1、Flume簡介
(1) Flume提供一個分佈式的,可靠的,對大數據量的日誌進行高效收集、聚集、移動的服務,Flume只能在Unix環境下運行。
(2) Flume基於流式架構,容錯性強,也很靈活簡單。
(3) Flume、Kafka用來實時進行數據收集,Spark、Flink用來實時處理數據,impala用來實時查詢。
2、Flume角色
2.1 Source
用於採集數據,Source是產生數據流的地方,同時Source會將產生的數據流傳輸到Channel,這個有點類似於Java IO部分的Channel。
2.2 Channel
用於橋接Sources和Sinks,類似於一個隊列。
2.3 Sink
從Channel收集數據,將數據寫到目標源(可以是下一個Source,也可以是HDFS或者HBase)。
2.4 Event
傳輸單元,Flume數據傳輸的基本單元,以事件的形式將數據從源頭送至目的地。
3、Flume傳輸過程
source監控某個文件或數據流,數據源產生新的數據,拿到該數據后,將數據封裝在一個Event中,並put到channel后commit提交,channel隊列先進先出,sink去channel隊列中拉取數據,然後寫入到HDFS或其他目標源中。
4、Flume安裝與部署
4.1 上傳包
將flume的gz包上傳到/opt/soft/目錄下;
[root@bigdata111 conf]# rz
若不支持rz命令,則用yum安裝lrzsz命令:
查詢含有rz的yum源,由結果可見,yum源中含有lrzsz.x86_64包;
[root@bigdata111 soft]# yum search rzsz
已加載插件:fastestmirror
Loading mirror speeds from cached hostfile
* base: mirrors.tuna.tsinghua.edu.cn
* extras: mirrors.aliyun.com
* updates: mirrors.aliyun.com
============================================================================================================================= N/S matched: rzsz ==============================================================================================================================
lrzsz.x86_64 : The lrz and lsz modem communications programs
名稱和簡介匹配 only,使用“search all”試試。
安裝rz命令
[root@bigdata111 soft]# yum -y install lrzsz
4.2 解壓包
將flume解壓到/opt/module/目錄下,並改短名字flume-1.8.0:
[root@bigdata111 soft]# tar -zvxf apache-flume-1.8.0-bin.tar.gz -C /opt/module
[root@bigdata111 module]# mv apache-flume-1.8.0-bin flume-1.8.0
4.3 配置參數
切換到/opt/module/flume-1.8.0/conf目錄,將flume-env.sh.template文件名改為:flume-env.sh
[root@bigdata111 module]# mv flume-env.sh.template flume-env.sh
查詢JAVA_HOME的值;
[root@bigdata111 conf]# echo $JAVA_HOME
/opt/module/jdk1.8.0_144
編輯flume-env.sh,將文件內容中的JAVA_HOME的值修改為上面查到的;
export JAVA_HOME=/opt/module/jdk1.8.0_144
4.4 配置環境變量
在/etc/profile末尾添加flume的家路徑
export FLUME_HOME=/opt/module/flume-1.8.0
export PATH=$PATH:$FLUME_HOME/bin
4.5 驗證flume成功與否
在xshell客戶端下,輸入flu,按tab鍵,看是否能夠自動補全:flume-ng
如果可以自動補全,則代表安裝flume成功,否則失敗。
[root@bigdata112 opt]# flume-ng
Error: Unknown or unspecified command ''
Usage: /opt/module/flume-1.8.0/bin/flume-ng <command> [options]...
commands:
help display this help text
agent run a Flume agent
avro-client run an avro Flume client
version show Flume version info
............
