句:第一個將Number 2賦值給x,第二個將Variable x和Number 3相乘,即Multiply,結果賦值給y。
現在我們獲得類AST,可以遍歷它並求值。我們為每個AST node類定義一個#evaluate方法,它將對當前節點以及節點的子樹求值。當定義好所有的#evaluate方法后,可以調用AST樹的根節點的#evaluate求值。
下面是Number,Boolean,Variable的#evaluate定義
class Number
def evaluate(environment)
value
end
end
class Boolean
def evaluate(environment)
value
end
end
class Variable
def evaluate(environment)
environment[name]
end
end
environment(環境)參數是一個哈希表,它將每個變量名和值關聯起來。比如說,一個 { x: 7, y: 11 }的environment表示有兩個變量,x和y,它們的值分別是7和11.我們假設每個SIMPLE程序的初始environment是一個空的哈希表。後面我們會看到語句求值如何改變environment。
當我們求值Number或者Boolean時,我們不關心它們是否在environment中,因為我們總是返回一個值,這個值是AST node構建的時候的那個值。如果我們對Variable求值,就得看看environment是否存在這個變量的值。
所以如果我們創建一個Number AST節點,然後用空environment開始求值,我們得到原始的Ruby整數:
>> Number.new(3).evaluate({})
=> 3
Boolean與之類似:
>> Boolean.new(false).evaluate({})
=> false
如果我們對一個名為y的Variable求值,並且environment是之前那個,那麼我們得到11,然而如果environment中的y的值是另一個,那麼對名為y的Variable求值也會得到另一個:
>> Variable.new(:y).evaluate({ x: 7, y: 11 })
=> 11
>> Variable.new(:y).evaluate({ x: 7, y: true })
=> true
下面是二元表達式的#evaluate定義
class Add
def evaluate(environment)
left.evaluate(environment) + right.evaluate(environment)
end
end
class Multiply
def evaluate(environment)
left.evaluate(environment) * right.evaluate(environment)
end
end
class LessThan
def evaluate(environment)
left.evaluate(environment) < right.evaluate(environment)
end
end
這些實現遞歸地求值左右子表達式,然後對結果執行一些運算。如果是Add節點,那麼結果相加;如果是Multiply節點,結果相乘;如果是LessThan節點,結果用<運算符進行比較。
當我們對一個Multiply表達式x * y求值時,environment的x為2,y為3,那麼結果是6:
>> Multiply.new(Variable.new(:x), Variable.new(:y)).
evaluate({ x: 2, y: 3 })
=> 6
如果在相同environment中對LessThan表達式x < y求值,得到結果true:
>> LessThan.new(Variable.new(:x), Variable.new(:y)).
evaluate({ x: 2, y: 3 })
=> true
對於語句,#evaluate稍有不同。因為對語句求值會更新environment的值,而不是像表達式求值那樣簡單的返回一個值。表達式的#evaluate接受一個environment參數,返回一個新的environment,返回的environment與environment參數的差異就是語句的效果導致的。
直接影響變量的語句有Assign:
class Assign
def evaluate(environment)
environment.merge({ name => expression.evaluate(environment) })
end
end
要求值Assign,我們得先求值右邊的表達式,得到一個值,然後使用Hash#merge創建一個修改后的environment。
如果我們在空environment中對x = 2求值,我們會得到一個新的environment,裡面包含了變量名x到值2的映射關係:
>> Assign.new(:x, Number.new(2)).evaluate({})
=> {:x=>2}
類似的,對y = x * 3求值,會在新的environment中關聯變量名y和值6:
>> Assign.new(:y, Multiply.new(Variable.new(:x), Number.new(3))).
evaluate({ x: 2 })
=> {:x=>2, :y=>6}
對序列語句的求值是先求第一個語句,作為中間environment,然後求第二個語句,用中間environment作為第二個語句求值的environment,得到最終的environment:
class Sequence
def evaluate(environment)
second.evaluate(first.evaluate(environment))
end
end
如果序列語句中有兩個賦值,那麼第二個賦值將是最終贏家:
>> Sequence.new(
Assign.new(:x, Number.new(1)),
Assign.new(:x, Number.new(2))
).evaluate({})
=> {:x=>2}
最後,我們還需要為If和While增加#evaluate:
class If
def evaluate(environment)
if condition.evaluate(environment)
consequence.evaluate(environment)
else
alternative.evaluate(environment)
end
end
end
class While
def evaluate(environment)
if condition.evaluate(environment)
evaluate(body.evaluate(environment))
else
environment
end
end
end
If語句根據它的條件選擇求值兩個子語句中的一個。While在條件為true的情況下反覆對循環體求值。
現在,我們已經為所有表達式和語句實現了#evaluate,我們可以解析簡單的SIMPLE程序,然後得到AST。讓我們看看在空environment中對x = 2; y = x * 3求值會得到什麼:
>> SimpleParser.new.parse('x = 2; y = x * 3').
to_ast.evaluate({})
=> {:x=>2, :y=>6}
正如期待的那樣,x和y的最終結果分別是2和6。
讓我們嘗試更複雜的程序:
>> SimpleParser.new.parse('x = 1; while (x < 5) { x = x * 3 }').
to_ast.evaluate({})
=> {:x=>9}
這個程序將初始化x為1,然後反覆的將它翻三倍,直到它大於5。當求值結束,x的值為9,因為9是最小的大於等於5且三倍之於x的值。
以上,我們實現了一個解釋器:解析器讀取源代碼,生成具體語法樹,然後語法制導翻譯將具體語法樹轉換為AST,最後遍歷AST求值。
解釋器是單階段執行(single-stage execution)。我們可以將源程序和其它數據(在SIMPLE的例子中是初始的空environment)作為解釋器的輸入,然後解釋器基於輸入得到輸出:
所有的過程都發生在運行時——程序執行階段
現在我們了解了解釋器是如何工作的,那編譯器呢?
編譯器將源碼解析為AST,然後遍歷它,和解釋器一樣的套路。但是不同的是,編譯器不根據AST節點語義執行代碼,它是生成代碼。
讓我們寫一個SIMPLE到JavaScript的編譯器來解釋這個過程。現在不為AST node定義#evaluate方法,我們定義一個#to_javascript方法,這個方法將所有表達式和語句節點轉換為JavaScript代碼字符串。
下面是Number,Boolean,Variable的#to_javascript定義:
require 'json'
class Number
def to_javascript
"function (e) { return #{JSON.dump(value)}; }"
end
end
class Boolean
def to_javascript
"function (e) { return #{JSON.dump(value)}; }"
end
end
class Variable
def to_javascript
"function (e) { return e[#{JSON.dump(name)}]; }"
end
end
上面的每個#to_javascript都會生成一個JavaScript的函數,這個函數接受一個environment參數e,然後返回一個值。對於Number表達式,返回的是Number所表達的整數:
>> Number.new(3).to_javascript
=> "function (e) { return 3; }"
我們可以獲取編譯后的JavaScript代碼,然後在瀏覽器console界面,或者Node.js REPL中調用JavaScript函數:
// 譯註:下面是JavaScript代碼
> program = function (e) { return 3; }
[Function]
> program({ x: 7, y: 11 })
3
類似的,Boolean AST節點編譯后也是一個JS函數,它返回true或者false:
>> Boolean.new(false).to_javascript
=> "function (e) { return false; }"
SIMPLE的Variable AST節點編譯後會在環境e中查找合適的變量,並返回這個值:
>> Variable.new(:y).to_javascript
=> "function (e) { return e[\"y\"]; }"
很顯然,上面的函數返回的內容取決於環境e的內容:
> program = function (e) { return e["y"]; }
[Function]
> program({ x: 7, y: 11 })
11
> program({ x: 7, y: true })
true
下面是二元表達式的#to_javascript實現
class Add
def to_javascript
"function (e) { return #{left.to_javascript}(e) + #{right.to_javascript}(e); }"
end
end
class Multiply
def to_javascript
"function (e) { return #{left.to_javascript}(e) * #{right.to_javascript}(e); }"
end
end
class LessThan
def to_javascript
"function (e) { return #{left.to_javascript}(e) < #{right.to_javascript}(e); }"
end
end
我們將二元表達式的左右子表達式編譯成JavaScript的函數,然後外面再用JavaScript代碼包裹。當這段代碼真正執行的時候,左右子表達式的js函數都會被調用,得到值,然後兩個值做加法、乘法或者比較運算。讓我們以x * y為例,看看編譯過程:
>> Multiply.new(Variable.new(:x), Variable.new(:y)).to_javascript
=> "function (e) { return function (e) { return e[\"x\"]; }(e) *
function (e) { return e[\"y\"]; }(e); }"
然後將編譯得到的JavaScript代碼(和上面一樣,只是看起來更美觀)放到支持的環境中運行:
> program = function (e) {
return function (e) {
return e["x"];
}(e) * function (e) {
return e["y"];
}(e);
}
[Function]
> program({ x: 2, y: 3 })
6
接下來是語句的#to_javascript,If用的是JavaScript的條件語句,While是JavaScript的循環,諸如此類。最外面和表達式一樣用一個JavaScript函數包裹,該函數接受一個環境e,語句可以更新環境。
class Assign
def to_javascript
"function (e) { e[#{JSON.dump(name)}] = #{expression.to_javascript}(e); return e; }"
end
end
class If
def to_javascript
"function (e) { if (#{condition.to_javascript}(e))" +
" { return #{consequence.to_javascript}(e); }" +
" else { return #{alternative.to_javascript}(e); }" +
' }'
end
end
class Sequence
def to_javascript
"function (e) { return #{second.to_javascript}(#{first.to_javascript}(e)); }"
end
end
class While
def to_javascript
'function (e) {' +
" while (#{condition.to_javascript}(e)) { e = #{body.to_javascript}(e); }" +
' return e;' +
' }'
end
end
之前我們試過解釋器解釋x = 1; while (x < 5) { x = x * 3 },現在我們試試編譯器編譯:
>> SimpleParser.new.parse('x = 1; while (x < 5) { x = x * 3 }').
