※評比南投搬家公司費用收費行情懶人包大公開
搬家價格與搬家費用透明合理,不亂收費。本公司提供下列三種搬家計費方案,由資深專業組長到府估價,替客戶量身規劃選擇最經濟節省的計費方式
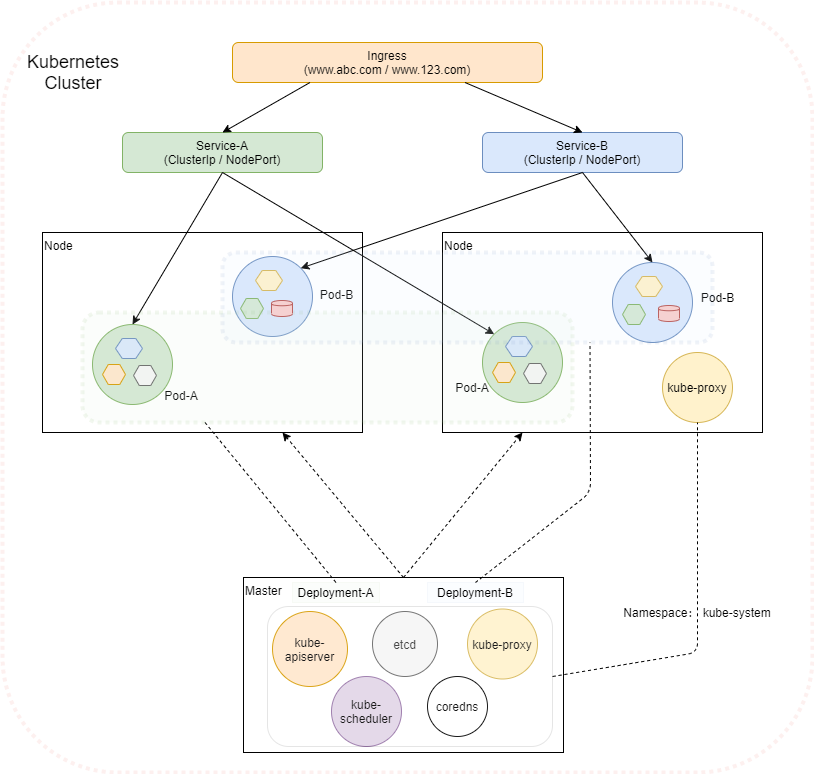
一、Overview
Angular 入坑記錄的筆記第六篇,介紹 Angular 路由模塊中關於路由守衛的相關知識點,了解常用到的路由守衛接口,知道如何通過實現路由守衛接口來實現特定的功能需求,以及實現對於特性模塊的惰性加載
對應官方文檔地址:
- 路由與導航
配套代碼地址:angular-practice/src/router-combat
二、Contents
- Angular 從入坑到棄坑 – Angular 使用入門
- Angular 從入坑到挖坑 – 組件食用指南
- Angular 從入坑到挖坑 – 表單控件概覽
- Angular 從入坑到挖坑 – HTTP 請求概覽
- Angular 從入坑到挖坑 – Router 路由使用入門指北
- Angular 從入坑到挖坑 – 路由守衛連連看
三、Knowledge Graph
四、Step by Step
4.1、基礎準備
重複上一篇筆記的內容,搭建一個包含路由配置的 Angualr 項目
新建四個組件,分別對應於三個實際使用到的頁面與一個設置為通配路由的 404 頁面
-- 危機中心頁面
ng g component crisis-list
-- 英雄中心頁面
ng g component hero-list
-- 英雄相親頁面
ng g component hero-detail
-- 404 頁面
ng g component page-not-found
在 app-routing.module.ts 文件中完成對於項目路由的定義,這裏包含了對於路由的重定向、通配路由,以及通過動態路由進行參數傳遞的使用
import { NgModule } from '@angular/core';
import { Routes, RouterModule } from '@angular/router';
// 引入組件
import { CrisisListComponent } from './crisis-list/crisis-list.component';
import { HeroListComponent } from './hero-list/hero-list.component';
import { HeroDetailComponent } from './hero-detail/hero-detail.component';
import { PageNotFoundComponent } from './page-not-found/page-not-found.component';
const routes: Routes = [
{
path: 'crisis-center',
component: CrisisListComponent,
},
{
path: 'heroes',
component: HeroListComponent,
},
{
path: 'hero/:id',
component: HeroDetailComponent,
},
{
path: '',
redirectTo: '/heroes',
pathMatch: 'full',
},
{
path: '**',
component: PageNotFoundComponent,
}
];
@NgModule({
imports: [RouterModule.forRoot(routes)],
exports: [RouterModule],
})
export class AppRoutingModule { }
之後,在根組件中,添加 router-outlet 標籤用來聲明路由在頁面上渲染的出口
<h1>Angular Router</h1>
<nav>
<a routerLink="/crisis-center" routerLinkActive="active">Crisis Center</a>
<a routerLink="/heroes" routerLinkActive="active">Heroes</a>
</nav>
<router-outlet></router-outlet>
4.2、路由守衛
在 Angular 中,路由守衛主要可以解決以下的問題
- 對於用戶訪問頁面的權限校驗(是否已經登錄?已經登錄的角色是否有權限進入?)