4.6 配置其他兩台機器
利用scp命令,配置其他兩台機器;
首先,將flume目錄分發到bigdata112,bigdata113
[root@bigdata111 ~]# scp -r /opt/module/flume-1.8.0/ root@bigdata112:/opt/module/
[root@bigdata111 ~]# scp -r /opt/module/flume-1.8.0/ root@bigdata113:/opt/module/
其次,將/etc/profile環境變量文件分發到bigdata112,bigdata113
[root@bigdata111 ~]# scp -r /etc/profile root@bigdata112:/etc/
[root@bigdata111 ~]# scp -r /etc/profile root@bigdata113:/etc/
最後,在bigdata112,bigdata113上分別刷新環境變量
[root@bigdata112 opt]# source /etc/profile
[root@bigdata113 opt]# source /etc/profile
5、Flume案例
5.1 監控端口數據
目標:Flume監控一端Console,另一端Console發送消息,使被監控端實時显示。
5.1.1 安裝telnet命令
[root@bigdata111 conf]# yum -y install telnet
5.1.2 創建Agent配置文件
在flume根目錄下,新建一個myconf目錄,用於存放自定義conf配置文件;
新建flume-telnet.conf文件,文件內容如下:
# 定義agent
# <自定義agent名>.sources=<自定義source名稱>
a1.sources = r1
# <自定義agent名>.sinks=<自定義sink名稱>
a1.sinks = k1
# <自定義agent名>.channels=<自定義channel名稱>
a1.channels = c1
# 定義source
# <agent名>.sources.<source名稱>.type = 源類型
a1.sources.r1.type = netcat
# <agent名>.sources.<source名稱>.bind = 數據來源服務器
a1.sources.r1.bind = bigdata111
# <agent名>.sources.<source名稱>.port = 自定義未被佔用的端口
a1.sources.r1.port = 44445
# 定義sink
# <agent名>.sinks.<sink名稱>.type = 下沉到目標源的類型
a1.sinks.k1.type = logger
# 定義channel
# <agent名>.channels.<channel名稱>.type = channel的類型
a1.channels.c1.type = memory
# <agent名>.channels.<channel名稱>.capacity = 最大容量
a1.channels.c1.capacity = 1000
# transactionCapacity<=capacity
a1.channels.c1.transactionCapacity = 1000
# 雙向鏈接
# <agent名>.sources.<source名稱>.channels = channel名稱
a1.sources.r1.channels = c1
# <agent名>.sinks.<sink名稱>.channel = channel名稱
a1.sinks.k1.channel = c1
5.1.3 啟動flume配置文件
[root@bigdata111 conf]# flume-ng agent --conf /opt/module/flume-1.8.0/conf/ --name a1 --conf-file /opt/module/flume-1.8.0/conf/flume-telnet.conf -Dflume.root.logger==INFO,console
可以簡寫為:
[root@bigdata111 conf]# flume-ng agent --c /opt/module/flume-1.8.0/conf/ --n a1 --f /opt/module/flume-1.8.0/conf/flume-telnet.conf -Dflume.root.logger==INFO,console
5.1.4 發送測試數據
通過其他機器向bigdata111的44445端口發送數據
[root@bigdata112 ~]# telnet bigdata111 44445
Trying 192.168.1.111...
Connected to bigdata111.
Escape character is '^]'.
echo aaaa
OK
echo aaaa
OK
echo bbbbbbbbb
OK
運行結果如圖:
5.2 實時讀取本地文件到HDFS
5.2.1 創建Agent配置文件
創建flume-hdfs配置文件
# 1 agent 若同時運行兩個agent,則agent名字需要改變,比如下面a2
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# 2 source
# 因監控linux本地文件,執行shell命令,所以type為exec;
a2.sources.r2.type = exec
# 監控的文件路徑
a2.sources.r2.command = tail -F /opt/test.log
a2.sources.r2.shell = /bin/bash -c
# 3 sink
# 數據下沉到目標源hdfs
a2.sinks.k2.type = hdfs
# 如果集群為HA模式,則路徑為active的namenode地址,普通分佈式集群,直接寫namenode所在地址即可。
a2.sinks.k2.hdfs.path = hdfs://bigdata111:9000/flume/%Y%m%d/%H