to_ast.to_javascript
=> "function (e) { return function (e) { while (function (e)
{ return function (e) { return e[\"x\"]; }(e) < function (e)
{ return 5; }(e); }(e)) { e = function (e) { e[\"x\"] =
function (e) { return function (e) { return e[\"x\"]; }(e) *
function (e) { return 3; }(e); }(e); return e; }(e); } return
e; }(function (e) { e[\"x\"] = function (e) { return 1; }(e);
return e; }(e)); }"
儘管編譯后的代碼比源程序還長,但是至少我們已經將SIMPLE代碼轉換為了JavaScript代碼。如果我們在JavaScript的環境中運行編譯后的代碼,我們會獲得和解釋執行一樣的結果——x最終是9:
> program = function (e) {
return function (e) {
while (function (e) {
return function (e) {
return e["x"];
}(e) < function (e) {
return 5;
}(e);
}(e)) {
e = function (e) {
e["x"] = function (e) {
return function (e) {
return e["x"];
}(e) * function (e) {
return 3;
}(e);
}(e);
return e;
}(e);
}
return e;
}(function (e) {
e["x"] = function (e) { return 1; }(e);
return e;
}(e));
}
[Function]
> program({})
{ x: 9 }
這個編譯器相當的傻——想讓它聰明些需要付出更多的努力——但是它向我們展示了如何在只能運行JavaScript的機器上執行SIMPLE程序。
編譯器是雙階段執行(two-stage execution)。首先我們提供源程序,編譯器接受它並生成目標程序作為輸出。接下來,我們拿出目標程序,給它一些輸入,然後允許它,得到最終結果:
編譯和解釋的最終結果是一致的——源代碼加輸入都最終變成了輸出——但是它將執行過程分成了兩個階段。第一個階段是編譯時,當目標程序生成后,第二個階段是運行時,這一階段讀取輸入和目標程序,最終得到輸出。
好消息是一個好的編譯器生成的目標程序會比解釋器執行的更快。將計算過程分成兩個階段免除了運行時的解釋開銷:解析源代碼,構造AST,遍歷AST樹這些過程都在編譯時完成,它們不影響程序運行。
(編譯還有其它性能受益,比如編譯器可以使用更簡潔的數據結構和優化讓目標程序跑的更快,尤其是在確定了目標程序運行的機器的情況下。)
壞消息是編譯會比解釋更難實現,原因有很多:
總結來說,寫解釋器比寫編譯器要簡單,但是解釋程序比執行編譯后的程序要慢。解釋器只有一個階段,只用一門語言,並且動態語言也是沒問題的——如果程序在運行時自身改變了,這沒問題,因為AST可以同步更新,解釋器也工作正常——但是這種簡潔和靈活性會招致運行時性能懲罰。
理想情況下我們想只寫一個解釋器,但是我們程序要想運行的快一些,通常還是需要再寫個編譯器。
程序員總是使用解釋器和編譯器,但還有另一種操縱程序的程序不太為人所知:部分求值器。部分求值器是解釋器和編譯器的混合:
解釋器立即執行程序,編譯器生成程序稍後執行,而部分求值器立刻執行部分代碼,然後剩下的代碼稍後執行。
部分求值器讀取程序(又叫subject program)和程序的輸入,然後只執行部分代碼,這些代碼直接依賴輸入。當這些部分被求值后,剩下的程序部分(又叫residual program)作為輸出產出。
部分求值(partial evaluation)允許我們提取程序的一部分執行。現在我們不必一次提供程序的所有輸入,我們可以只提供一些,剩下的以後提供。
現在,我們不用一次執行整個subject program,我們可以將它和一些程序輸入放到部分求值器裏面。部分求值器將執行subject program的一部分,產生一個residual program;接下來,我們執行residual program,並給它剩下的程序輸入:
部分求值的總體效果是,通過將一些工作從未來(當我們打算運行程序時)移到現在,將單階段執行變成了兩個階段,程序運行時可以少執行一些代碼。
部分求值器將subject program轉換為AST,這一步和解釋器編譯器一樣,接着讀取程序的部分輸入。它分析整個AST找到哪些地方用到了程序的部分輸入,然後這些地方被求值,使用包含求值結果的代碼代替。當部分求值完成時,AST重新轉換為文本形式,即輸出為residual program。
真的構建一個部分求值器太龐大了,不太現實,但是我們可以通過一個示例來了解部分求值的過程。
假設有一個Ruby程序#power,它計算x的n次冪:
def power(n, x)
if n.zero?
1
else
x * power(n - 1, x)
end
end
現在讓我們扮演一個Ruby部分求值器的角色,假設我們已經獲得了足夠的程序輸入,知道將用實參5作為第一個形參n調用power。我們可以很容易地生成一個新版本的方法,稱之為#power_5,其中形參n已被刪除,所有出現n的地方都被替換為5(這也叫常量傳播):
def power_5(x)
if 5.zero?
1
else
x * power(5 - 1, x)
end
end
我們找到了兩個表達式——5.zero?和5 - 1——這是潛在的部分求值對象。讓我們選一個,對5.zero?求值,用結果false代替這個表達式:
def power_5(x)
if false
1
else
x * power(5 - 1, x)
end
end
這個部分求值行為使得我們還能再求值整個條件語句——if false ... else ... end總是走else分支(稀疏常量傳播):
def power_5(x)
x * power(5 - 1, x)
end
現在對5 - 1求值,用常量4代替(常量摺疊):
def power_5(x)
x * power(4, x)
end
現在停一下,因為我們知道#power的行為,這裡有一個優化機會,用#power方法的代碼代替這裏的power(4,x)調用(內聯展開),然後再用4代替所有形參n
def power_5(x)
x *
if 4.zero?
1
else
x * power(4 - 1, x)
end
end
情況和之前一樣,我們知道4.zero?,用false代替:
def power_5(x)
x *
if false
1
else
x * power(4 - 1, x)
end
end
繼續,知道條件語句走else分支:
def power_5(x)
x *
x * power(4 - 1, x)
end
知道4 - 1的值是3:
def power_5(x)
x *
x * power(3, x)
end
如此繼續。通過將#power調用內聯,然後對常量表達式求值,我們能用乘法代替它們,直到0:
def power_5(x)
x *
x *
x *
x *
x * power(0, x)
end
讓我們再手動展開一次:
def power_5(x)
x *
x *
x *
x *
x *
if 0.zero?
1
else
x * power(0 - 1, x)
end
end
我們直到0.zero?是true:
def power_5(x)
x *
x *
x *
x *
x *
if true
1
else
x * power(0 - 1, x)
end
end
這是我們第一次在例子中遇到if true而不是if false的情況,現在選擇then分支,而不是else分支:
def power_5(x)
x *
x *
x *
x *
x *
1
end
最終效果是,我們把#power_5轉換為x重複乘以自身五次,然後乘以1。乘以1對計算沒有影響,所以可以消除它,最終得到的代碼如下:
def power_5(x)
x * x * x * x * x
end
下面是圖形化的過程:
#power加上程序輸入5,最終經過部分求值,得到residual program#power_5。沒有新的代碼產生,#power_5的代碼是由#power組成的,只是重新安排並以新的方式結合在一起。
#power_5的優勢是當輸入為5的時候它比#power跑的更快。#power_5簡單的重複乘以x五次,而#power是執行了五次遞歸的方法調用,零值檢查,條件計算和減法。這些工作都由部分求值器完成,然後結果保留在residual program中,現在redisual program只依賴未知的程序輸入x。
所以,如果我們直到n為5,那麼#power_5就是#power優化改進版。
注意部分求值和部分應用(partial application)是不一樣的。基於部分應用的#power_5和部分求值得到的residual program是不一樣的:
def power_5(x)
power(5, x)
end
通過部分應用,我們固定一個常量到代碼中,成功的將#power轉換為了#power_5,這個實現也是沒問題的:
>> power_5(2)
=> 32
但是這個版本的#power_5不見得比#power更高效——實際上它還會慢一些,因為它引入了額外的方法調用。
或者,我們也可以不定義新的方法,而是用Method#to_proc和Proc#curry將#power柯里化(currying)為一個過程,然後用實參5調用柯里化后的過程:
>> power_5 = method(:power).to_proc.curry.call(5)
=> #<Proc (lambda)>
接着,我們調用部分應用后的代碼,傳入的參數是#power的第二個形參,即x:
>> power_5.call(2)
=> 32
不難看出,部分應用和部分求值很像是,但是仔細審視后可以看出,部分應用是程序內的行為:當我們寫代碼時,部分應用允許我們固定一些參數,然後得到一個方法的更少參數的版本。而部分求值是程序外部的行為:它是一個源碼級別的轉換,通過特化一些程序輸入,可以得到更高效的方法的版本。
部分求值有很多有用的應用場景。固定程序的一些輸入,即特化,可以提供兩方面的好處:我們可以編寫一個通用的、靈活的程序來支持許多不同的輸入,然後,當我們真正知道如何使用這個程序時,我們可以使用一個部分求值器來自動生成一個特化后的版本,該版本移除了代碼的通用性,但是提高了性能。
例如,像nginx或[Apache(http://httpd.apache.org/)這樣的web服務器在啟動時會讀取配置文件。該文件的內容會影響服務器後續每個HTTP請求的處理,因此web服務器必須花費一些執行時間來檢查其配置數據,以決定要做什麼。如果我們對web服務器使用部分求值器專門針對一個特定的配置文件進行部分求值,我們將得到一個新版本,它只執行該文件所說的操作;在啟動期間解析配置文件並在每個請求期間檢查其數據的開銷將不再是程序的一部分。
另一個經典的例子是光線跟蹤。要製作一部攝影機在三維場景中移動的電影,我們可能最終會使用光線跟蹤器渲染數千個單獨的幀。但是如果場景對於每一幀都是相同的,我們可以使用一個部分求值器來專門處理光線跟蹤器對於我們特定場景的描述,我們會得到一個新的光線跟蹤器,它只能渲染該場景。然後,每次我們使用專門的光線跟蹤器渲染幀時,都會避免讀取場景文件、設置表示其幾何體所需的數據結構以及對光線在場景中的行為做出與相機無關的決策的開銷。
一個更實際(有一些爭議)的例子是OpenGL管道。在OS X中,OpenGL管道的一部分是用LLVM中間語言編寫的,這其中包括一些GPU硬件就實現了的。不管GPU支持與否,都可以用軟件的方式實現,而有了部分求值,Apple公司可以對LLVM部分求值,刪除掉特定GPU上不需要的代碼,剩下的代碼是硬件沒有直接實現的。
首先,我想說一個cool story。
1971年,Yoshihiko Futamura在Hitachi Central Research Laboratory工作時發表了一些有趣的論文。他在思考部分求值如何更早的處理subject program的一些輸入,然後產出後續可以執行的residual program。
具體來說,Futamura將解釋器作為部分求值的輸入並思考了一些問題。他意識到解釋器只是一個計算機程序而已,它讀取輸入,執行,然後得到輸出。解釋器的輸入之一是源碼,但是除了這個比較特別外解釋器和普通程序沒啥兩樣。
他在思考,如果我們先用部分求值器做一些解釋器的工作,會發生什麼?