- 在跳轉到組件前獲取某些必須的數據
- 離開頁面時,提示用戶是否保存未提交的修改
Angular 路由模塊提供了如下的幾個接口用來幫助我們解決上面的問題
- CanActivate:用來處理系統跳轉到到某個路由地址的操作(判斷是否可以進行訪問)
- CanActivateChild:功能同 CanActivate,只不過針對的是子路由
- CanDeactivate:用來處理從當前路由離開的情況(判斷是否存在未提交的信息)
- CanLoad:是否允許通過延遲加載的方式加載某個模塊
在添加了路由守衛之後,通過路由守衛返回的值,從而達到我們控制路由的目的
- true:導航將會繼續
- false:導航將會中斷,用戶停留在當前的頁面或者是跳轉到指定的頁面
- UrlTree:取消當前的導航,並導航到路由守衛返回的這個 UrlTree 上(一個新的路由信息)
4.2.1、CanActivate:認證授權
在實現路由守衛之前,可以通過 Angular CLI 來生成路由守衛的接口實現類,通過命令行,在 app/auth 路徑下生成一個授權守衛類,CLI 會提示我們選擇繼承的路由守衛接口,這裏選擇 CanActivate 即可
ng g guard auth/auth
在 AuthGuard 這個路由守衛類中,我們模擬了是否允許訪問一個路由地址的認證授權。首先判斷是否已經登錄,如果登錄后再判斷當前登錄人是否具有當前路由地址的訪問權限
import { Injectable } from '@angular/core';
import { CanActivate, ActivatedRouteSnapshot, RouterStateSnapshot, UrlTree, Router } from '@angular/router';
import { Observable } from 'rxjs';
@Injectable({
providedIn: 'root'
})
export class AuthGuard implements CanActivate {
/**
* ctor
* @param router 路由
*/
constructor(private router: Router) { }
canActivate(
next: ActivatedRouteSnapshot,
state: RouterStateSnapshot): Observable<boolean | UrlTree> | Promise<boolean | UrlTree> | boolean | UrlTree {
// 判斷是否有 token 信息
let token = localStorage.getItem('auth-token') || '';
if (token === '') {
this.router.navigate(['/login']);
return false;
}
// 判斷是否可以訪問當前連接
let url: string = state.url;
if (token === 'admin' && url === '/crisis-center') {
return true;
}
this.router.navigate(['/login']);
return false;
}
}
之後我們就可以在 app-routing.module.ts 文件中引入 AuthGuard 類,針對需要保護的路由進行路由守衛的配置
import { NgModule } from '@angular/core';
import { Routes, RouterModule } from '@angular/router';
// 引入組件
import { CrisisListComponent } from './crisis-list/crisis-list.component';
// 引入路由守衛
import { AuthGuard } from './auth/auth.guard';
const routes: Routes = [
{
path: 'crisis-center',
component: CrisisListComponent,
canActivate: [AuthGuard], // 添加針對當前路由的 canActivate 路由守衛
}
];
@NgModule({
imports: [RouterModule.forRoot(routes)],
exports: [RouterModule],
})
export class AppRoutingModule { }
4.2.2、CanActivateChild:針對子路由的認證授權
與繼承 CanActivate 接口進行路由守衛的方式相似,針對子路由的認證授權可以通過繼承 CanActivateChild 接口來實現,因為授權的邏輯很相似,這裏通過多重繼承的方式,擴展 AuthGuard 的功能,從而達到同時針對路由和子路由的路由守衛
改造下原先 canActivate 方法的實現,將認證邏輯修改為用戶的 token 信息中包含 admin 即可訪問 crisis-center 頁面,在針對子路由進行認證授權的 canActivateChild 方法中,通過判斷 token 信息是否為 admin-master 模擬完成對於子路由的訪問認證
import { Injectable } from '@angular/core';
import { CanActivate, ActivatedRouteSnapshot, RouterStateSnapshot, UrlTree, Router, CanActivateChild } from '@angular/router';
import { Observable } from 'rxjs';
@Injectable({
providedIn: 'root'
})
export class AuthGuard implements CanActivate, CanActivateChild {
/**
* ctor
* @param router 路由
*/
constructor(private router: Router) { }
canActivate(
next: ActivatedRouteSnapshot,
state: RouterStateSnapshot): Observable<boolean | UrlTree> | Promise<boolean | UrlTree> | boolean | UrlTree {
// 判斷是否有 token 信息
let token = localStorage.getItem('auth-token') || '';
if (token === '') {
this.router.navigate(['/login']);
return false;
}
// 判斷是否可以訪問當前連接
let url: string = state.url;