#上傳文件的前綴
a2.sinks.k2.hdfs.filePrefix = logs-
#是否按照時間滾動文件夾
a2.sinks.k2.hdfs.round = true
#多少時間單位創建一個新的文件夾
a2.sinks.k2.hdfs.roundValue = 1
#重新定義時間單位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地時間戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#積攢多少個Event才flush到HDFS一次
a2.sinks.k2.hdfs.batchSize = 1000
#設置文件類型,可支持壓縮
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一個新的文件
a2.sinks.k2.hdfs.rollInterval = 600
#設置每個文件的滾動大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滾動與Event數量無關
a2.sinks.k2.hdfs.rollCount = 0
#最小副本數
a2.sinks.k2.hdfs.minBlockReplicas = 1
# 定義channel
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 1000
# 雙向鏈接綁定
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
5.2.2 啟動flume配置文件
[root@bigdata111 flume-1.8.0]# flume-ng agent --conf /opt/module/flume-1.8.0/conf/ --name a2 --conf-file /opt/module/flume-1.8.0/myconf/flume-hdfs.conf
5.2.3 發送文件內容
[root@bigdata111 opt]# echo kjalksdjglkajsdg2333333333333333asdgasdgasdg >> test.log
[root@bigdata111 opt]# echo kjalksdjglkajsdg2333333333333333asdgasdgasdg >> test.log
[root@bigdata111 opt]# echo kjalksdjglkajsdg2333333333333333asdgasdgasdg >> test.log
[root@bigdata111 opt]# echo kjalksdjglkajsdg2333333333333333asdgasdgasdg >> test.log
運行結果:
5.3 實時讀取目錄文件到HDFS
目標:使用flume監聽整個目錄的文件
5.3.1 創建Agent配置文件
創建agent配置文件,命名為:flume-dir.conf,文件內容如下:
#1 Agent
a3.sources = r3
a3.sinks = k3
a3.channels = c3
#2 source
#監控目錄的類型
a3.sources.r3.type = spooldir
#監控目錄的路徑
a3.sources.r3.spoolDir = /opt/module/flume1.8.0/upload
#哪個文件上傳hdfs,然後給這個文件添加一個後綴
a3.sources.r3.fileSuffix = .COMPLETED
a3.sources.r3.fileHeader = true
#忽略所有以.tmp結尾的文件,不上傳(可選)
a3.sources.r3.ignorePattern = ([^ ]*\.tmp)
# 3 sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path = hdfs://bigdata111:9000/flume/%H
#上傳文件的前綴
a3.sinks.k3.hdfs.filePrefix = upload-
#是否按照時間滾動文件夾
a3.sinks.k3.hdfs.round = true
#多少時間單位創建一個新的文件夾
a3.sinks.k3.hdfs.roundValue = 1
#重新定義時間單位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地時間戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#積攢多少個Event才flush到HDFS一次
a3.sinks.k3.hdfs.batchSize = 100
#設置文件類型,可支持壓縮
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一個新的文件
a3.sinks.k3.hdfs.rollInterval = 600
#設置每個文件的滾動大小大概是128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滾動與Event數量無關
a3.sinks.k3.hdfs.rollCount = 0
#最小副本數
a3.sinks.k3.hdfs.minBlockReplicas = 1
# Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
溫馨提示:
1) 不要在監控目錄中創建並持續修改文件
2) 上傳完成的文件會以.COMPLETED結尾
3) 被監控文件夾每500毫秒掃描一次文件變動
5.3.2 啟動flume配置文件
[root@bigdata111 myconf]# flume-ng agent --conf /opt/module/flume-1.8.0/conf/ --name a3 --conf-file /opt/module/flume-1.8.0/myconf/flume-dir.conf