如果我們使用部分求值器特化解釋器和它的某個程序的輸入,我們會得到residual program。然後,我們可以用程序的剩下的輸入加上residual program,得到最終結果:
最終效果和用解釋器直接運行程序一樣,只是現在單階段執行變成了兩階段。
Futamura注意到residual program讀取剩下的程序輸入,然後產生輸出,我們通常把這個residual program稱為目標程序——一個能被底層機器直接執行的源程序的新版本。這意味着部分求值器讀取源程序,產出目標程序,它實際上扮演了編譯器的角色。
看起來難以置信。它是怎麼工作的?讓我們看一個示例。下面是SIMPLE解釋器的top level環境:
source, environment = read_source, read_environment
Treetop.load('simple.treetop')
ast = SimpleParser.new.parse(source).to_ast
puts ast.evaluate(environment)
解釋器讀取源程序和初始化environment(從哪讀的我們不關心)。它加載Treetop語法文件,實例化解析器,然後解析器產出AST,然後對AST求值並輸出。#evaluate的定義和前面解釋器小結是一樣的。
讓我們想象一下將這個解釋器和SIMPLE源代碼 x = 2; y = x * 3作為輸入放入Ruby部分求值器。這意味這上面代碼中的#read_source將返回字符串 x = 2; y = x * 3,所以我們可以用字符串代替它:
source, environment = 'x = 2; y = x * 3', read_environment
Treetop.load('simple.treetop')
ast = SimpleParser.new.parse(source).to_ast
puts ast.evaluate(environment)
現在,讓我手動做一下複寫傳播,由於source變量只在代碼中用到了一次,我們可以完全消除它,用值代替:
environment = read_environment
Treetop.load('simple.treetop')
ast = SimpleParser.new.parse('x = 2; y = x * 3').to_ast
puts ast.evaluate(environment)
構造AST的數據都已經備起了,Treetop語法文件也準備好了,現在我們還知道待解析的字符串是什麼。讓我們手動求值表達式,創建一個手工AST代替解析過程:
environment = read_environment
ast = Sequence.new(
Assign.new(
:x,
Number.new(2)
),
Assign.new(
:y,
Multiply.new(
Variable.new(:x),
Number.new(3)
)
)
)
puts ast.evaluate(environment)
我們將解釋器簡化為讀取環境、構建AST字面值、在AST根節點上調用#evaluate。
在特定節點上調用#evaluate會發生什麼?我們早已直到每種節點的#evaluate定義,現在可以遍歷樹,然後找到AST節點的#evaluate調用,進行部分求值,和我們之前對#power做的差不多。AST包含了所有我們需要的數據,所以我們可以逐步將所有的#evaluate歸納為幾行Ruby代碼:
對於Number和Variable,我們直到它的值和變量名字,所以我們可以將這些信息傳播到其它節點。對於Multiply和Assign節點,我們可以內聯方法調用。對於序列語句,我們可以先內聯first.evaluate再內聯second.evaluate,使用臨時變量保持中間environment。
下面的代碼隱藏了大量的細節,但重要的是,我們擁有最終代碼和數據,它們可以幫助我們對AST根節點的#evaluate方法進行部分求值:
def evaluate(environment)
environment = environment.merge({ :x => 2 })
environment.merge({ :y => environment[:x] * 3 })
end
讓我們回到解釋器的主要代碼:
environment = read_environment
ast = Sequence.new(
Assign.new(
:x,
Number.new(2)
),
Assign.new(
:y,
Multiply.new(
Variable.new(:x),
Number.new(3)
)
)
)
puts ast.evaluate(environment)
既然我們已經生成了AST根節點的#evaluate方法,現在我們可以對ast.evaluate(environment)部分求值,方法是展開這個調用:
environment = read_environment
environment = environment.merge({ :x => 2 })
puts environment.merge({ :y => environment[:x] * 3 })
這個Ruby代碼和原始的SIMPLE代碼產生了相同的行為:它將x設置為2,將y設置為x乘以3,x和y都存放到environment中。所以,從某種意義上說,我們通過對解釋器進行部分求值,將SIMPLE程序編譯為Ruby代碼——雖然還有一些其它environment的內容,但是總之,我們最終的Ruby代碼做的還是x = 2; y = x * 3這件事。
和#power那個例子一樣,我們沒有寫Ruby代碼,residual program是重新安排解釋器的代碼並以新的方式結合在一起,這樣它就完成了與最初的SIMPLE程序相同的功能。
這種方式被稱為第一二村映射(first futamura projection):如果我們將源代碼和解釋器一起進行部分求值,我們將得到目標程序。
Futamura很高興他意識到了這一點。然後他繼續思考更多,他繼續意識到將源代碼和解釋器一起進行部分求值得到目標程序這件事本身,其實就是給一個程序多個參數。如果我們先使用部分求值來完成部分求值器的一些工作,然後通過運行剩餘程序來完成其餘的工作,會發生什麼情況?
如果我們用部分求值來特化部分求值器的一個輸入—— 解釋器——我們會得到residual program。然後後面我們可以運行這個residual program,將源程序作為輸入,得到目標程序,最後運行目標程序,傳入剩餘程序輸入,得到最終結果:
總體的效果與給出程序輸入,直接用解釋器運行源程序行為一致,但現在執行已分為三個階段。
Futamura注意到residual program讀取源程序產生目標程序,這個過程是我們常說的編譯器做的事情。這意味着部分求值器將解釋器作為輸入,輸出來編譯器。換句話說,部分求值器此時成了編譯器生成器。
這種方式被稱為第二二村映射(second futamura projection):如果我們將部分求值器和解釋器一起進行部分求值,我們將得到編譯器。
Futamura很高興他意識到了這一點。然後他繼續思考更多,他繼續意識到將部分求值器和解釋器一起進行部分求值得到編譯器這件事本身,其實就是給一個程序多個參數。如果我們先使用部分求值來完成部分求值器的一些工作,然後通過運行剩餘程序來完成其餘的工作,會發生什麼情況?
如果我們用部分求值來特化部分求值器的一個輸入—— 部分求值器——我們會得到residual program。然後後面我們可以運行這個residual program,將解釋器作為輸入,得到編譯器,最後運行編譯器,將源程序作為輸入得到目標程序,在運行目標程序,給它剩下的程序輸入,得到最終結果:
總體的效果與給出程序輸入,直接用解釋器運行源程序行為一致,但現在執行已分為四個階段。
Futamura注意到residual program讀取解釋器產生編譯器,這個過程是我們常說的編譯器做的事情。這意味着部分求值器產出來一個編譯器生成器。換句話說,部分求值器此時成了編譯器生成器的生成器。
這種方式被稱為第三二村映射(third futamura projection):如果我們將部分求值器和部分求值器一起進行部分求值,我們將得到編譯器生成器。
謝天謝地,我們不能再進一步了,因為如果我們重複這個過程,我們仍然會對部分求值器本身進行部分求值。只有三個二村映射。
二村映射非常有趣,但不是說有了它編譯器工程師就是多餘的了。部分求值是一種適用於任何計算機程序的完全通用的技術;當應用於解釋器時,它可以消除解析源代碼和操作AST的開銷,但它不會自動地發明和創造具備工業級水平的編譯器的數據結構和優化。 我們仍然需要聰明的人寫編譯器,使我們的程序盡可能快地運行。
如果你想了解更多關於部分求值的知識,有一本叫做“Partial Evaluation and Automatic Program Generation”的免費書籍詳細的討論了它。LLVM的JIT,PyPy工具鏈的一部分——即RPython和VM以及它底層依賴的JIT)——也使用相關技術讓程序更高效執行。這些項目與Ruby直接相關,因為Rubinius依賴LLVM,還有一個用Python編寫的Ruby實現,名為Topaz,也依賴PyPy工具鏈。
撇開部分求值不談,Rubinius和JRuby也是高質量的編譯器,代碼很有趣,可以免費下載。如果你對操縱程序的程序感興趣,你可以深入Rubinius或JRuby,看看它們是如何工作的,並且(根據Matz的RubyConf 2013主題演講提到的)參与它們的開發。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※教你寫出一流的銷售文案?