if (token.indexOf('admin') !== -1 && url.indexOf('/crisis-center') !== -1) {
return true;
}
this.router.navigate(['/login']);
return false;
}
canActivateChild(
childRoute: ActivatedRouteSnapshot,
state: RouterStateSnapshot): boolean | UrlTree | Observable<boolean | UrlTree> | Promise<boolean | UrlTree> {
let token = localStorage.getItem('auth-token') || '';
if (token === '') {
this.router.navigate(['/login']);
return false;
}
return token === 'admin-master';
}
}
通過 Angular CLI 新增一個 crisis-detail 組件,作為 crisis-list 的子組件
ng g component crisis-detail
接下來在 crisis-list 中添加 router-outlet 標籤,用來定義子路由的渲染出口
<h2>危機中心</h2>
<ul class="crises">
<li *ngFor="let crisis of crisisList">
<a [routerLink]="[crisis.id]">
<span class="badge">{{ crisis.id }}</span>{{ crisis.name }}
</a>
</li>
</ul>
<!-- 定義子路由的渲染出口 -->
<router-outlet></router-outlet>
在針對子路由的認證授權配置時,我們可以選擇針對每個子路由添加 canActivateChild 屬性,也可以定義一個空地址的子路由,將所有歸屬於 crisis-list 的子路由作為這個空路由的子路由,通過針對這個空路徑添加 canActivateChild 屬性,從而實現將守護規則應用到所有的子路由上
※回頭車貨運收費標準
宇安交通關係企業,自成立迄今,即秉持著「以誠待人」、「以實處事」的企業信念
這裏其實相當於將原先兩級的路由模式(父:crisis-list,子:crisis-detail)改成了三級(父:crisis-list,子:’ ‘(空路徑),孫:crisis-detail)
import { NgModule } from '@angular/core';
import { Routes, RouterModule } from '@angular/router';
// 引入組件
import { CrisisListComponent } from './crisis-list/crisis-list.component';
import { CrisisDetailComponent } from './crisis-detail/crisis-detail.component';
// 引入路由守衛
import { AuthGuard } from './auth/auth.guard';
const routes: Routes = [
{
path: 'crisis-center',
component: CrisisListComponent,
canActivate: [AuthGuard], // 添加針對當前路由的 canActivate 路由守衛
children: [{
path: '',
canActivateChild: [AuthGuard], // 添加針對子路由的 canActivate 路由守衛
children: [{
path: 'detail',
component: CrisisDetailComponent
}]
}]
}
];
@NgModule({
imports: [RouterModule.forRoot(routes)],
exports: [RouterModule],
})
export class AppRoutingModule { }
4.2.3、CanDeactivate:處理用戶未提交的修改
當進行表單填報之類的操作時,因為會涉及到一個提交的動作,當用戶沒有點擊保存按鈕就離開時,最好能暫停,對用戶進行一個友好性的提示,由用戶選擇後續的操作
創建一個路由守衛,繼承於 CanDeactivate 接口
ng g guard hero-list/guards/hero-can-deactivate
與上面的 CanActivate、CanActivateChild 路由守衛的使用方式不同,對於 CanDeactivate 守衛來說,我們需要將參數中的 unknown 替換成我們實際需要進行路由守衛的組件
import { Injectable } from '@angular/core';
import { CanDeactivate, ActivatedRouteSnapshot, RouterStateSnapshot, UrlTree } from '@angular/router';
import { Observable } from 'rxjs';
@Injectable({
providedIn: 'root'
})
export class HeroCanDeactivateGuard implements CanDeactivate<unknown> {
canDeactivate(
component: unknown,
currentRoute: ActivatedRouteSnapshot,
currentState: RouterStateSnapshot,
nextState?: RouterStateSnapshot): Observable<boolean | UrlTree> | Promise<boolean | UrlTree> | boolean | UrlTree {
return true;
}
}
例如,這裏針對的是 HeroListComponent 這個組件,因此我們需要將泛型的參數 unknown 改為 HeroListComponent,通過 component 參數,就可以獲得需要進行路由守衛的組件的相關信息
import { Injectable } from '@angular/core';
import {
CanDeactivate,
ActivatedRouteSnapshot,
RouterStateSnapshot,
UrlTree,
} from '@angular/router';
import { Observable } from 'rxjs';
// 引入需要進行路由守衛的組件