5.3.3 上傳文件到upload目錄
[root@bigdata111 opt]# mkdir upload
[root@bigdata111 opt]# ls
module soft test.log upload
[root@bigdata111 opt]# mv test.log upload/
[root@bigdata111 opt]# ls
module soft upload
[root@bigdata111 opt]# vi test1.log
[root@bigdata111 opt]# mv test1.log upload/
運行如圖:
5.4 扇出例子01
扇出:數據用於多個地方。(簡單理解:一個數據源對應多個channel,sink,並且輸出到多個目標源)
例子01示意圖:
目標:在flume1裏面接收數據,然後數據下沉到兩個不同目標源(控制台和HDFS)
5.4.1 創建Agent配置文件
在myconf目錄下,新建一個flume-fanout1.conf文件,內容配置如下:
# 定義agent
a1.sources=c1
a1.channels=k1 k2
a1.sinks=s1 s2
# 定義source
a1.sources.c1.type=exec
a1.sources.c1.command=tail -F /opt/test.log
a1.sources.c1.shell=/bin/bash -c
# 將數據流複製給多個channel
a1.sources.r1.selector.type=replicating
# 定義channel1
a1.channels.k1.type=memory
a1.channels.k1.capacity = 1000
a1.channels.k1.transactionCapacity=1000
# 定義channel2
a1.channels.k2.type=memory
a1.channels.k2.capacity = 1000
a1.channels.k2.transactionCapacity=1000
# 定義sink1
a1.sinks.s1.type=logger
# 定義sink2
a1.sinks.s2.type=hdfs
a1.sinks.s2.hdfs.path = hdfs://bigdata111:9000/flume/%Y%m%d/%H
# 上傳文件的前綴
a1.sinks.s2.hdfs.filePrefix = logs-
# 是否按照時間滾動文件夾
a1.sinks.s2.hdfs.round = true
# 多少時間單位創建一個新的文件夾
a1.sinks.s2.hdfs.roundValue = 1
# 重新定義時間單位
a1.sinks.s2.hdfs.roundUnit = hour
# 是否使用本地時間戳
a1.sinks.s2.hdfs.useLocalTimeStamp = true
# 積攢多少個Event才flush到HDFS一次
a1.sinks.s2.hdfs.batchSize = 1000
# 設置文件類型,可支持壓縮
a1.sinks.s2.hdfs.fileType = DataStream
# 多久生成一個新的文件
a1.sinks.s2.hdfs.rollInterval = 600
# 設置每個文件的滾動大小
a1.sinks.s2.hdfs.rollSize = 134217700
# 文件的滾動與Event數量無關
a1.sinks.s2.hdfs.rollCount = 0
# 最小副本數
a1.sinks.s2.hdfs.minBlockReplicas = 1
# 雙向鏈接
a1.sources.c1.channels = k1 k2
a1.sinks.s1.channel=k1
a1.sinks.s2.channel=k2
5.4.2 啟動flume配置文件
[root@bigdata111 myconf]# flume-ng agent --conf /opt/module/flume-1.8.0/conf/ --name a1 --conf-file /opt/module/flume-1.8.0/myconf/flume-fanout1.conf -Dflume.root.logger==INFO,console
5.4.3 向文件添加內容
切換到/opt/目錄下,新建test.log文件,然後動態添加內容,觀察控制台輸出以及web的hdfs文件
[root@bigdata111 opt]# touch test.log
[root@bigdata111 opt]# touch test.log
[root@bigdata111 opt]# echo 'china' >>test.log
[root@bigdata111 opt]# echo 'hello world' >>test.log
[root@bigdata111 opt]# echo 'nihao' >> test.log
控制台輸出如下:
web頁面結果:
5.5 扇出例子02
目標:flume1監控文件,然後將變動數據分別傳給flume2和flume3,flume2的數據下沉到HDFS;flume3的數據下沉到本地文件;
5.5.1 創建flume1配置文件
在bigdata111上的myconf目錄下,新建agent配置文件:flume-fanout1.conf;
flume1用於監控某文件的變動,同時產生兩個channel和兩個sink,分別輸送給flume2,flume3;
文件內容如下:
# 配置agent
a1.sources = c1
a1.channels = k1 k2
a1.sinks = s1 s2
# 定義source
a1.sources.c1.type=exec
a1.sources.c1.command=tail -F /opt/test.log
a1.sources.c1.shell=/bin/bash -c
# 將數據流複製給多個channel
a1.sources.c1.selector.type=replicating