var的預解釋機制function 的預解釋機制預解釋也叫預聲明,是提前解釋聲明的意思;預解釋是針對變量和函數來說的;但是變量和function的的預解釋是兩套不同的機制;
var的預解釋機制var a=1
1、代碼運行之前,先掃描有沒有帶var關鍵字的變量名,有的話,為這個變量名在內存里開一個空間;這時候變量名a是不代表任何值的;用undefined來表示;undefined是一個標識符/記號,表示找不到這個變量名所代表的數據;不存在的意思;這個階段叫變量的聲明;
2、當代碼運行的時候,則給數據1開闢一個內存空間;
3、讓數據1和變量名a綁定在一起;變量類型指的就是數據類型;按照js語言的原理來說變量類型有undefined類型;但是數據類型是沒有undefined這種數據類型的;只有”undecided”這種字符串類型(字符串類型是數據類型的一種);同理也沒有unll這個數據類型,但是有”null”這種字符串類型;
var num;
//1、聲明(declare):var num; ->告訴瀏覽器在當前作用域中有一個num的變量了,如果一個變量只是聲明了但是沒有賦值,默認的值是undefined
console.log(num);//->undefined
num = 12;
//2、定義(defined):num=12; ->給我們的變量進行賦值
console.log(num);//->12
//變量提前使用的話,就是undefined
console.log(testStr);//undefined
var testStr="22222222"
function 關鍵字的預解釋步驟function fn(){……}
在代碼執行之前,把所有的帶function關鍵字的腳本都掃描一遍,然後定義變量;並且同時給變量賦值;
1、函數的定義只是保存一些字符串;預解釋的時候在內存里保存fn大括號裏面的字符串;
2、代碼運行時候,讀到fn()時候,這個時候就是函數的運行;函數的運行,會先開闢一個堆內存把字符串當做代碼在堆內存中再次運行,函數產生的作用域內還會再進行預解釋和代碼運行;
函數如果多次執行;會產生多個作用域;但是產生的多個作用域裏面的內容都是相互獨立的;互相沒有關係;(在原型和原型鏈時候再仔細研究原理;)
fn(100,200);//->可以在上面執行,因為預解釋的時候聲明+定義就已經完成了
function fn(num1, num2) {
var total = num1 + num2;
console.log(total);
}
var和function關鍵字的在預解釋的時候操作還是不一樣的
var -> 在預解釋的時候只是提前的聲明了這個變量,只有當代碼執行的時候才會完成賦值操作function -> 在預解釋的時候會提前的把聲明加定義都完成了(在代碼執行的時候遇到定義的代碼直接的跳過)[重要]剛開始只對window下的進行預解釋,fn函數中目前存儲的都是字符串,所以var total沒啥實際的意義,所以不進行預解釋 -> “預解釋是發生在當前作用域下的”
綜合題;
console.log(obj);//->undefined
var obj = {name: "xie", age: 25};
function fn(num1, num2) {//代碼執行到這一行的時候直接的跳過這一塊的代碼,因為在預解釋的時候我們已經完成了聲明加定義
var total = num1 + num2;
console.log(total);
}
var num1 = 12;
fn(num1, 100);//執行fn,把全局變量num1的值賦值給形參num1,把100賦值給形參num2
下面是一個預解釋思路
var a,
b = 0,
fn = function () {
var a = b = 2;
};
fn();
console.log(a, b);
把上面解析成下面就好理解了
var a;
window.b = 0;
window.fn = function () {
//var a = b = 2;
var a = 2;//a是私有的和全局沒關係
b = 2;//b是全局的
};
fn();//window.fn()
console.log(a, b);//undefined 2
1、不管條件是否成立都要進行預解釋
console.log(a);//->undefined
if (!!("a" in window)) {//"a" in window -> true
var a = "xie";
}
console.log(a);//->xie
例子中的if是不成立的,預解釋的時候,碰到非
functon內的var,都會聲明,無論你寫在if else 還是別的判斷里; 假設if語句起作用的話,那麼第一次log(a)的時候,就會報錯了(沒有聲明的變量,是不能直接用的,除非typeof),而聲明並且沒有賦值的表現才是undefined;假設不成立; 最開始總結的預解釋步驟:代碼運行之前,先掃描有沒有帶var關鍵字的變量名,有的話,為這個變量名,在內存里開一個空間;預解釋是發生在代碼執行前的,所以if根本阻擋不了預解釋;
2、預解釋只發生在”=“的左邊,只把左邊的進行預解釋,右邊的是值是不進行預解釋的
匿名函數之函數表達式:把函數定義的部分當做值賦值給一個變量或者元素的事件
fn1();//->undefined() Uncaught TypeError: fn is not a function JS中只有函數可以執行 && JS上面的代碼如果報錯了,在不進行任何的特殊處理情況下我們下面的代碼都不在執行了
var fn1 = function () {
console.log("ok");
};
fn1();
//預解釋的時候:fn=xxxfff000
fn2();//->"ok"
function fn2() {
console.log("ok");
}
fn2();//->"ok"
預解釋的時候:var fn1 = function()... ->fn的默認值是undefined;這裏即使有function,也是不能進行預解釋的
3、函數體中return下面的代碼都不在執行了,但是下面的代碼需要參加預解釋;而return後面的東西是需要處理的,但是由於它是當做一個值返回的,所以不進行預解釋;
function fn() {
console.log(total);
return function sum() {};//return是把函數中的值返回到函數的外面,這裡是把function對應的內存地址返回的到函數的外面,例如:return xxxfff111;函數體中return下面的代碼都不在執行了
var total = 10;
console.log(total);
}
4、匿名函數的function在全局作用域下是不進行預解釋的;
匿名函數之自執行函數:定義和執行一起完成了;函數內的聲明,只是在函數內使用;
(function(num){
var testStr="test"+num;
console.log(num);
})(100);
console.log(testStr);// testStr is not defined
預解釋:
var fn; 聲明
fn = xxxfff000; [聲明]不用了+定義
fn = xxxfff111; [聲明]不用了+定義
// ->fn=xxxfff111
var fn = 12;//window.fn=12
function fn() {//window.fn=function(){}
}
JS中作用域只有兩種:
{name:“”} if(){} for(){} while(){} switch(){} 這些都不會產生作用域;ES6可以用let形成塊級作用域;http://www.cnblogs.com/snandy/archive/2015/05/10/4485832.html
// 涉及this的指向和閉包
var num = 20;
var obj = {
num: 37,
fn: (function (num) {
this.num *= 3; // window.num * 3 = 60
// num += 15;
var num = 45;
return function () {
this.num *= 4;
num += 20; // 調用父作用域的num (45+20)
console.log(num);
};
})(num), //->把全局變量num的值20賦值給了自執行函數的形參,而不是obj下的30,如果想是obj下的30,我們需要寫obj.num
};
var fn = obj.fn;
fn(); //->65 , 執行了第1次=> window.num = 240
obj.fn(); //->85 閉包(65+20) // 執行了第2次=> obj.num = 37*4 = 148
console.log(window.num, obj.num); // 240,148
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※教你寫出一流的銷售文案?
※超省錢租車方案
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※產品缺大量曝光嗎?你需要的是一流包裝設計!
Mybatis在設計上處處都有用到的緩存,而且Mybatis的緩存體系設計上遵循單一職責、開閉原則、高度解耦。及其精巧,充分的將緩存分層,其獨到之處可以套用到很多類似的業務上。這裏將主要的緩存體系做一下簡單的分析筆記。以及藉助Mybatis緩存體系的學習,進一步窺探責任鏈派發模式企業級實踐,以及對象循環依賴場景下如何避免裝載死循環的企業級解決方案。
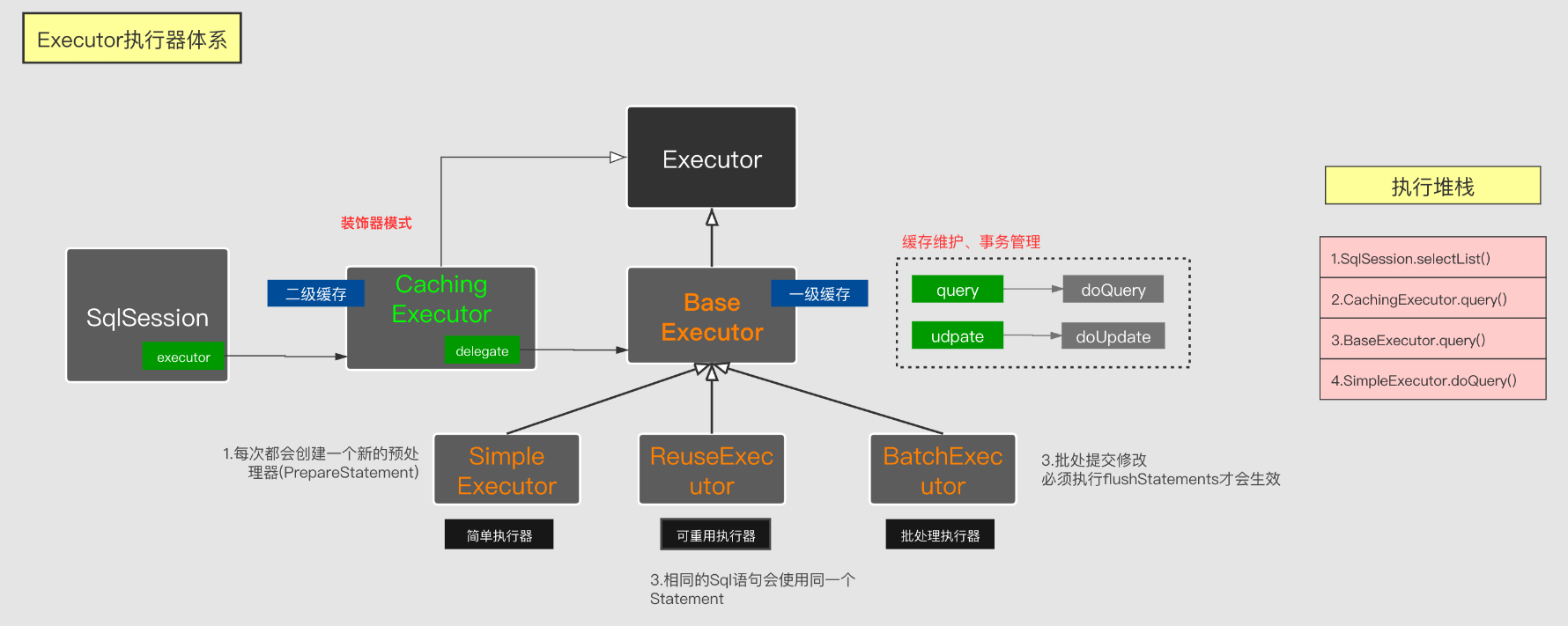
先來一張之前的執行體系圖:
對照這張執行圖,不難看出,其實對於一次Mybatis查詢調用,即SqlSession -> SimpleExecutor/ReuseExecutor/BatchExecutor -> JDBC,其實緩存就是在SqlSession到Executor*之間做一層截獲請求的邏輯。從宏觀上很好理解。CachingExecutor作為BaseExecutor的一個前置增強裝飾器,其增強的功能就是,判斷是否命中了緩存,如果命中緩存,則不進行BaseExecutor的執行派發。
1 public class CachingExecutor implements Executor { 2 // BaseExecutor 3 private final Executor delegate; 4 public CachingExecutor(Executor delegate) { 5 this.delegate = delegate; 6 delegate.setExecutorWrapper(this); 7 } 8 @Override 9 public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) 10 throws SQLException { 11 Cache cache = ms.getCache(); 12 if (cache != null) { 13 flushCacheIfRequired(ms); 14 if (ms.isUseCache() && resultHandler == null) { 15 ensureNoOutParams(ms, boundSql); 16 List<E> list = (List<E>) tcm.getObject(cache, key); 17 if (list == null) { 18 list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); 19 tcm.putObject(cache, key, list); // issue #578 and #116 20 } 21 return list; 22 } 23 } 24 // 如果未命中緩存則向BaseExecutor派發 25 return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); 26 } 27 }
所以由此來看,mybatis的緩存是先嘗試命中CachingExecutor的二級緩存,如果未命中,則派發個BaseExecutor,下來才會去嘗試命中一級緩存。由於一級緩存比較簡單,我們先來看一級緩存。
之前執行器的那一節講過,Mybatis的執行器和SqlSession都是一對一的關係
1 public class DefaultSqlSession implements SqlSession { 2 // ... 3 private final Executor executor; 4 // ... 5 }