import { HeroListComponent } from '../hero-list.component';
@Injectable({
providedIn: 'root',
})
export class HeroCanDeactivateGuard
implements CanDeactivate<HeroListComponent> {
canDeactivate(
component: HeroListComponent,
currentRoute: ActivatedRouteSnapshot,
currentState: RouterStateSnapshot,
nextState?: RouterStateSnapshot
):
| Observable<boolean | UrlTree>
| Promise<boolean | UrlTree>
| boolean
| UrlTree {
// 判斷是否修改了原始數據
//
const data = component.hero;
if (data === undefined) {
return true;
}
const origin = component.heroList.find(hero => hero.id === data.id);
if (data.name === origin.name) {
return true;
}
return window.confirm('內容未提交,確認離開?');
}
}
這裏模擬判斷用戶有沒有修改原始的數據,當用戶修改了數據並移動到別的頁面時,觸發路由守衛,提示用戶是否保存后再離開當前頁面
4.3、異步路由
4.3.1、惰性加載
當應用逐漸擴大,使用現有的加載方式會造成應用在第一次訪問時就加載了全部的組件,從而導致系統首次渲染過慢。因此這裏可以使用惰性加載的方式在請求具體的模塊時才加載對應的組件
惰性加載只針對於特性模塊(NgModule),因此為了使用惰性加載這個功能點,我們需要將系統按照功能劃分,拆分出一個個獨立的模塊
首先通過 Angular CLI 創建一個危機中心模塊(crisis 模塊)
-- 查看創建模塊的相關參數
ng g module --help
-- 創建危機中心模塊(自動在 app.moudule.ts 中引入新創建的 CrisisModule、添加當前模塊的路由配置)
ng g module crisis --module app --routing
將 crisis-list、crisis-detail 組件全部移動到 crisis 模塊下面,並在 CrisisModule 中添加對於 crisis-list、crisis-detail 組件的聲明,同時將原來在 app.module.ts 中聲明的組件代碼移除
import { NgModule } from '@angular/core';
import { CommonModule } from '@angular/common';
import { CrisisRoutingModule } from './crisis-routing.module';
import { FormsModule } from '@angular/forms';
// 引入模塊中使用到的組件
import { CrisisListComponent } from './crisis-list/crisis-list.component';
import { CrisisDetailComponent } from './crisis-detail/crisis-detail.component';
@NgModule({
declarations: [
CrisisListComponent,
CrisisDetailComponent
],
imports: [
CommonModule,
FormsModule,
CrisisRoutingModule
]
})
export class CrisisModule { }
同樣的,將當前模塊的路由配置移動到專門的路由配置文件 crisis-routing.module.ts 中,並將 app-routing.module.ts 中相關的路由配置刪除
import { NgModule } from '@angular/core';
import { Routes, RouterModule } from '@angular/router';
// 引入組件
import { CrisisListComponent } from './crisis-list/crisis-list.component';
import { CrisisDetailComponent } from './crisis-detail/crisis-detail.component';
// 引入路由守衛
import { AuthGuard } from '../auth/auth.guard';
const routes: Routes = [{
path: '',
component: CrisisListComponent,
canActivate: [AuthGuard], // 添加針對當前路由的 canActivate 路由守衛
children: [{
path: '',
canActivateChild: [AuthGuard], // 添加針對子路由的 canActivate 路由守衛
children: [{
path: 'detail',
component: CrisisDetailComponent
}]
}]
}];
@NgModule({
imports: [RouterModule.forChild(routes)],
exports: [RouterModule]
})
export class CrisisRoutingModule { }
重新運行項目,如果你在創建模塊的命令中設置了自動引入當前模塊到 app.module.ts 文件中,大概率會遇到下面的問題
這裏的問題與配置通配路由需要放到最後的原因相似,因為腳手架在幫我們將創建的模塊導入到 app.module.ts 中時,是添加到整個數組的最後,同時因為我們已經將 crisis 模塊的路由配置移動到專門的 crisis-routing.module.ts 中了,框架在進行路由匹配時會預先匹配上 app-routing.module.ts 中設置的通配路由,從而導致無法找到實際應該對應的組件,因此這裏我們需要將 AppRoutingModule 放到聲明的最後
當問題解決后,就可以針對 crisis 模塊設置惰性加載
在配置惰性路由時,我們需要以一種類似於子路由的方式進行配置,通過路由的 loadChildren 屬性來加載對應的模塊,而不是具體的組件,修改后的 AppRoutingModule 代碼如下
import { HeroCanDeactivateGuard } from './hero-list/guards/hero-can-deactivate.guard';