# 定義channel1
a1.channels.k1.type=memory
a1.channels.k1.capacity = 1000
a1.channels.k1.transactionCapacity=1000
# 定義channel2
a1.channels.k2.type=memory
a1.channels.k2.capacity = 1000
a1.channels.k2.transactionCapacity=1000
# 定義sink1
a1.sinks.s1.type = avro
a1.sinks.s1.hostname = bigdata112
a1.sinks.s1.port = 4402
# 定義sink2
a1.sinks.s2.type = avro
a1.sinks.s2.hostname = bigdata113
a1.sinks.s2.port = 4402
# 雙向鏈接
a1.sources.c1.channels = k1 k2
a1.sinks.s1.channel=k1
a1.sinks.s2.channel=k2
5.5.2 創建flume2配置文件
在bigdata112的myconf目錄下,新建agent配置文件:flume-fanout2.conf
接收flume1的event數據,然後產生一個channel和一個sink,最後將數據下沉到hdfs
文件內容如下:
# 配置agent 不同agent之間,agent名不相同,但是source,channel,sink名可以相同
a2.sources = c2
a2.channels = k2
a2.sinks = s2
# 定義source
a2.sources.c2.type=avro
a2.sources.c2.bind = bigdata112
a2.sources.c2.port = 4402
# 定義channel
a2.channels.k2.type=memory
a2.channels.k2.capacity = 1000
a2.channels.k2.transactionCapacity=1000
# 定義sink
a2.sinks.s2.type = hdfs
a2.sinks.s2.hdfs.path=hdfs://bigdata111:9000/flume2/%H
#上傳文件的前綴
a2.sinks.s2.hdfs.filePrefix = flume2-
#是否按照時間滾動文件夾
a2.sinks.s2.hdfs.round = true
#多少時間單位創建一個新的文件夾
a2.sinks.s2.hdfs.roundValue = 1
#重新定義時間單位
a2.sinks.s2.hdfs.roundUnit = hour
#是否使用本地時間戳
a2.sinks.s2.hdfs.useLocalTimeStamp = true
#積攢多少個Event才flush到HDFS一次
a2.sinks.s2.hdfs.batchSize = 100
#設置文件類型,可支持壓縮
a2.sinks.s2.hdfs.fileType = DataStream
#多久生成一個新的文件
a2.sinks.s2.hdfs.rollInterval = 600
#設置每個文件的滾動大小大概是128M
a2.sinks.s2.hdfs.rollSize = 134217700
#文件的滾動與Event數量無關
a2.sinks.s2.hdfs.rollCount = 0
#最小副本數
a2.sinks.s2.hdfs.minBlockReplicas = 1
# 雙向鏈接
a2.sources.c2.channels = k2
a2.sinks.s2.channel=k2
5.5.3 創建flume3配置文件
在bigdata113的myconf目錄下,新建agent配置文件:flume-fanout3.conf
接收flume1的event數據,然後產生一個channel和一個sink,最後將數據下沉到本地/opt/flume3
文件內容如下:
# 配置agent
a3.sources = c3
a3.channels = k3
a3.sinks = s3
# 定義source
a3.sources.c3.type=avro
a3.sources.c3.bind = bigdata113
a3.sources.c3.port = 4402
# 定義channel
a3.channels.k3.type=memory
a3.channels.k3.capacity = 1000
a3.channels.k3.transactionCapacity=1000
# 定義sink
a3.sinks.s3.type = file_roll
# 提示:本地此目錄必須先建好,程序不會自動創建該目錄
a3.sinks.s3.sink.directory=/opt/flume3
# 雙向鏈接
a3.sources.c3.channels = k3
a3.sinks.s3.channel=k3
5.5.4 啟動三台機器配置文件
bigdata111:
[root@bigdata111 myconf]# flume-ng agent --conf /opt/module/flume-1.8.0/conf/ --name a1 --conf-file /opt/module/flume-1.8.0/myconf/flume-fanout1.conf -Dflume.root.logger==INFO,console
bigdata112:
[root@bigdata112 myconf]# flume-ng agent --conf /opt/module/flume-1.8.0/conf/ --name a2 --conf-file /opt/module/flume-1.8.0/myconf/flume-fanout2.conf
bigdata113:
[root@bigdata113 myconf]# flume-ng agent --conf /opt/module/flume-1.8.0/conf/ --name a3 --conf-file /opt/module/flume-1.8.0/myconf/flume-fanout3.conf