而每個執行器裡邊用一個成員變量來做緩存容器
1 public abstract class BaseExecutor implements Executor { 2 // ... 3 protected PerpetualCache localCache; 4 // ... 5 }
那麼也就是說,一旦SqlSession關閉,即對象銷毀,必然BaseExecutor對象銷毀,所以一級緩存容器跟着銷毀。由此可以推到出:一級緩存是SqlSession級別的緩存。也就是要命中一級緩存,必須是同一個SqlSession,而且未關閉。
再來看一下一級緩存是如何設置緩存的:
1 public abstract class BaseExecutor implements Executor { 2 protected PerpetualCache localCache; 3 @Override 4 public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException { 5 BoundSql boundSql = ms.getBoundSql(parameter); 6 CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql); 7 return query(ms, parameter, rowBounds, resultHandler, key, boundSql); 8 } 9 @Override 10 public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { 11 ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId()); 12 if (closed) { 13 throw new ExecutorException("Executor was closed."); 14 } 15 if (queryStack == 0 && ms.isFlushCacheRequired()) { 16 clearLocalCache(); 17 } 18 List<E> list; 19 try { 20 queryStack++; 21 list = resultHandler == null ? (List<E>) localCache.getObject(key) : null; 22 if (list != null) { 23 handleLocallyCachedOutputParameters(ms, key, parameter, boundSql); 24 } else { 25 list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql); 26 } 27 } finally { 28 queryStack--; 29 } 30 if (queryStack == 0) { 31 for (DeferredLoad deferredLoad : deferredLoads) { 32 deferredLoad.load(); 33 } 34 // issue #601 35 deferredLoads.clear(); 36 if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) { 37 // issue #482 38 clearLocalCache(); 39 } 40 } 41 return list; 42 } 43 }
通過這一段源碼,可以看到,是在第6行去構建緩存key,在第21行嘗試獲取緩存。構建緩存key,取決於四個維度:MappedStatement(同一個statementId)、parameter(同樣的查詢參數)、RowBounds(同樣的行數)、BoundsSql(同樣的SQL),加上上邊SqlSession的條件,一級緩存的命中條件為:相同的SqlSession、statementId、parameter、行數、Sql,才能命中一級緩存。
這裡在說一句題外話,就是當mybatis與Spring集成時,SqlSession的管理就交給Spring框架了,每次Mybatis的查詢都會由Spring框架新建一個Sqlsession供mybatis用,看起來一級緩存永遠失效。解決辦法就是給查詢加上事務,當加上事務的時候,Spring框架會保證在一個事務裡邊只提供給mybatis同一個SqlSession對象。
再看下一級緩存何時會被刷新掉,來上源碼:
1 public abstract class BaseExecutor implements Executor { 2 protected PerpetualCache localCache; 3 @Override 4 public void close(boolean forceRollback) { 5 try { 6 try { 7 rollback(forceRollback); 8 } finally { 9 if (transaction != null) { 10 transaction.close(); 11 } 12 } 13 } catch (SQLException e) { 14 log.warn("Unexpected exception on closing transaction. Cause: " + e); 15 } finally { 16 transaction = null; 17 deferredLoads = null; 18 localCache = null; 19 localOutputParameterCache = null; 20 closed = true; 21 } 22 } 23 @Override 24 public int update(MappedStatement ms, Object parameter) throws SQLException { 25 ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId()); 26 if (closed) { 27 throw new ExecutorException("Executor was closed."); 28 } 29 clearLocalCache(); 30 return doUpdate(ms, parameter); 31 } 32 @Override 33 public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { 34 if (queryStack == 0 && ms.isFlushCacheRequired()) { 35 clearLocalCache(); 36 } 37 if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) { 38 clearLocalCache(); 39 } 40 } 41 @Override 42 public void commit(boolean required) throws SQLException { 43 clearLocalCache(); 44 } 45 46 @Override 47 public void rollback(boolean required) throws SQLException { 48 if (!closed) { 49 try { 50 clearLocalCache(); 51 flushStatements(true); 52 } finally { 53 if (required) { 54 transaction.rollback(); 55 } 56 } 57 } 58 } 59 60 @Override 61 public void clearLocalCache() { 62 if (!closed) { 63 localCache.clear(); 64 localOutputParameterCache.clear(); 65 } 66 }
對於這段源碼,清除緩存的場景,着重關注一下clearLocalCache的調用的地方:
即觸發更新操作(第29行)、配置flushCache=true(第35行)、配置緩存作用於為STATEMENT(第38行)、commit時候(第42行)、rollback時候(第50行)、執行器關閉時候(第7行)都會清除一級緩存。
循環依賴的情況處處可見,比如:一個班主任,下邊有多個學生,每個學生又有一個對應的班主任。
對於班主任和學生這種場景,在mybatis層面屬於典型的嵌套子查詢。mybatis在處理嵌套查詢的時候,都會查詢,然後在設置屬性的時候,如果發現有子查詢,則發起子查詢。那麼,如果不加特殊干預,這種場景將會陷入設置屬性觸發查詢的死循環中。
1 <select id="selectHeadmasterById" resultMap="teacherMap"> 2 select * from teacher where id = #{id} 3 </select> 4 <resultMap id="teacherMap" type="Teacher" autoMapping="true"> 5 <result column="name" property="name"/> 6 <collection property="students" column="id" select="selectStudentsByTeacherId" fetchType="eager"/> 7 </resultMap> 8 <select id="selectStudentsByTeacherId" resultMap="studentMap"> 9 select * from student where teacher_id = #{teacherId} 10 </select> 11 <resultMap id="studentMap" type="comment"> 12 <association property="teacher" column="teacher_id" select="selectHeadmasterById" fetchType="eager"/> 13 </resultMap>
mybatis在處理這種情況的時候,巧妙的用了一個臨時一級緩存佔位符與延遲裝載(不同於懶加載),解決了查詢死循環的問題。這裏我們直接上源碼:
每次查詢,如果沒有命中有效緩存(即非佔位符緩存)mybatis都會事先給一級緩存寫入一個佔位符,待數據庫查詢完畢后,再將真正的數據覆蓋掉佔位符緩存。
1 public abstract class BaseExecutor implements Executor { 2 protected ConcurrentLinkedQueue<DeferredLoad> deferredLoads; 3 protected PerpetualCache localCache; 4 protected int queryStack; 5 @Override 6 public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { 7 ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId()); 8 if (closed) { 9 throw new ExecutorException("Executor was closed."); 10 } 11 if (queryStack == 0 && ms.isFlushCacheRequired()) { 12 clearLocalCache(); 13 } 14 List<E> list; 15 try { 16 queryStack++; 17 list = resultHandler == null ? (List<E>) localCache.getObject(key) : null; 18 if (list != null) { 19 handleLocallyCachedOutputParameters(ms, key, parameter, boundSql); 20 } else { 21 // 如果未獲取到緩存則查庫 22 list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql); 23 } 24 } finally { 25 queryStack--; 26 } 27 if (queryStack == 0) { 28 for (DeferredLoad deferredLoad : deferredLoads) { 29 deferredLoad.load(); 30 } 31 deferredLoads.clear(); 32 if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) { 33 clearLocalCache(); 34 } 35 } 36 return list; 37 } 38 }