import { NgModule } from '@angular/core';
import { Routes, RouterModule } from '@angular/router';
const routes: Routes = [
{
path: 'crisis-center',
loadChildren: () => import('./crisis/crisis.module').then(m => m.CrisisModule)
}
];
@NgModule({
imports: [RouterModule.forRoot(routes, { enableTracing: true })],
exports: [RouterModule],
})
export class AppRoutingModule { }
當導航到這個 /crisis-center 路由時,框架會通過 loadChildren 字符串來動態加載 CrisisModule,然後把 CrisisModule 添加到當前的路由配置中,而惰性加載和重新配置工作只會發生一次,也就是在該路由首次被請求時執行,在後續請求時,該模塊和路由都是立即可用的
4.3.2、CanLoad:杜絕未通過認證授權的組件加載
在上面的代碼中,對於 CrisisModule 模塊我們已經使用 CanActivate、CanActivateChild 路由守衛來進行路由的認證授權,但是當我們並沒有權限訪問該路由的權限,卻依然點擊了鏈接時,此時框架路由仍會加載該模塊。為了杜絕這種授權未通過仍加載模塊的問題發生,這裏需要使用到 CanLoad 守衛
因為這裏的判斷邏輯與認證授權的邏輯相同,因此在 AuthGuard 中,繼承 CanLoad 接口即可,修改后的 AuthGuard 代碼如下
import { Injectable } from '@angular/core';
import {
CanActivate, ActivatedRouteSnapshot, RouterStateSnapshot, UrlTree, Router, CanActivateChild, CanLoad, Route, UrlSegment
} from '@angular/router';
import { Observable } from 'rxjs';
@Injectable({
providedIn: 'root'
})
export class AuthGuard implements CanActivate, CanActivateChild, CanLoad {
/**
* ctor
* @param router 路由
*/
constructor(private router: Router) { }
canActivate(
next: ActivatedRouteSnapshot,
state: RouterStateSnapshot): Observable<boolean | UrlTree> | Promise<boolean | UrlTree> | boolean | UrlTree {
// 判斷是否有 token 信息
let token = localStorage.getItem('auth-token') || '';
if (token === '') {
this.router.navigate(['/login']);
return false;
}
// 判斷是否可以訪問當前連接
let url: string = state.url;
if (token.indexOf('admin') !== -1 && url.indexOf('/crisis-center') !== -1) {
return true;
}
this.router.navigate(['/login']);
return false;
}
canActivateChild(
childRoute: ActivatedRouteSnapshot,
state: RouterStateSnapshot): boolean | UrlTree | Observable<boolean | UrlTree> | Promise<boolean | UrlTree> {
let token = localStorage.getItem('auth-token') || '';
if (token === '') {
this.router.navigate(['/login']);
return false;
}
return token === 'admin-master';
}
canLoad(route: Route, segments: UrlSegment[]): boolean | Observable<boolean> | Promise<boolean> {
let token = localStorage.getItem('auth-token') || '';
if (token === '') {
this.router.navigate(['/login']);
return false;
}
let url = `/${route.path}`;
if (token.indexOf('admin') !== -1 && url.indexOf('/crisis-center') !== -1) {
return true;
}
}
}
同樣的,針對路由守衛的實現完成后,將需要使用到的路由守衛添加到 crisis-center 路由的 canLoad 數組中即可實現授權認證不通過時不加載模塊
import { HeroCanDeactivateGuard } from './hero-list/guards/hero-can-deactivate.guard';
import { NgModule } from '@angular/core';
import { Routes, RouterModule } from '@angular/router';
const routes: Routes = [
{
path: 'crisis-center',
loadChildren: () => import('./crisis/crisis.module').then(m => m.CrisisModule)
}
];
@NgModule({
imports: [RouterModule.forRoot(routes, { enableTracing: true })],
exports: [RouterModule],
})
export class AppRoutingModule { }
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
※智慧手機時代的來臨,RWD網頁設計為架站首選
網動結合了許多網際網路業界的菁英共同研發簡單易操作的架站工具,及時性的更新,為客戶創造出更多的網路商機。