運行結果如圖:
bigdata112:
bigdata113:
5.6 扇入例子
5.6.1 創建flume1配置文件
flume1(agent1)監控端口數據變化,將數據sink到flume3(agent3);
在myconf目錄下新建agent文件:flume-fanin-1.conf
配置內容如下:
# 配置agent
a1.sources = c1
a1.channels = k1
a1.sinks = s1
# 配置source
a1.sources.c1.type = netcat
a1.sources.c1.bind = bigdata111
a1.sources.c1.port = 6666
# 配置sink
a1.sinks.s1.type=avro
a1.sinks.s1.hostname=bigdata113
a1.sinks.s1.port=5008
# 配置channel
a1.channels.k1.type=memory
a1.channels.k1.capacity=1000
a1.channels.k1.transactionCapacity=1000
# 雙向綁定
a1.sources.c1.channels = k1
a1.sinks.s1.channel = k1
5.6.2 創建flume2配置文件
flume2(agent2)監控本地文件變化,將數據sink到flume3(agent3);
在myconf目錄下新建agent文件:flume-fanin-2.conf
配置內容如下:
# 配置agent
a2.sources = c1
a2.channels = k1
a2.sinks = s1
# 配置source
a2.sources.c1.type = exec
a2.sources.c1.command = tail -F /opt/ceshi.log
a2.sources.c1.shell=/bin/bash -c
# 配置sink
a2.sinks.s1.type=avro
a2.sinks.s1.hostname=bigdata113
a2.sinks.s1.port=5008
# 配置channel
a2.channels.k1.type=memory
a2.channels.k1.capacity=1000
a2.channels.k1.transactionCapacity=1000
# 雙向綁定
a2.sources.c1.channels = k1
a2.sinks.s1.channel = k1
5.6.3 創建flume3配置文件
flume3(agent3)接收flume1和flume2的數據,將數據sink到HDFS ;
在myconf目錄下新建agent文件:flume-fanin-3.conf
配置內容如下:
# 配置agent
a3.sources = c1
a3.channels = k1
a3.sinks = s1
# 配置source
a3.sources.c1.type = avro
a3.sources.c1.bind = bigdata113
a3.sources.c1.port = 5008
# 配置sink
a3.sinks.s1.type=hdfs
a3.sinks.s1.hdfs.path=hdfs://bigdata111:9000/flume3/%H
# 上傳文件的前綴
a3.sinks.s1.hdfs.filePrefix = flume3-
# 是否按照時間滾動文件夾
a3.sinks.s1.hdfs.round = true
# 多少時間單位創建一個新的文件夾
a3.sinks.s1.hdfs.roundValue = 1
# 重新定義時間單位
a3.sinks.s1.hdfs.roundUnit = hour
# 是否使用本地時間戳
a3.sinks.s1.hdfs.useLocalTimeStamp = true
# 積攢多少個Event才flush到HDFS一次
a3.sinks.s1.hdfs.batchSize = 1000
# 設置文件類型,可支持壓縮
a3.sinks.s1.hdfs.fileType = DataStream
# 多久生成一個新的文件
a3.sinks.s1.hdfs.rollInterval = 600
# 設置每個文件的滾動大小大概是128M
a3.sinks.s1.hdfs.rollSize = 134217700
# 文件的滾動與Event數量無關
a3.sinks.s1.hdfs.rollCount = 0
# 最小冗餘數
a3.sinks.s1.hdfs.minBlockReplicas = 1
# 配置channel
a3.channels.k1.type=memory
a3.channels.k1.capacity=1000
a3.channels.k1.transactionCapacity=1000
# 雙向綁定
a3.sources.c1.channels = k1
a3.sinks.s1.channel = k1
5.6.4 啟動三個flume配置文件
flume1:
[root@bigdata111 myconf]# flume-ng agent -c ../conf/ -n a1 -f flume-fanout1.conf -Dflume.root.logger==INFO,console
flume2:
[root@bigdata112 myconf]# flume-ng agent -c ../conf/ -n a2 -f flume-fanout2.conf
flume3:
[root@bigdata113 myconf]# flume-ng agent -c ../conf/ -n a3 -f flume-fanout3.conf
5.6.5 操作端口與文件
新開xshell選項卡,鏈接bigdata111服務器,然後執行telnet命令:
[root@bigdata111 ~]# telnet bigdata111 6666
Trying 192.168.1.111...