如上Query方法的第22行進去:
1 private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { 2 List<E> list; 3 // 查庫之前先設置佔位符緩存 4 localCache.putObject(key, EXECUTION_PLACEHOLDER); 5 try { 6 list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql); 7 } finally { 8 localCache.removeObject(key); 9 } 10 localCache.putObject(key, list); 11 if (ms.getStatementType() == StatementType.CALLABLE) { 12 localOutputParameterCache.putObject(key, parameter); 13 } 14 return list; 15 }
BaseExecutor.queryFromDataBase方法的第6行,會觸發數據庫查詢,緊接着會進入結果值設定的邏輯。那麼首先會探測有無嵌套的子查詢,如果有,則前一步主查詢暫時等待,立即發起子查詢。
1 private Object getNestedQueryMappingValue(ResultSet rs, MetaObject metaResultObject, ResultMapping propertyMapping, ResultLoaderMap lazyLoader, String columnPrefix) 2 throws SQLException { 3 final String nestedQueryId = propertyMapping.getNestedQueryId(); 4 final String property = propertyMapping.getProperty(); 5 final MappedStatement nestedQuery = configuration.getMappedStatement(nestedQueryId); 6 final Class<?> nestedQueryParameterType = nestedQuery.getParameterMap().getType(); 7 final Object nestedQueryParameterObject = prepareParameterForNestedQuery(rs, propertyMapping, nestedQueryParameterType, columnPrefix); 8 Object value = null; 9 if (nestedQueryParameterObject != null) { 10 final BoundSql nestedBoundSql = nestedQuery.getBoundSql(nestedQueryParameterObject); 11 final CacheKey key = executor.createCacheKey(nestedQuery, nestedQueryParameterObject, RowBounds.DEFAULT, nestedBoundSql); 12 final Class<?> targetType = propertyMapping.getJavaType(); 13 // 判斷當前的子查詢是否和之前的某一步主查詢相同 14 if (executor.isCached(nestedQuery, key)) { 15 executor.deferLoad(nestedQuery, metaResultObject, property, key, targetType); 16 value = DEFERRED; 17 } else { 18 final ResultLoader resultLoader = new ResultLoader(configuration, executor, nestedQuery, nestedQueryParameterObject, targetType, key, nestedBoundSql); 19 if (propertyMapping.isLazy()) { 20 lazyLoader.addLoader(property, metaResultObject, resultLoader); 21 value = DEFERRED; 22 } else { 23 // 立即發起子查詢 24 value = resultLoader.loadResult(); 25 } 26 } 27 } 28 return value; 29 }
這塊重點關注第13行和第23行。其中第23行又會遞歸到上邊BaseExecutor.query代碼片段的第22行。如果getNestedQueryMappingValue代碼段走的是滴15行邏輯,那麼,會對應BaseExecutor.query代碼片段的第28行。這塊遞歸比較繞。下來做下通俗的解釋:
首先查詢班主任的主查詢給一級緩存寫入一個佔位符緩存,然後去查庫,然後設定屬性,如果沒有嵌套子查詢,那麼到這裏就把設置好屬性的值寫入覆蓋剛才一級佔位符緩存。流暢完畢。
但是恰好有嵌套子查詢,所以查詢班主任的主查詢就停在設置屬性這一步,然後又發起一次查詢,查詢學生,然後又進入查詢學生設定屬性的方法。
設定學生屬性方法又發現又有嵌套子查詢,所以有發起一次學生查詢班主任的查詢操作,又進入到設定屬性這塊,但是發現一級緩存裡邊有前邊住查詢的站位緩存。所以沒有在查庫,而是將本次子查詢放入延遲裝載的容器裡邊。本次子查詢結束。緊接着前一步子查詢(老師查學生)結束。
緊接着查詢老師的住查詢設定屬性完畢,並將自己的結果覆蓋之前寫入的站位緩存。同時啟動了延時裝載的邏輯,延時裝載就是從一級緩存取出剛才查詢老師的一級緩存數據(老師),給第二步子查詢(學生)做一下MetaObject屬性設置。
說的通俗一點:主查詢(查班主任)執行時先寫入站位緩存,緊接着掛起,發起第一個嵌套子查詢(用老師查學生),緊接着該子查詢再掛起,發起學生查老師,但是發現第一步主查詢有一級緩存(站位緩存),那麼本次子查詢自動加入延遲裝載隊列,然後終結改子查詢,等待主查詢真正查完,然後延遲裝載器再從緩存取出數據給第一個子查詢(老師查學生)進行屬性設定。
說了這麼多,肯定暈車了,這裏給出一個時序圖:
總結一下:
1、佔位符緩存作用在於標識與當前查詢相同的前邊的嵌套查詢。比如:查詢學生所屬班主任,發現前邊的主查詢就是查詢班主任,所以就不在執行班主任查詢。等待真正的班主任查詢完畢,我們只需去緩存裡邊取即可。所以我們不執行查詢,只是將本次屬性設置放入延遲裝載隊列即可。
2、queryStack用來記錄當前查詢處於嵌套的第幾層。當queryStack == 0時,證明整個查詢已經回歸到最初的主查詢上,此時,所有過程中需要延遲裝載的對象,都能啟動真實裝載了。
3、一級緩存在解決嵌套子查詢屬性設置循環依賴上啟至關作用。所以以及緩存是不能完全關閉的。但是我們可以設置:LocalCacheScope.STATEMENT,來讓一級緩存及時清空。參見源碼
1 public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { 2 // ... 3 try { 4 queryStack++; 5 list = resultHandler == null ? (List<E>) localCache.getObject(key) : null; 6 if (list != null) { 7 handleLocallyCachedOutputParameters(ms, key, parameter, boundSql); 8 } else { 9 list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql); 10 } 11 } finally { 12 queryStack--; 13 } 14 if (queryStack == 0) { 15 for (DeferredLoad deferredLoad : deferredLoads) { 16 deferredLoad.load(); 17 } 18 deferredLoads.clear(); 19 // 設置LocalCacheScope.STATEMENT來及時清空緩存 20 if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) { 21 clearLocalCache(); 22 } 23 } 24 return list; 25 }
來先上一個二級緩存的執行流程:
二級緩存是BaseExecutor的前置增強包裝類CachingExecutor裡邊實現的,即如果從CachingExecutor裡邊命中緩存,則不進行BaseExecutor的派發(如下第14行)。
1 public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) 2 throws SQLException { 3 Cache cache = ms.getCache(); 4 if (cache != null) { 5 flushCacheIfRequired(ms); 6 if (ms.isUseCache() && resultHandler == null) { 7 ensureNoOutParams(ms, parameterObject, boundSql); 8 @SuppressWarnings("unchecked") 9 List<E> list = (List<E>) tcm.getObject(cache, key); 10 if (list == null) { 11 list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); 12 tcm.putObject(cache, key, list); // issue #578 and #116 13 } 14 return list; 15 } 16 } 17 return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); 18 }
11行與17行的區別在於,是否啟動二級緩存,如果啟動了,則將派發給BaseExecutor的查詢結果寫入暫存區(第12行,TransactionCacheManager),等事務提交在真正刷入二級緩存。下來我們重點來關注一下緩存的讀寫(第9行、第12行),這裏邊真正的執行對象是一系列Cache接口的實現,按職責有:線程安全、日誌記錄、過期清理、溢出淘汰、序列化、執行存儲等等環節。而二級緩存的設計精巧之處就在於此處,完美的按職責進行責任派發,完全解耦。
接下來我們來看下,默認情況下,緩存責任鏈的初始化過程:
1 public Cache useNewCache(Class<? extends Cache> typeClass, 2 Class<? extends Cache> evictionClass, 3 Long flushInterval, 4 Integer size, 5 boolean readWrite, 6 boolean blocking, 7 Properties props) { 8 Cache cache = new CacheBuilder(currentNamespace) 9 // 這裏設置默認的存儲為內存 10 .implementation(valueOrDefault(typeClass, PerpetualCache.class)) 11 // 這裏設置默認的溢出淘汰為LRU 12 .addDecorator(valueOrDefault(evictionClass, LruCache.class)) 13 .clearInterval(flushInterval) 14 .size(size) 15 .readWrite(readWrite) 16 .blocking(blocking) 17 .properties(props) 18 .build(); 19 configuration.addCache(cache); 20 currentCache = cache; 21 return cache; 22 }
然後是初始化過程:
1 public Cache build() { 2 setDefaultImplementations(); 3 Cache cache = newBaseCacheInstance(implementation, id); 4 setCacheProperties(cache); 5 // issue #352, do not apply decorators to custom caches 6 if (PerpetualCache.class.equals(cache.getClass())) { 7 for (Class<? extends Cache> decorator : decorators) { 8 cache = newCacheDecoratorInstance(decorator, cache); 9 setCacheProperties(cache); 10 } 11 cache = setStandardDecorators(cache); 12 } else if (!LoggingCache.class.isAssignableFrom(cache.getClass())) { 13 cache = new LoggingCache(cache); 14 } 15 return cache; 16 } 17 private Cache setStandardDecorators(Cache cache) { 18 try { 19 MetaObject metaCache = SystemMetaObject.forObject(cache); 20 if (size != null && metaCache.hasSetter("size")) { 21 metaCache.setValue("size", size); 22 } 23 if (clearInterval != null) { 24 cache = new ScheduledCache(cache); 25 ((ScheduledCache) cache).setClearInterval(clearInterval); 26 } 27 if (readWrite) { 28 cache = new SerializedCache(cache); 29 } 30 cache = new LoggingCache(cache); 31 cache = new SynchronizedCache(cache); 32 if (blocking) { 33 cache = new BlockingCache(cache); 34 } 35 return cache; 36 } catch (Exception e) { 37 throw new CacheException("Error building standard cache decorators. Cause: " + e, e); 38 } 39 }
這裏從第3、8、24、28、30、31、33行分別進行了責任裝飾初始化。這種依據職責分別拆分然後嵌套的解耦方式,其實是一種很成熟的企業級責任派發設計模式。而且形如第8行的循環裝飾嵌套,在很多開源框架中都能見到,比如Dubbo的AOP機制就是這樣初始化的。
下邊直接列一下Mybatis的二級緩存在設計上所覆蓋的功能,以及各功能責任鏈派發的結構圖:
從上邊的代碼可以看出,如果設置了blocking的話,那麼最外層將會包裹BlockingCache、下來是SynchronizedCache,這兩個均是進行線程安全,防止緩存穿透的處理。
1 public class BlockingCache implements Cache { 2 private final Cache delegate; 3 private final ConcurrentHashMap<Object, ReentrantLock> locks; 4 public BlockingCache(Cache delegate) { 5 this.delegate = delegate; 6 this.locks = new ConcurrentHashMap<Object, ReentrantLock>(); 7 } 8 @Override 9 public void putObject(Object key, Object value) { 10 try { 11 delegate.putObject(key, value); 12 } finally { 13 releaseLock(key); 14 } 15 } 16 @Override 17 public Object getObject(Object key) { 18 acquireLock(key); 19 Object value = delegate.getObject(key); 20 if (value != null) { 21 releaseLock(key); 22 } 23 return value; 24 } 25 }
1 public class SynchronizedCache implements Cache { 2 private Cache delegate; 3 @Override 4 public synchronized void putObject(Object key, Object object) { 5 delegate.putObject(key, object); 6 } 7 @Override 8 public synchronized Object getObject(Object key) { 9 return delegate.getObject(key); 10 } 11 }
再看一下負責溢出淘汰的LruCache:
1 public class LruCache implements Cache { 2 private final Cache delegate; 3 private Map<Object, Object> keyMap; 4 // 記錄當溢出時,需要淘汰的Key 5 private Object eldestKey; 6 public void setSize(final int size) { 7 // LinkedHashMap.accessOrder設置為true,即,每個被訪問的元素會一次放到隊列末尾。當溢出的時候就能從首部來移除了 8 keyMap = new LinkedHashMap<Object, Object>(size, .75F, true) { 9 @Override 10 protected boolean removeEldestEntry(Map.Entry<Object, Object> eldest) { 11 boolean tooBig = size() > size; 12 if (tooBig) { 13 eldestKey = eldest.getKey(); 14 } 15 return tooBig; 16 } 17 }; 18 } 19 @Override 20 public void putObject(Object key, Object value) { 21 delegate.putObject(key, value); 22 cycleKeyList(key); 23 } 24 private void cycleKeyList(Object key) { 25 keyMap.put(key, key); 26 if (eldestKey != null) { 27 delegate.removeObject(eldestKey); 28 eldestKey = null; 29 } 30 } 31 }
二級緩存就講到這裏,總結一下二級緩存件:
1、默認開啟,cachEnable開關。作用於提交后。
2、相同的StatementId。
3、相同的SQL、參數、行數。
4、跨Mapper調用。
雖然在目前各種分佈式應用的場景下,一級緩存和二級緩存都有很大概率的臟讀現象,而被禁止,但是Mybatis對這種局部場景的設計是及其精巧的。比如,解決對象循環嵌套查詢的場景設計,其實這種成熟的解決方案也被Spring(也存在對象循環注入的情景)所應用。以及責任裝飾的設計,Dubbo同樣在使用。其實我們能從得到很多啟發,比如,對於既定的業務場景,要加入現成安全的考量,那在不侵入業務代碼的前提下,我們是否也能增加一層責任裝飾,進行派發來完成呢?
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?
※網頁設計最專業,超強功能平台可客製化
※產品缺大量曝光嗎?你需要的是一流包裝設計!
如果你對性能測試感興趣,但是又不熟悉理論知識,可以看下面的系列文章
https://www.cnblogs.com/poloyy/category/1620792.html
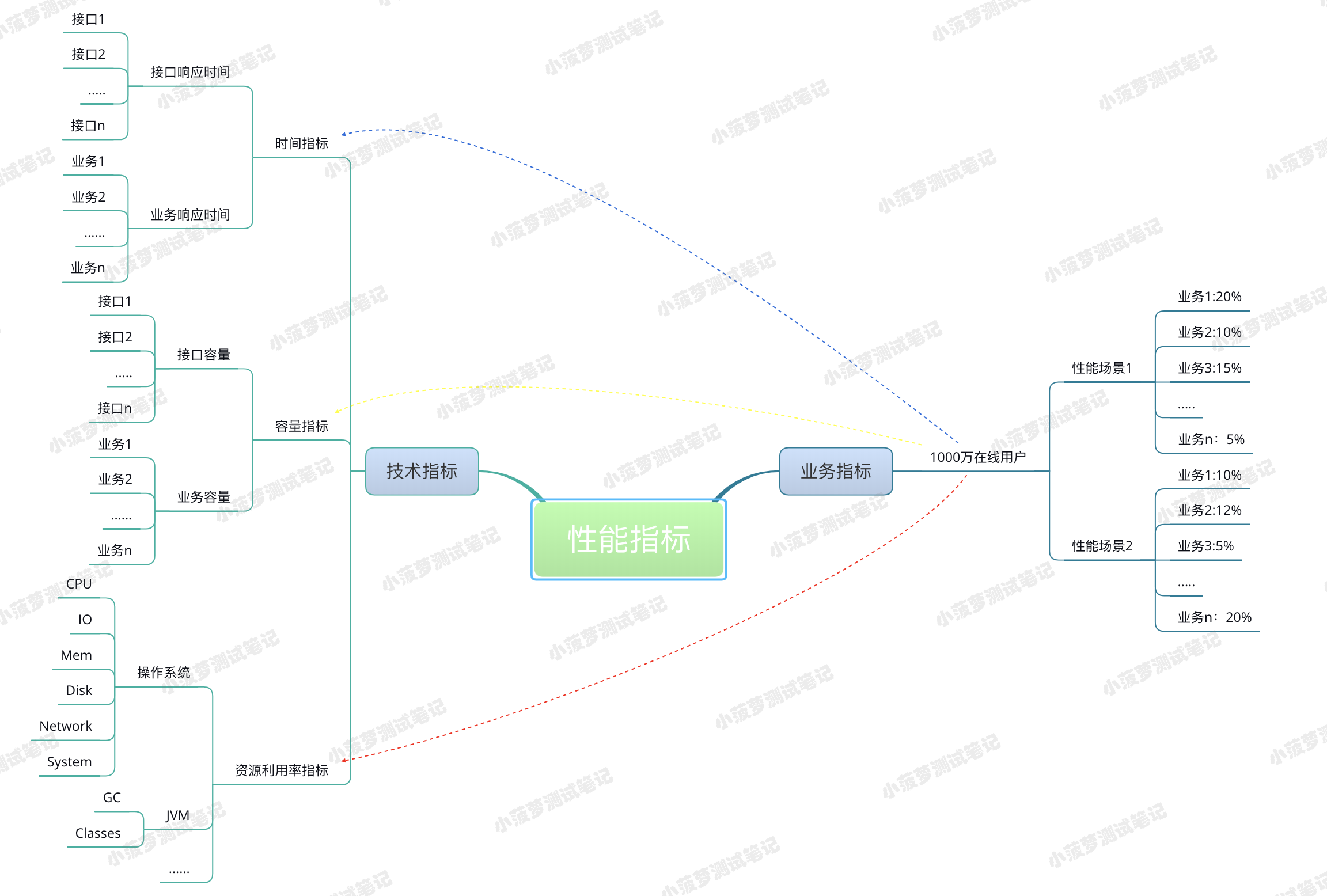
通常我們會從兩個層面定義性能場景的需求指標,它們有映射關係,技術指標不能脫離業務指標
指同一個時間點執行相同的操作(如:秒殺)
高速公路上,同時有多少輛車經過同一個關卡,但不一定是同一個牌子的汽車
同一時間點,發出請求的用戶數,一個用戶可以發出多個請求
假設有 10 個用戶數,每個用戶同一時間點內發起 2 個請求,那麼服務器收到的請求併發數就是 20
jmerter 中,默認一個接口請求,就是一個事務;但也支持多個接口整合成一個事務
若一個業務或事務有多個接口,那麼多個單接口的性能指標值相加 ≠ 業務或事務的性能指標值
概念:從發起請求到收到請求響應的時間
包含:Request Time 和 Response Time
等價:發起請求網絡傳輸時間 + 服務器處理時間 + 返迴響應網絡傳輸時間
在做性能測試時,要盡可能的降低網絡傳輸時間,這樣最終得出的 RT 會無限接近服務器處理時間,所以我們要把網絡環境搞好
完成單個事務所用的時間,可能包含了多個請求
服務器每秒處理事務數,衡量服務器處理能力的最主要指標
如果要單獨測試接口 1、2、3,那麼 T 就是接口級
如果從用戶角度下訂單,那 1、2、3 都在一個 T 中,就是業務級
結合實際業務設計,庫存服務一定是同步,而積分服務可以是異步,所以這個下單業務,可以只看作由 1、2 這兩個接口組成,但是 3 接口還是要監控分析的
所以,性能中 TPS 中 T 的定義取決於場景的目標和 T 的作用
——事務 start(接口 1)
接口 1 腳本
——事務 end(接口 1)
——事務 start(接口 2)
接口 2 腳本
——事務 end(接口 2)
——事務 start(接口 3)
接口 3 腳本
——事務 end(接口 3)
——事務 start(業務 A)
接口 1 腳本 – 接口 2(同步調用)
接口 1 腳本 – 接口 3(異步調用)
——事務 end(業務 A)
——事務 start(業務 A)
點擊 0 – 接口 1 腳本 – 接口 2(同步調用)
點擊 0 – 接口 1 腳本 – 接口 3(異步調用)
——事務 end(業務 A)
一般情況下,我們會按從上到下的順序一一來測試,這樣路徑清晰地執行,容易定位問題
每秒請求數,用戶從客戶端發起的請求數
對於請求數來說,也要看是哪個層面的請求,把上面的圖做一點點變化來描述請求數
如果一個用戶點擊了一次,發出來 3 個 HTTP Request,調用了 2 次訂單服務,調用了 2 次庫存服務,調用了 1 次積分服務
問:Request 數量如何計算
答:3+2+2+1 = 8?不, 應該是 3,因為發出了 3 個 Request,而調用服務會有單獨的描述,以便做性能統計
上圖的訂單服務、庫存服務、積分服務,各調用了2、2、1次,還是比較好理解的
有很多維度可以衡量一個系統的性能能力,但是如果把五個指標同時都拿來描述系統性能能力的話,未必太混亂了
單位時間內,網絡處理的請求數量(事務/s)
網絡沒有瓶頸時,吞吐量≈TPS
單位時間內,在網絡傳輸的數據量的平均速率(kB/s)
結尾
本篇博文,部分參考了高老師的《性能測試實戰30講》,因為指標那一塊講的特別好哦~
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!