Connected to bigdata111.
Escape character is '^]'.
english
OK
chinese
OK
hello
OK
.net
OK
php
OK
java
OK
新開xshell選項卡,鏈接bigdata112服務器,然後向/opt/ceshi.log添加新內容:
[root@bigdata112 ~]# cd /opt/
[root@bigdata112 opt]# ls
ceshi.log ha module soft zookeeper.out
[root@bigdata112 opt]# cat ceshi.log
start-log-in
end-log
[root@bigdata112 opt]# echo `date` >> ceshi.log
[root@bigdata112 opt]# echo "end-log" >> ceshi.log
[root@bigdata112 opt]# cat ceshi.log
start-log-in
end-log
2019年 09月 07日 星期六 23:36:03 CST
end-log
5.6.6 显示運行結果
web頁面結果:
hdfs的文件內容:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選

 據悉,此次頒發的100個計程車牌照將用於e6純電動車。宏達同新加坡計程車私人有限公司將負責這100台e6計程車的日常運營和管理,首批車輛預計在今年9月上路運營,100台計程車計畫于明年一季度前全部投入服務。屆時,比亞迪將與其新加坡合作夥伴對這支e6車隊進行即時資料採集、分析和處理,聯合研發自動駕駛電動汽車技術和智慧交通管理系統,以支援新加坡政府打造智慧交通。 目前,比亞迪在新加坡的車型由最初的e6逐步擴展到電動巴士、叉車和電動商用車等多種車型,並與GrabCar等交通出行領軍企業展開合作。今年5月30日,比亞迪還攜手SMART集團在新加坡開啟了全球首家純電動車體驗中心,並簽署在新加坡聯合推廣1,000輛e6的合作諒解備忘錄。 文章來源:環球網
據悉,此次頒發的100個計程車牌照將用於e6純電動車。宏達同新加坡計程車私人有限公司將負責這100台e6計程車的日常運營和管理,首批車輛預計在今年9月上路運營,100台計程車計畫于明年一季度前全部投入服務。屆時,比亞迪將與其新加坡合作夥伴對這支e6車隊進行即時資料採集、分析和處理,聯合研發自動駕駛電動汽車技術和智慧交通管理系統,以支援新加坡政府打造智慧交通。 目前,比亞迪在新加坡的車型由最初的e6逐步擴展到電動巴士、叉車和電動商用車等多種車型,並與GrabCar等交通出行領軍企業展開合作。今年5月30日,比亞迪還攜手SMART集團在新加坡開啟了全球首家純電動車體驗中心,並簽署在新加坡聯合推廣1,000輛e6的合作諒解備忘錄。 文章來源:環球網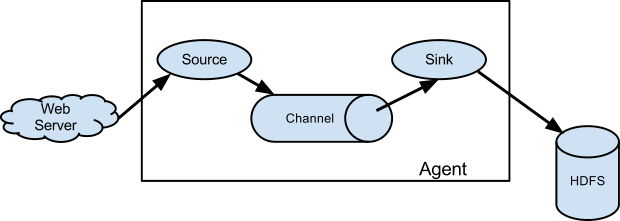

 雙方聯合發表的聲明稱,根據協定,國營的泰國國家石油公司將負責建造由20個充電站組成的網狀系統,汽車製造商承諾研發電動車輛,並提升電車在泰國市場上的知名度和可信度。據悉,這六家企業分別是寶馬集團、賓士汽車、三菱汽車、日產汽車、保時捷汽車和沃爾沃集團在泰國的分部。 據悉,泰國國家石油公司自2012年起開始研發電動車輛技術,目前已經運行4個電動車輛充電站。到目前為止,影響電動車輛生產和銷售的一大因素是充電站數量的不足。為刺激這一產業的發展,泰國政府已向製造電動車輛部件的生產商發放稅收鼓勵,包括發動機和電池生產商。 文章來源:環球網
雙方聯合發表的聲明稱,根據協定,國營的泰國國家石油公司將負責建造由20個充電站組成的網狀系統,汽車製造商承諾研發電動車輛,並提升電車在泰國市場上的知名度和可信度。據悉,這六家企業分別是寶馬集團、賓士汽車、三菱汽車、日產汽車、保時捷汽車和沃爾沃集團在泰國的分部。 據悉,泰國國家石油公司自2012年起開始研發電動車輛技術,目前已經運行4個電動車輛充電站。到目前為止,影響電動車輛生產和銷售的一大因素是充電站數量的不足。為刺激這一產業的發展,泰國政府已向製造電動車輛部件的生產商發放稅收鼓勵,包括發動機和電池生產商。 文章來源:環球網
 作為低碳化、資訊化和智慧化的最佳平臺,新能源汽車正成為新一輪科技革命的重要載體。2016年1—6月,全中國新能源汽車累計產銷量均超過17萬輛,較2015年同期大幅提高。然而,在新能源汽車示範推廣應用過程中,暴露出充電基礎設施建設不足、車輛安全隱患增加等問題。 陰和俊介紹,從2015年下半年起,科技部聯合財政部、工信部等組織實施「十三五」國家重點研發計畫新能源汽車試點專項,從基礎科學問題、共性核心關鍵、動力系統技術、集成開發與示範四個層次,重點對動力電池與電池的管理系統、電機驅動與電力電池總成、電動汽車智能化、燃料電池動力系統、插電增程式混合動力系統、純電動系統六個方向進行研發部署,以完善中國新能源汽車研發體系。 文章來源:科技日報
作為低碳化、資訊化和智慧化的最佳平臺,新能源汽車正成為新一輪科技革命的重要載體。2016年1—6月,全中國新能源汽車累計產銷量均超過17萬輛,較2015年同期大幅提高。然而,在新能源汽車示範推廣應用過程中,暴露出充電基礎設施建設不足、車輛安全隱患增加等問題。 陰和俊介紹,從2015年下半年起,科技部聯合財政部、工信部等組織實施「十三五」國家重點研發計畫新能源汽車試點專項,從基礎科學問題、共性核心關鍵、動力系統技術、集成開發與示範四個層次,重點對動力電池與電池的管理系統、電機驅動與電力電池總成、電動汽車智能化、燃料電池動力系統、插電增程式混合動力系統、純電動系統六個方向進行研發部署,以完善中國新能源汽車研發體系。 文章來源:科技日報
 電源電路拓撲為反激式。配備有反激式轉換器控制IC、電壓檢測IC、功率MOSFET、絕緣變壓器及輸入輸出電容器等。絕緣耐壓為1800VAC。備有輸出電壓不同的4款產品,分別是輸出電壓為+3.3V的“MYISA3R308PSPQ”、輸出電壓為+5.0V的“MYISA005R6PSPQ”、輸出電壓為+12V的“MYISA012R3PSPQ”以及輸出電壓為+15V的“MYISA015R2PSPQ”。 最大輸出電流方面,+3.3V產品為0.8A,+5.0V產品為0.6A,+12V產品為0.25A,+15V產品為0.2A。輸出電壓的誤差為±5%。開關頻率為300kHz。轉換效率方面,+3.3V產品為70%,其他三款產品為74%。工作溫度範圍在-40~+105℃。樣品價格為1000日元。 文章來源:日經技術線上mp
電源電路拓撲為反激式。配備有反激式轉換器控制IC、電壓檢測IC、功率MOSFET、絕緣變壓器及輸入輸出電容器等。絕緣耐壓為1800VAC。備有輸出電壓不同的4款產品,分別是輸出電壓為+3.3V的“MYISA3R308PSPQ”、輸出電壓為+5.0V的“MYISA005R6PSPQ”、輸出電壓為+12V的“MYISA012R3PSPQ”以及輸出電壓為+15V的“MYISA015R2PSPQ”。 最大輸出電流方面,+3.3V產品為0.8A,+5.0V產品為0.6A,+12V產品為0.25A,+15V產品為0.2A。輸出電壓的誤差為±5%。開關頻率為300kHz。轉換效率方面,+3.3V產品為70%,其他三款產品為74%。工作溫度範圍在-40~+105℃。樣品價格為1000日元。 文章來源:日經技術線上mp