一直以來對於.NETCore微服務相關的技術棧都處於一個淺嘗輒止的了解階段,在現實工作中也對於微服務也一直沒有使用的業務環境,所以一直也沒有整合過一個完整的基於.NETCore技術棧的微服務項目。正好由於最近剛好辭職,有了時間可以寫寫自己感興趣的東西,所以在此想把自己了解的微服務相關的概念和技術框架使用實現記錄在一個完整的工程中,由於本人技術有限,所以錯誤的地方希望大家指出。\
項目地址:https://github.com/yingpanwang/fordotnet/tree/dev
由於微服務把具體的業務分割成單獨的服務,所以如果直接將每個服務都與調用者直接,那麼維護起來將相當麻煩與頭疼,Api網關擔任的角色就是整合請求並按照路由規則轉發至服務的實例,並且由於所有所有請求都經過網關,那麼網關還可以承擔一系列宏觀的攔截功能,例如安全認證,日誌,熔斷
因為Api網關可以提供安全認證,日誌,熔斷相關的宏觀攔截的功能,也可以屏蔽多個下游服務的內部細節
Ocelot.json
{
"ReRoutes": [
// Auth
{
"UpstreamPathTemplate": "/auth/{action}", // 上游請求路徑模板
"UpstreamHttpMethod": [ "GET", "POST", "PUT", "DELETE" ], // 上游請求方法
"ServiceName": "Auth", // 服務名稱
"UseServiceDiscovery": true, // 是否使用服務發現
"DownstreamPathTemplate": "/connect/{action}", // 下游匹配路徑模板
"DownstreamScheme": "http", // 下游請求
"LoadBalancerOptions": { // 負載均衡配置
"Type": "RoundRobin"
}
//,
// 如果不採用服務發現需要指定下游host
//"DownstreamHostAndPorts": [
// {
// "Host": "10.0.1.10",
// "Port": 5000
// },
// {
// "Host": "10.0.1.11",
// "Port": 5000
// }
//]
}
],
"GlobalConfiguration": { // 全局配置信息
"BaseUrl": "http://localhost:5000", // 請求 baseurl
"ServiceDiscoveryProvider": { //服務發現提供者
"Host": "106.53.199.185",
"Port": 8500,
"Type": "Consul" // 使用Consul
}
}
}
將Config目錄下的ocelot.json添加到項目中
我這裏自己封裝了一個註冊服務的擴展(寫的比較隨意沒有在意細節)
appsettings.json 中添加註冊服務配置信息
"ServiceOptions": {
"ServiceIP": "localhost",
"ServiceName": "Auth",
"Port": 5800,
"HealthCheckUrl": "/api/health",
"ConsulOptions": {
"Scheme": "http",
"ConsulIP": "localhost",
"Port": 8500
}
}
擴展代碼 ConsulExtensions(注意:3.1中 IApplicationLifetime已廢棄 所以使用的是IHostApplicationLifetime 作為程序生命周期注入的方式)
using Consul;
using Microsoft.AspNetCore.Builder;
using Microsoft.Extensions.Configuration;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Hosting;
using System;
namespace ForDotNet.Common.Consul.Extensions
{
/// <summary>
/// 服務配置信息
/// </summary>
public class ServiceOptions
{
/// <summary>
/// 服務ip
/// </summary>
public string ServiceIP { get; set; }
/// <summary>
/// 服務名稱
/// </summary>
public string ServiceName { get; set; }
/// <summary>
/// 協議類型http or https
/// </summary>
public string Scheme { get; set; } = "http";
/// <summary>
/// 端口
/// </summary>
public int Port { get; set; }
/// <summary>
/// 健康檢查接口
/// </summary>
public string HealthCheckUrl { get; set; } = "/api/values";
/// <summary>
/// 健康檢查間隔時間
/// </summary>
public int HealthCheckIntervalSecond { get; set; } = 10;
/// <summary>
/// consul配置信息
/// </summary>
public ConsulOptions ConsulOptions { get; set; }
}
/// <summary>
/// consul配置信息
/// </summary>
public class ConsulOptions
{
/// <summary>
/// consul ip
/// </summary>
public string ConsulIP { get; set; }
/// <summary>
/// consul 端口
/// </summary>
public int Port { get; set; }
/// <summary>
/// 協議類型http or https
/// </summary>
public string Scheme { get; set; } = "http";
}
/// <summary>
/// consul註冊客戶端信息
/// </summary>
public class ConsulClientInfo
{
/// <summary>
/// 註冊信息
/// </summary>
public AgentServiceRegistration RegisterInfo { get; set; }
/// <summary>
/// consul客戶端
/// </summary>
public ConsulClient Client { get; set; }
}
/// <summary>
/// consul擴展(通過配置文件配置)
/// </summary>
public static class ConsulExtensions
{
private static readonly ServiceOptions serviceOptions = new ServiceOptions();
/// <summary>
/// 添加consul
/// </summary>
public static void AddConsulServiceDiscovery(this IServiceCollection services)
{
var config = services.BuildServiceProvider().GetService<IConfiguration>();
config.GetSection("ServiceOptions").Bind(serviceOptions);
//config.Bind(serviceOptions);
if (serviceOptions == null)
{
throw new Exception("獲取服務註冊信息失敗!請檢查配置信息是否正確!");
}
Register(services);
}
/// <summary>
/// 添加consul(通過配置opt對象配置)
/// </summary>
/// <param name="app"></param>
/// <param name="life">引用生命周期</param>
/// <param name="options">配置參數</param>
public static void AddConsulServiceDiscovery(this IServiceCollection services, Action<ServiceOptions> options)
{
options.Invoke(serviceOptions);
Register(services);
}
/// <summary>
/// 註冊consul服務發現
/// </summary>
/// <param name="app"></param>
/// <param name="life"></param>
public static void UseConsulServiceDiscovery(this IApplicationBuilder app, IHostApplicationLifetime life)
{
var consulClientInfo = app.ApplicationServices.GetRequiredService<ConsulClientInfo>();
if (consulClientInfo != null)
{
life.ApplicationStarted.Register( () =>
{
consulClientInfo.Client.Agent.ServiceRegister(consulClientInfo.RegisterInfo).Wait();
});
life.ApplicationStopping.Register( () =>
{
consulClientInfo.Client.Agent.ServiceDeregister(consulClientInfo.RegisterInfo.ID).Wait();
});
}
else
{
throw new NullReferenceException("未找到相關consul客戶端信息!");
}
}
private static void Register(this IServiceCollection services)
{
if (serviceOptions == null)
{
throw new Exception("獲取服務註冊信息失敗!請檢查配置信息是否正確!");
}
if (serviceOptions.ConsulOptions == null)
{
throw new ArgumentNullException("請檢查是否配置Consul信息!");
}
string consulAddress = $"{serviceOptions.ConsulOptions.Scheme}://{serviceOptions.ConsulOptions.ConsulIP}:{serviceOptions.ConsulOptions.Port}";
var consulClient = new ConsulClient(opt =>
{
opt.Address = new Uri(consulAddress);
});
var httpCheck = new AgentServiceCheck()
{
DeregisterCriticalServiceAfter = TimeSpan.FromSeconds(10), // 服務啟動多久后註冊
Interval = TimeSpan.FromSeconds(serviceOptions.HealthCheckIntervalSecond), // 間隔
HTTP = $"{serviceOptions.Scheme}://{serviceOptions.ServiceIP}:{serviceOptions.Port}{serviceOptions.HealthCheckUrl}",
Timeout = TimeSpan.FromSeconds(10)
};
var registration = new AgentServiceRegistration()
{
Checks = new[] { httpCheck },
ID = Guid.NewGuid().ToString(),
Name = serviceOptions.ServiceName,
Address = serviceOptions.ServiceIP,
Port = serviceOptions.Port,
};
services.AddSingleton(new ConsulClientInfo()
{
Client = consulClient,
RegisterInfo = registration
});
}
}
}
為了方便演示這裡是以開發者啟動的consul
在consul.exe的目錄下執行
consul agent -dev -ui // 開發者模式運行帶ui
啟動項目和可以發現我的們Auth服務已經註冊進來了
我們這裏訪問 http://localhost:5000/auth/token 獲取token
我們可以看到網關項目接收到了請求並在控制台中打印出以下信息
然後在Auth項目中的控制台中可以看到已經成功接收到了請求並響應
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
摘錄自2020年10月8日台灣醒報報導
根據衛報報導,聯合國有毒廢物問題特別報告員通卡克和其他9名聯合國高級官員聯名向巴布亞紐幾內亞、澳洲、中國、加拿大政府和中國國營開發商發函,表示對巴紐北部弗里達河開礦計畫的嚴重關切。
這項計畫如果獲得批准,將是巴紐史上最大的、也是世界上最大的礦場之一,佔地1萬6000公頃。該計畫將建在新幾內亞島北部的塞皮克河支流弗里達河上,預計每年開採的金、銀和銅礦價值可達15億美元,長達30年以上。PanAust持有這項專案8成的股份,是中國國企「廣東崛起」的一部分。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
※南投搬家公司費用,距離,噸數怎麼算?達人教你簡易估價知識!
※教你寫出一流的銷售文案?
※超省錢租車方案